I. Tổng quan về Unix/Linux
1. Linux là gì và tại sao cần thiết?
Linux là một hệ điều hành mã nguồn mở, được phát triển lần đầu bởi Linus Torvalds vào năm 1991. Nó được xây dựng trên nền tảng của hệ điều hành Unix – vốn nổi tiếng vì sự ổn định và dùng trong tính toán hiệu suất cao. Điểm đặc biệt của Linux là:
- Mã nguồn mở: ai cũng có thể xem, sửa hoặc tùy chỉnh theo ý mình.
- Tùy biến cao: bạn có thể cấu hình nó theo nhu cầu của dự án.
- Truy cập toàn diện: quyền kiểm soát gần như tuyệt đối với hệ thống, nhất là khi bạn dùng dòng lệnh (command line).
- Hiệu suất cao:
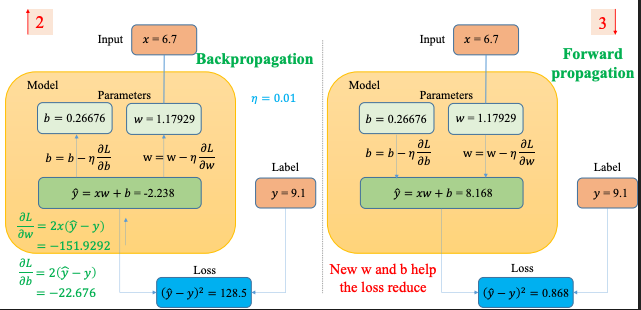
2. Các bản phân phối Linux phổ biến
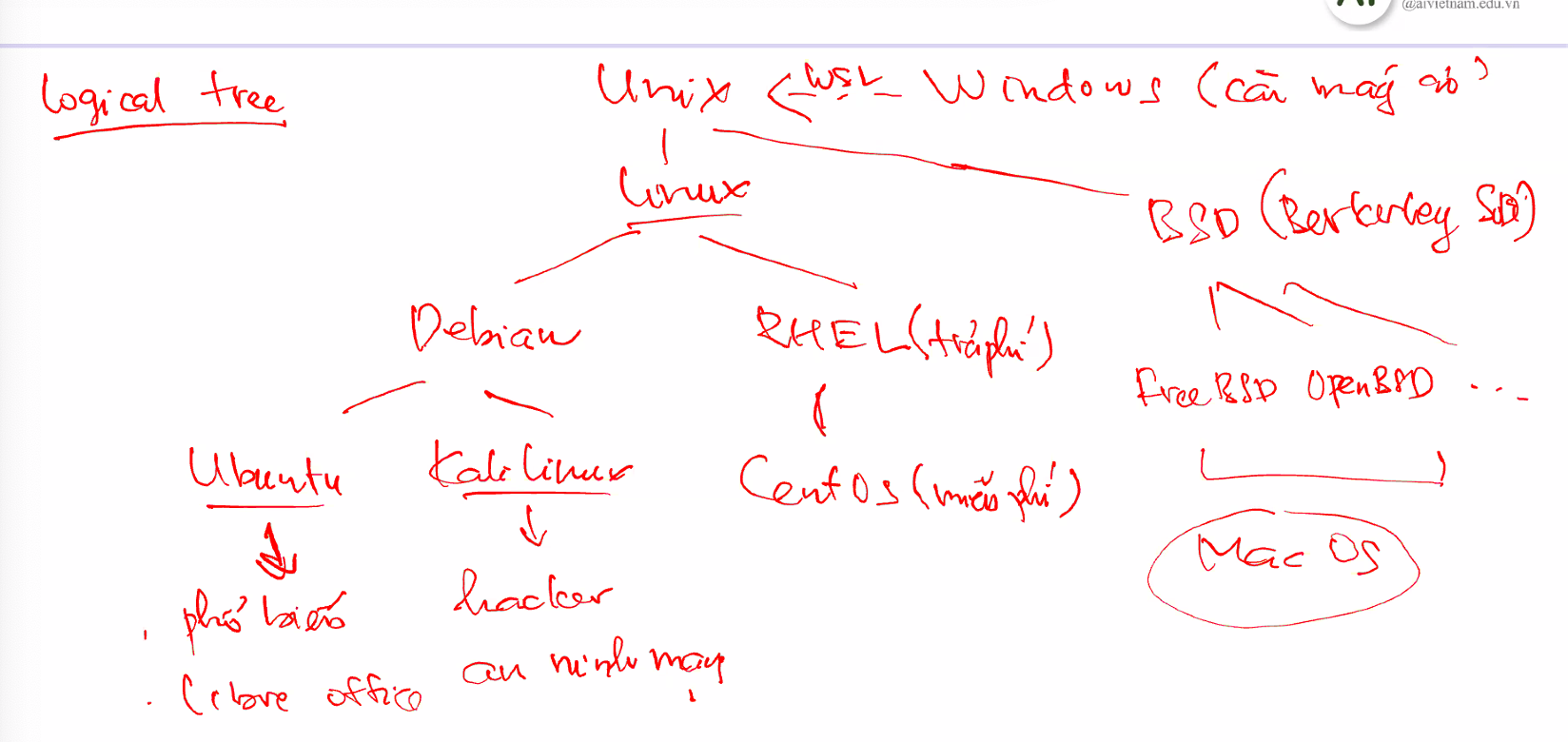
Linux không phải là một hệ điều hành duy nhất, mà là một nền tảng được phát triển thành nhiều bản phân phối (distribution) khác nhau. Mỗi bản phân phối có đặc điểm riêng, phục vụ các nhu cầu khác nhau – từ sử dụng cá nhân đến môi trường nghiên cứu hoặc doanh nghiệp.
