- I. Introduction
- II. Build UI using Streamlit
I. Introduction
1. Large Language Models (LLMs)
Chatbot là gì?
Chatbot là phần mềm mô phỏng cuộc trò chuyện với con người bằng ngôn ngữ tự nhiên, thông qua:
- Ứng dụng nhắn tin (Messenger, Zalo, Telegram…)
- Website
- Ứng dụng di động
- Cuộc gọi thoại (voicebot)
Mục tiêu: tự động hóa giao tiếp, giảm tải cho con người, cá nhân hóa trải nghiệm người dùng.
Các loại Chatbot phổ biến
Chatbot theo luật (Rule-based)
- Dựa vào luật “nếu – thì” (if-else) hoặc cây quyết định (decision tree).
- Không hiểu ngữ nghĩa, chỉ phản hồi theo kịch bản có sẵn. Ví dụ:
Người dùng nhấn “1” để hỏi giờ mở cửa → chatbot trả về khung giờ. Ưu điểm:
- Dễ xây dựng.
- Phù hợp với tác vụ đơn giản, ít thay đổi. 🔍 Hạn chế:
- Không linh hoạt, khó mở rộng.
- Không hiểu câu hỏi tự do. Chatbot sử dụng Machine Learning (ML-based)
- Học từ dữ liệu hội thoại.
- Sử dụng các mô hình như Naive Bayes, SVM, Decision Tree, hoặc Deep Learning. Ví dụ:
Chatbot phân loại câu hỏi theo ý định (intent) như: hỏi giá, hỏi tồn kho, khiếu nại… 🔍 Ưu điểm:
- Có thể hiểu nhiều cách diễn đạt.
- Tự động học từ dữ liệu. 🔍 Hạn chế:
- Cần tập dữ liệu huấn luyện.
- Dễ sai nếu không đủ dữ liệu. Chatbot dựa trên NLP và NLU
- Hiểu ngữ nghĩa và cấu trúc ngôn ngữ người dùng qua NLP (Natural Language Processing) và NLU (Natural Language Understanding). Ví dụ:
“Tôi muốn đặt vé từ Hà Nội đi Đà Nẵng vào thứ Bảy tuần sau.”
→ Chatbot phân tích ra: địa điểm, thời gian, hành động cần thực hiện. Ưu điểm:
- Giao tiếp linh hoạt như người thật.
- Có thể dùng trong lĩnh vực phức tạp (du lịch, ngân hàng, y tế). Chatbot dùng mô hình ngôn ngữ lớn (LLM-based / Generative)
- Dựa trên các mô hình như GPT, Claude, LLaMA…
- Có khả năng tạo câu trả lời mới thay vì chọn từ kịch bản sẵn có. 🔹 Ví dụ:
Chatbot trợ lý đọc tài liệu PDF, trả lời theo nội dung trong tài liệu (kết hợp với RAG). 🔍 Ưu điểm:
- Phản hồi linh hoạt, có thể trả lời nhiều chủ đề.
- Hiệu quả cao nếu tích hợp thêm hệ thống kiểm soát tri thức (RAG). 🔍 Hạn chế:
- Có thể “bịa” thông tin nếu không kiểm soát tốt.
- Yêu cầu tính toán cao, chi phí lớn hơn.
