Trong xử lý ngôn ngữ tự nhiên, n-gram là một chuỗi gồm n từ liên tiếp trong văn bản. Đây là một kỹ thuật đơn giản nhưng rất hiệu quả để trích xuất ngữ cảnh cục bộ từ văn bản.
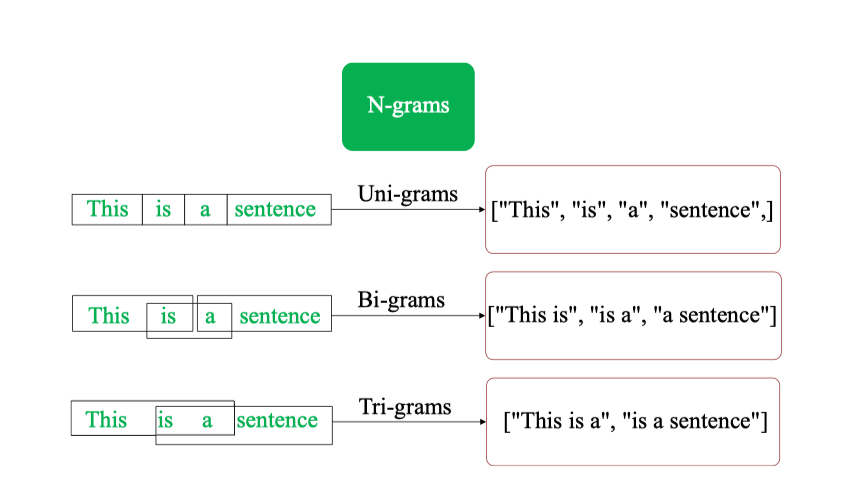
- Unigram (n = 1): Mỗi từ được coi là một đơn vị độc lập. List unigram thu được gồm: [“This“, “is“, “a“, “sentence“]
- Bigram (n = 2): Các cặp từ liên tiếp được gom lại thành một đơn vị. Cửa sổ trượt độ dài 2 sẽ tạo ra: [“This is“, “is a“, “a sentence“]
- Trigram (n = 3): Ba từ liên tiếp sẽ được kết hợp thành một cụm. Danh sách trigram là: [“This is a“, “is a sentence“]
Trong xử lý ngôn ngữ, việc phân tích từng từ riêng lẻ (unigram) thường không đủ để nắm bắt ý nghĩa hoặc ngữ cảnh của văn bản. n-gram giúp mô hình nhận diện các cụm từ có ý nghĩa như “New York“ hay “machine learning“, thay vì xem chúng là hai từ rời rạc. Nhờ đó, n-gram cung cấp một cách đơn giản nhưng hiệu quả để đưa ngữ cảnh ngắn hạn vào mô hình.
Các ứng dụng cụ thể của n-grams trong nlp gồm: • Phát hiện cụm từ có ý nghĩa (collocations): Ví dụ: “machine learning“, “deep learning“, “new year“,… Không thể tách rời. • Phân tích phong cách viết (author profiling): Tần suất xuất hiện của một số cụm từ là đặc trưng riêng biệt của từng người viết. Ví dụ, một tác giả có thể dùng nhiều “I think“ hoặc “In my opinion“ hơn người khác. • Bổ sung ngữ cảnh ngắn hạn: Thay vì chỉ biết “fox“ là một từ, mô hình biết rằng “quick brown fox“ là một chuỗi thường gặp - đây là cách đơn giản để đưa ngữ cảnh vào biểu diễn từ.