Đối với những người làm việc trong lĩnh vực phân tích dữ liệu hoặc khoa học dữ liệu, việc lựa chọn bản phân phối phù hợp có thể giúp tăng hiệu suất làm việc, dễ tích hợp công cụ, và khai thác tối đa sức mạnh của hệ thống.
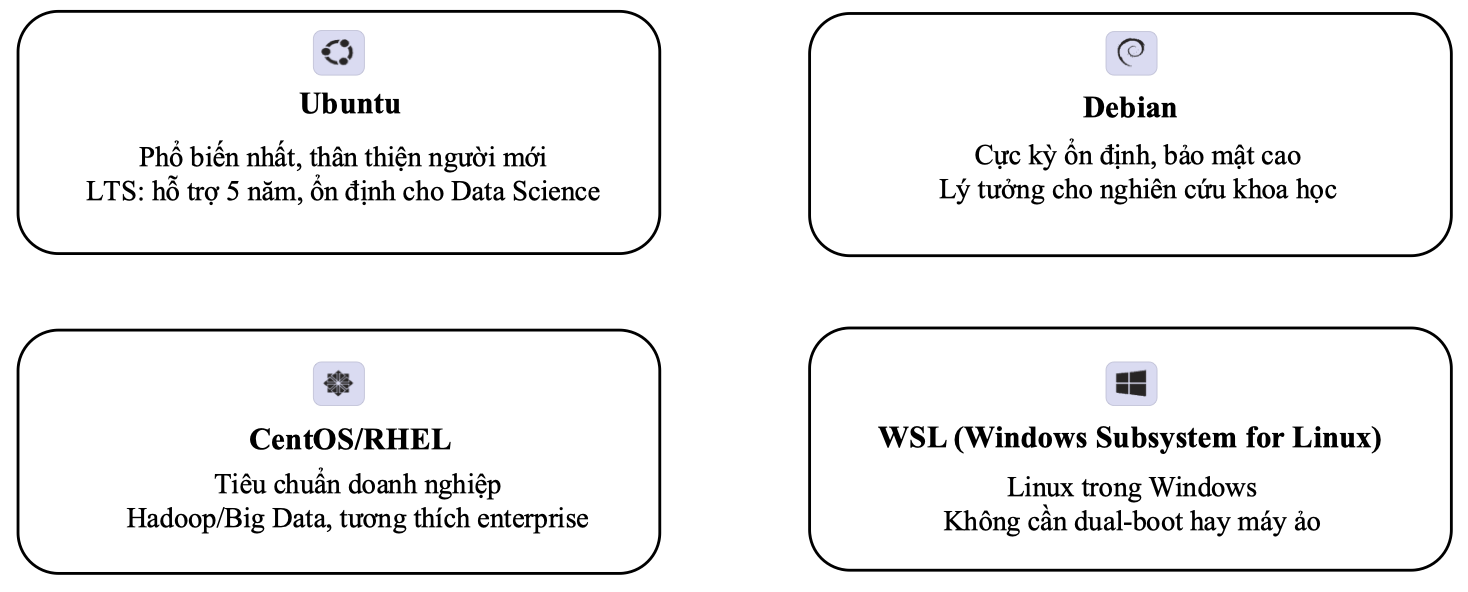
Ubuntu
Ubuntu là bản phân phối Linux được sử dụng rộng rãi nhất hiện nay. Điểm mạnh của Ubuntu là giao diện thân thiện, dễ tiếp cận với người dùng mới. Ngoài ra, Ubuntu có bản LTS (Long Term Support) được hỗ trợ tới 5 năm, rất phù hợp cho các môi trường cần tính ổn định cao. Ubuntu là lựa chọn lý tưởng cho:
- Người mới bắt đầu sử dụng Linux.