Large Language Model
LLM là một loại mô hình trí tuệ nhân tạo (AI) được huấn luyện trên khối lượng cực lớn dữ liệu văn bản (hàng trăm GB đến hàng trăm TB) để có thể hiểu và sinh ra ngôn ngữ tự nhiên (text) giống như con người. 1. Một số mô hình nổi tiếng:
| Mô hình | Tổ chức phát triển |
| GPT-4, GPT-3.5 | OpenAI |
| LLaMA | Meta (Facebook) |
| Claude | Anthropic |
| Gemini (Bard) | |
| Mistral, Falcon | Nhiều tổ chức khác |
| 2. LLM làm được gì? |
- Trả lời câu hỏi (Q&A)
- Viết văn bản, tóm tắt, dịch thuật
- Viết code, sửa lỗi code
- Chatbot, trợ lý ảo
- Phân tích sentiment, tạo nội dung marketing,…
- Tích hợp với RAG (Retrieval-Augmented Generation) để truy xuất dữ liệu thực tế 3. Cách hoạt động (cơ bản) LLM học dự đoán token tiếp theo trong chuỗi văn bản (kiểu như chơi đoán chữ), dựa trên kiến trúc Transformer. Quá trình huấn luyện bao gồm:
- Pre-training: học ngữ pháp, kiến thức tổng quát
- Fine-tuning: điều chỉnh theo nhiệm vụ cụ thể
- RLHF (Reinforcement Learning from Human Feedback): tinh chỉnh bằng phản hồi của con người 4. Ưu – Nhược điểm | | | |---|---| |Ưu điểm|Nhược điểm| |Hiểu ngôn ngữ rất tốt|Dễ bị “ảo tưởng” (hallucinate)| |Linh hoạt, ứng dụng đa nhiệm|Tốn tài nguyên (RAM/VRAM, compute)| |Có thể huấn luyện thêm theo domain|Có thể sinh nội dung sai, thiên vị| 5. LLM ≠ AI toàn năng LLM không có ý thức, không có trí tuệ thực sự – nó chỉ là mô hình xác suất dự đoán chữ tiếp theo dựa vào dữ liệu đã học.
Elements of a Prompt
Một Prompt gồm 4 thành phần chính:
| Thành phần | Mô tả | Ví dụ |
| 1. Task Description | Mô tả nhiệm vụ cần làm | ”This is a sentiment classifier.” |
| 2. Example(s) | Một vài ví dụ mẫu | ”Review: I loved this movie → Positive” |
| 3. Current Input | Đầu vào hiện tại | ”Review: I enjoyed the movie.” |
| 4. Output Indicator | Gợi ý vị trí model cần sinh đầu ra | ”This review is: ___” |
| 👉 Có thể là Zero-shot, One-shot, Few-shot tuỳ số lượng ví dụ mẫu trong prompt. | ||
| Ví dụ: Text Classification | ||
| Nhiệm vụ: phân loại cảm xúc đánh giá phim. |
TASK DESCRIPTION:
This is a movie review sentiment classifier.
EXAMPLE:
Review: I loved this movie!
This review is: Positive
CURRENT INPUT:
Review: I enjoyed the movie.
This review is: ___
→ Response: PositiveĐây là một few-shot prompt, với 1 ví dụ mẫu. Mẹo thiết kế Prompt tốt
- Viết rõ ràng nhiệm vụ.
- Cung cấp ví dụ đúng định dạng.
- Dẫn dắt mô hình bằng pattern lặp lại (review → sentiment).
- Giới hạn từ khóa cần sinh để tránh lan man.
Zero-shot và few-shot?
Zero shot learning**:**
- Không cung cấp bất kỳ ví dụ nào.
- Mô hình chỉ nhận một câu lệnh (prompt) mô tả nhiệm vụ. Few-shot learning:
- Cung cấp một vài ví dụ trong prompt (thường là 1–5).
- Giúp mô hình hiểu rõ hơn về ngữ cảnh, format hoặc logic cần thực hiện. | | | |---|---| |Dùng Zero-shot khi:|Dùng Few-shot khi:| |✅ Câu hỏi đơn giản, phổ quát|✅ Tác vụ phức tạp hoặc nhiều nghĩa| |✅ Mô hình đã được huấn luyện nhiều về dạng bài đó|✅ Cần hướng dẫn rõ ràng cách trả lời| |✅ Muốn tiết kiệm token (chi phí)|✅ Muốn tăng độ chính xác & định hướng| 🔹 Ví dụ:
- Zero-shot: “Translate ‘Xin chào’ to English.”
- Few-shot: “Viết tiêu đề bài báo hấp dẫn cho bài viết sau” (→ cần ví dụ mẫu để định hướng phong cách)
Giới thiệu mô hình Vicuna
Vicuna là một mô hình chatbot mã nguồn mở (open-source), được huấn luyện dựa trên nền tảng LLaMA (của Meta), kết hợp với kỹ thuật tinh chỉnh (fine-tuning) từ dữ liệu hội thoại thực tế.
🔥 Theo đánh giá nội bộ, Vicuna đạt khoảng 90% chất lượng ChatGPT (GPT-3.5), gây ấn tượng mạnh trong cộng đồng mã nguồn mở. Cấu trúc và điểm nổi bật:
- 🧠 Nền tảng: Dựa trên LLaMA-13B (phiên bản 13 tỷ tham số).
- 📚 Dữ liệu fine-tune: Lấy từ các hội thoại chất lượng cao trên ShareGPT.
- 💻 Open-source: Mã nguồn mở hoàn toàn → ai cũng có thể tải, sửa, và triển khai.
- 🌍 Triển khai dễ dàng: Hỗ trợ giao diện web, Colab notebook, và có thể tích hợp vào Streamlit. Hiệu quả & đánh giá:
- So sánh với GPT-3.5, Claude, Alpaca: Vicuna thể hiện khả năng trả lời sát nghĩa, sáng tạo và mạch lạc trong nhiều tình huống.
- Tuy nhiên, không mạnh bằng GPT-4, và cần GPU để chạy ổn định.
LLM Quantization
Quantization là kỹ thuật giảm độ chính xác của tham số trong mô hình từ dạng số thực 32-bit (FP32) xuống các dạng nhỏ hơn như 16-bit (FP16), 8-bit (INT8), thậm chí 4-bit.
🎯 Mục tiêu: giảm kích thước mô hình, tăng tốc độ suy luận (inference), tiết kiệm RAM và GPU.
Ví dụ: | | | | |---|---|---| |Kiểu dữ liệu|Dung lượng lưu trữ|Độ chính xác| |
FP32(float 32-bit)|Cao nhất (~1.0x)|Chuẩn| |FP16/BF16|~0.5x|Tốt| |INT8|~0.25x|Chấp nhận được| |INT4(4-bit)|~0.125x|Chỉ dùng inference (suy luận)|
Với LLaMA-13B:
-
Kích thước gốc FP32 ~ 52GB
-
Sau khi quantize INT4 → chỉ còn ~ 13GB
→ Chạy được trên máy tính cá nhân!
Tại sao cần Quantization?
-
Chạy mô hình lớn trên GPU nhỏ (thậm chí trên CPU).
-
Tăng tốc độ xử lý → inference nhanh hơn đến 3–5 lần.
-
Tiết kiệm năng lượng, đặc biệt với ứng dụng edge/IoT. Các loại Quantization phổ biến: | | | | |---|---|---| |Loại|Mô tả|Dùng khi nào?| |Post-training quantization (PTQ)|Giảm bit sau khi huấn luyện|Nhanh, đơn giản| |Quantization-aware training (QAT)|Huấn luyện mô hình ngay từ đầu với bit thấp|Chính xác hơn, tốn công hơn| |Dynamic vs Static Quantization|Theo thời điểm suy luận|Chọn theo ứng dụng cụ thể| Dùng LLM quantized như thế nào?
-
✅ Với mô hình open-source (Vicuna, LLaMA, Mistral…):
→ Dùng bản GGUF / GGML / GPTQ đã được quantize sẵn
→ Chạy bằng llama.cpp, text-generation-webui hoặc vllm
-
✅ Với PyTorch hoặc HuggingFace:
→ Dùng thư viện như
bitsandbytes,optimum,transformersđể tải mô hình dạng INT8/4
Ví dụ: Tải mô hình Vicuna-7B-v1.5 dạng 4-bit (quantized) để tiết kiệm RAM, phục vụ cho inference trên CPU hoặc GPU yếu (VRAM < 8GB).