- Các dự án phân tích dữ liệu sử dụng Python, Jupyter, Pandas, v.v.
- Làm việc trên máy cá nhân hoặc máy chủ nhỏ.
Debian
Debian là một trong những bản phân phối lâu đời và được đánh giá cao về độ ổn định và bảo mật. Với chính sách cập nhật phần mềm cẩn trọng, Debian thường được sử dụng trong các hệ thống nghiên cứu khoa học hoặc server chạy dài hạn. Phù hợp với:
- Các nhà nghiên cứu, kỹ sư dữ liệu cần một môi trường tin cậy.
- Các hệ thống cần hoạt động ổn định trong thời gian dài.
- Những người đã có kinh nghiệm sử dụng Linux.
CentOS / RHEL
CentOS là bản phân phối dựa trên mã nguồn của Red Hat Enterprise Linux (RHEL), hướng đến môi trường doanh nghiệp. CentOS (và RHEL) thường được sử dụng trong các hệ thống xử lý dữ liệu lớn như Hadoop hoặc Spark, và rất tương thích với hạ tầng máy chủ nội bộ. Phù hợp với:
- Doanh nghiệp cần triển khai hệ thống ổn định, có thể mở rộng.
- Các dự án Big Data, hệ thống ETL, xử lý phân tán.
- Môi trường có yêu cầu tích hợp với các phần mềm doanh nghiệp.
WSL
Windows Subsystem for Linux (WSL) là một giải pháp của Microsoft cho phép người dùng chạy Linux trực tiếp trong Windows mà không cần cài máy ảo hoặc khởi động kép. Đây là giải pháp tiện lợi cho những ai đang dùng Windows nhưng cần môi trường dòng lệnh của Linux. Phù hợp với:
- Người dùng Windows muốn học hoặc thử nghiệm Linux.
- Các tác vụ nhẹ như viết script, chạy Python, quản lý môi trường ảo.
- Tích hợp nhanh với các công cụ phát triển mà không thay đổi hệ điều hành chính.
3. Triết lý Unix
Unix không chỉ là một hệ điều hành nền tảng cho Linux, mà còn là một triết lý thiết kế phần mềm. Triết lý Unix đặt trọng tâm vào sự đơn giản, chuyên biệt hóa, và tính nhất quán. Đây cũng là lý do khiến nhiều công cụ dòng lệnh trong Linux trở nên mạnh mẽ trong lĩnh vực xử lý và phân tích dữ liệu.

4. Shell là gì?
5. Cấu trúc thư mục trong Linux
II. Các lệnh cơ bản
1. Làm việc với files & thư mục
Lệnh điều hướng và quản lý thư mục
-
pwdHiển thị đường dẫn đầy đủ của thư mục hiện tại.
-
cd <thư_mục>Di chuyển giữa các thư mục.
cd ..lên thư mục cha,cd ~về home,cd ~/datasetsđến thư mục datasets. -
lsLiệt kê files/thư mục. Thêm
-lđể xem chi tiết,-ađể hiện file ẩn,-hsize dễ đọc,-Ssắp theo kích thước.ls -lahiện tất cả file kèm quyền, thời gian sửa, kích thước.
Tạo, sao chép, di chuyển, xóa file/thư mục
-
mkdir <thư_mục>Tạo thư mục mới. Thêm
-pđể tạo đa cấp (vd:mkdir -p project/data/raw). -
touch <file>Tạo file trống hoặc cập nhật thời gian sửa file.
touch {a,b,c}.txttạo nhanh nhiều file. -
cp <nguồn> <đích>Sao chép file. Thêm
-rđể sao chép cả thư mục. -
mv <nguồn> <đích>Di chuyển hoặc đổi tên file/thư mục.
-
rm <file>Xóa file.
rm -r <thư_mục>xóa thư mục và mọi thứ bên trong.rm -ixóa có xác nhận.
Xem nội dung file
-
cat <file>Hiện toàn bộ nội dung file (tránh dùng với file lớn).
-
less <file>Xem file theo trang, di chuyển bằng mũi tên,
/để tìm kiếm,qđể thoát. -
head -n <số_dòng> <file>Xem nhanh các dòng đầu file (mặc định 10 dòng).
-
tail -n <số_dòng> <file>Xem nhanh các dòng cuối file.
Tìm kiếm file và dữ liệu
-
find . -name "*.csv"Tìm tất cả file csv trong thư mục hiện tại và thư mục con.
-
find . -name "*.csv" -mtime -7Tìm file csv tạo hoặc sửa trong 7 ngày gần nhất.