Bước 1: Cấu hình quantization 4-bit với BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True, # Bật chế độ 4-bit
bnb_4bit_quant_type="nf4", # Dùng kỹ thuật quantization "nf4" (Normal Float 4)
bnb_4bit_use_double_quant=True, # Dùng 2 lớp quantization để giảm lỗi
bnb_4bit_compute_dtype=torch.bfloat16 # Dùng định dạng tính toán bfloat16 (hiệu suất cao hơn)
)Bước 2: Đặt tên mô hình Vicuna 7B
MODEL_NAME = "lmsys/vicuna-7b-v1.5"Bước 3: Load mô hình LLM với cấu hình trên
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=nf4_config, # Gắn cấu hình quantization
low_cpu_mem_usage=True # Tối ưu sử dụng CPU RAM khi load
)AutoModelForCausalLMlà class chuyên dùng để load các mô hình dạng sinh ngôn ngữ (causal language model).low_cpu_mem_usage=True: giảm RAM tiêu thụ khi load. Bước 4: Load tokenizer tương ứng
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)Bước 5: Tạo pipeline từ transformer
model_pipeline = pipeline(
"text-generation", # Tác vụ là sinh văn bản
model=model, # Mô hình Vicuna đã được load
tokenizer=tokenizer, # Tokenizer tương ứng
max_new_tokens=512, # Giới hạn số token sinh ra tối đa
pad_token_id=tokenizer.eos_token_id, # Token padding là token kết thúc
device_map="auto" # Tự động chọn CPU/GPU phù hợp
)Bước 6: Đóng gói pipeline để dùng trong hệ thống khác
llm = HuggingFacePipeline( pipeline=model_pipeline, )Test thử:
prompt = """
### A chat between a human and an assistant.
### Human:
Your task is to classify the sentiment of input text into one of three categories: positive, neutral, or negative. Here is an example:
Input: You're great.
Output:
### Assistant:
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
generated_ids = model.generate(**model_inputs)[0]
answer = tokenizer.decode(generated_ids, skip_special_tokens=True)
answer.split("\n")[-1]
# Output sẽ là:
'positive'Quantization có làm giảm chất lượng trả lời của LLM không? Bao nhiêu phần trăm?
Có, nhưng ít, nếu thực hiện đúng cách. | | |---| |Kiểu Quant| |FP16 → Gần như không thay đổi (~99–100%)| |INT8 → Giảm khoảng 1–3% độ chính xác| |INT4 → Giảm 5–15% hoặc hơn, tùy bài toán và mô hình| 📌 Quan trọng là:
- Mô hình càng lớn, càng chịu ảnh hưởng nhiều khi quantize quá thấp.
- Nếu dùng INT4 cho tác vụ phức tạp như viết văn bản dài, lập luận logic, chất lượng có thể giảm rõ rệt.
2. Retrieval-Augmented Generation (RAG)
Định nghĩa
RAG là phương pháp kết hợp giữa:
- Truy xuất thông tin (Retrieval): tìm tài liệu liên quan từ vector database dựa trên câu hỏi đầu vào.
- Sinh văn bản (Generation): dùng LLM (như GPT) để tạo ra câu trả lời dựa trên tài liệu vừa truy xuất được.
Mục tiêu: tăng độ chính xác, cập nhật và kiểm soát cho LLM trong môi trường thực tế.
Cơ chế hoạt động
-
Người dùng đặt câu hỏi
→ Ví dụ: “Tóm tắt chính sách bảo hiểm trong tài liệu này?”
-
Retriever lấy các đoạn văn bản có liên quan từ kho dữ liệu vector (FAISS, Pinecone…).
-
Generator (LLM) nhận prompt bao gồm câu hỏi + văn bản đã truy xuất
→ Tạo ra câu trả lời mới, có căn cứ từ dữ liệu thực tế.