-
grep "pattern" <file>Tìm dòng chứa từ khoá/pattern trong file.
grep -r "pattern" .tìm trong tất cả file thư mục hiện tại. -
wc -l <file>Đếm số dòng (record) trong file.
-
sort <file>Sắp xếp dữ liệu trong file.
-
uniqLọc hoặc đếm dòng trùng lặp (thường dùng sau sort).
Làm việc với file nén và tải dữ liệu
-
tar -czvf archive.tar.gz <thư_mục>Nén thư mục thành file .tar.gz.
-
tar -xzvf archive.tar.gz -C <thư_mục>Giải nén vào thư mục chỉ định.
-
zcat <file.gz>Đọc nội dung file nén mà không cần giải nén hoàn toàn.
-
wget <url>Tải file từ internet về máy.
-
curl -o <file> <url>Tải file, hoặc truy vấn API.
2. Thao tác text & chỉnh sửa
-
cut -d',' -f1,3-5 <file.csv>Lấy cột 1,3,4,5 từ file csv, dấu phân tách là dấu phẩy.
-
awk -F',' '{sum+=$3} END {print sum/NR}' <file>Tính trung bình cột 3 của file csv.
-
sed 's/old/new/g' <file>Thay thế tất cả chuỗi “old” thành “new” trong file.
-
tr ',' '\t' <file.csv> > <file.tsv>Đổi file csv thành tsv (phân tách tab).
-
jqXử lý file JSON (dùng riêng với dữ liệu JSON).
3. Quản lý môi trường và phân quyền
Quản lý process và phân quyền
-
ps aux | grep pythonXem tất cả process Python đang chạy.
-
topTheo dõi tài nguyên hệ thống (CPU, RAM…).
-
kill -9 <PID>Dừng process theo ID.
-
chmod 755 <file>Thay đổi quyền cho file (chạy script…).
-
chown user:group <file>Chuyển quyền sở hữu file.
III. Xử lý dữ liệu qua command line
1. Pipe Redirect
-
|(pipe): Kết nối đầu ra lệnh này thành đầu vào lệnh khác.VD:
cat data.csv | grep "2023" | sort | uniq -c > result.txt -
>Ghi đè output vào file.>>Thêm output vào cuối file. -
<Dùng file làm input cho lệnh.
2. Filter commands và trích xuất dữ liệu
3. Xử lý dữ liệu có cấu trúc
4. Kết hợp commands phức tạp
5. Xử lý song song với xargs
IV. Bài tập
Quiz
Câu hỏi 1: Thư mục /home trong cấu trúc thư mục Linux thường chứa gì? A. Các tệp nhị phân của hệ thống B. Dữ liệu người dùng C. Các tệp cấu hình hệ thống D. Dữ liệu biến đổi (log, cache)
Câu hỏi 2: Triết lý Unix “Mọi thứ đều là file” có ý nghĩa gì trong phân tích dữ liệu? A. Chỉ có thể xử lý dữ liệu được lưu dưới dạng file text. B. Dữ liệu, thiết bị và quy trình được xem như file, giúp tương tác thống nhất. C. Hệ thống chỉ cho phép đọc và ghi dữ liệu thông qua file. D. Các chương trình chỉ làm việc với file đơn giản.
Câu hỏi 3: Để tạo đồng thời tạo hai file trống khác train.csv và test.csv trong một lệnh duy nhất, bạn sẽ sử dụng lệnh nào? A. mkdir train.csv test.csv B. touch {train,test}.csv C. touch train,test.csv D. mkdir train,test.csv
Câu hỏi 4: Để tạo một cấu trúc thư mục đa cấp như projects/covid_analysis/raw_data chỉ với một lệnh duy nhất, bạn sẽ sử dụng tùy chọn nào với lệnh mkdir? A. mkdir -r B. mkdir -p C. mkdir -i D. mkdir -f
Câu hỏi 5: Trong Linux command line, ký tự | (pipe) được sử dụng với mục đích gì? A. Chuyển output của lệnh ra file. B. Hiển thị lỗi ra màn hình. C. Lấy input từ file thay vì bàn phím. D. Kết nối output của lệnh này với input của lệnh khác.
Câu hỏi 5: Lệnh awk thường được sử dụng để làm gì trong xử lý dữ liệu dạng văn bản? A. Thay thế văn bản và xử lý regex. B. Trích xuất cột hoặc ký tự từ dữ liệu có cấu trúc. C. Tìm kiếm và lọc dòng chứa mẫu cụ thể. D. Xử lý dữ liệu theo cột với ngôn ngữ lập trình hoàn chỉnh.