Công thức đơn giản:
Ưu điểm của RAG
- Giảm ảo giác (hallucination) của mô hình LLM.
- Cập nhật được thông tin mới mà không cần huấn luyện lại mô hình.
- Minh bạch nguồn gốc thông tin (truy xuất được đoạn văn hỗ trợ).
3. Retriever
Mục tiêu là cho phép mô hình ngôn ngữ trả lời câu hỏi dựa trên nội dung tài liệu bằng cách:
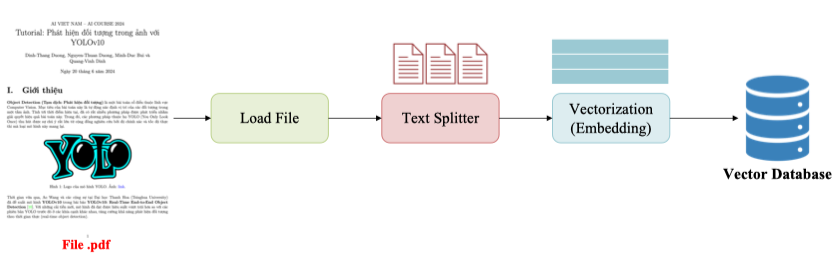
👉 Chuyển tài liệu thành dạng có thể truy xuất được (structured vector format) 📌 Công cụ hỗ trợ phổ biến: LangChain → Cho phép bạn load file, chia nhỏ, embedding, lưu vector chỉ với vài dòng code Python.
LangChain
LangChain là một framework Python giúp bạn xây dựng nhanh các ứng dụng dựa trên Large Language Models (LLMs) như GPT, LLaMA, Claude…
🎯 Mục tiêu: Đơn giản hóa toàn bộ vòng đời phát triển ứng dụng LLM: từ phát triển (development), triển khai (deployment) đến sản phẩm hóa (productionization). Các ứng dụng điển hình dùng LangChain | | | |---|---| |Ứng dụng|Mô tả| |Chatbot|Trò chuyện dựa trên dữ liệu hoặc API| |Agents|Tác tử thông minh biết gọi công cụ/phân tích nhiều bước| |Interacting with APIs|Kết nối, gọi và trích xuất dữ liệu từ REST/API khác| |Code Understanding|Phân tích, tóm tắt hoặc gợi ý sửa lỗi code| |Querying Tabular Data|Hỏi – đáp dựa trên bảng dữ liệu (CSV, SQL)| |Evaluation|Đánh giá chất lượng đầu ra của mô hình| |Extraction|Rút trích thông tin có cấu trúc từ văn bản (tên, ngày, địa điểm…)| |Q&A Using Documents|Trả lời dựa trên tài liệu – nền tảng của RAG| |Summarization|Tóm tắt báo cáo, bài viết, hợp đồng dài…|
Load a File
from langchain.document_loaders import PyPDFLoader
# Đặt alias để code ngắn gọn hơn
Loader = PyPDFLoader
# Đường dẫn tới file PDF
FILE_PATH = "./YOLOv10_Tutorials.pdf"
# Khởi tạo loader để đọc file
loader = Loader(FILE_PATH)
# Tải nội dung tài liệu (thường là từng trang của PDF)
documents = loader.load()
# In ra số lượng trang tài liệu đã trích xuất
print("Number of documents: ", len(documents))
# In nội dung của trang đầu tiên
print(documents[0])Text Splitter
Text Splitter có hai kĩ thuật là Fixed-size Chungking và Semantic Chunking
4. Vector Embeddings

- Fixed-size Chunking:
- Chia đều theo kích thước (số từ/token ký tự) cố định.
- Dễ implement, kiểm soát độ dài
- Nhược điểm là cắt ngang ý, mất ngữ cảnh
- Semantic Chunking:
- Chia theo ý nghĩa, nội dung logic
- Mỗi đoạn là 1 đoạn văn/ý trọn vẹn
- Giữ nguyên ý nghĩa, phù hợp cho LLM
- Khó thực hiện, cần tính toán embedding hoặc xử lý NLP
Ở đây dùng Semantic Chunking
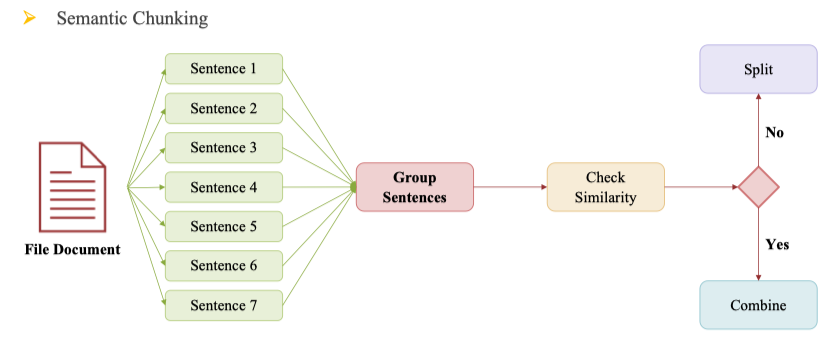
from langchain.text_splitter import SemanticChunker
# Khởi tạo semantic chunker
semantic_splitter = SemanticChunker(
embeddings=embeddings, # Bộ embedder đã khởi tạo từ OpenAI/BERT/...
buffer_size=1, # Nhóm 3 đoạn gần nhau để xét điểm ngắt
breakpoint_threshold_type="percentile", # Cách xác định điểm ngắt: theo phần trăm độ tương đồng
breakpoint_threshold_amount=95, # Nếu độ tương đồng thấp hơn 95 percentile thì cắt
# Các tuỳ chỉnh bổ sung (nếu dùng)
number_of_chunks=30, # Yêu cầu tối đa 30 đoạn semantic
min_chunk_size=500, # Mỗi đoạn ít nhất 500 ký tự
sentence_split_regex=r'(?<=[.?!…])\s+', # Regex chia theo câu (sau dấu câu)
add_start_index=True # Ghi nhớ vị trí bắt đầu trong văn bản gốc
)
# Thực hiện chia tài liệu thành các đoạn semantic
docs = semantic_splitter.split_documents(documents)
# In ra số lượng đoạn semantic
print("Number of semantic chunks: ", lEmbedding Model
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="bkai-foundation-models/vietnamese-bi-encoder"
)model_name="bkai-foundation-models/vietnamese-bi-encoder": Đây là mô hình được huấn luyện riêng cho tiếng Việt từ nhóm BKAI — phù hợp với semantic search hoặc phân tích văn bản tiếng Việt.
Ví dụ Retriever
# 1. Tạo vector database từ các đoạn semantic đã chunk
vector_db = Chroma.from_documents(
documents=docs,
embedding=embeddings
)
# 2. Chuyển vector DB thành Retriever
retriever = vector_db.as_retriever()
# 3. Đặt câu truy vấn tiếng Việt
QUERY = "YOLOv10 dùng để làm gì"
# 4. Thực hiện tìm kiếm semantic
result = retriever.invoke(QUERY)
# 5. In ra số lượng tài liệu liên quan
print("Number of relevant documents: ", len(result))
>> Number of relevant documents: 4Prompt
Tải một prompt mẫu có sẵn được thiết kế cho hệ thống hỏi đáp RAG, từ LangChain Hub — cụ thể là "rlm/rag-prompt".
from langchain import hub
# Tải prompt template từ LangChain Hub
prompt = hub.pull("rlm/rag-prompt")
# In ra nội dung prompt và các biến đầu vào
print(prompt)Toàn bộ quy trình (RAG Chain)
# 1. Tải prompt mẫu từ LangChain Hub
prompt = hub.pull("rlm/rag-prompt")
# 2. Hàm định dạng các documents thành một chuỗi văn bản ngăn cách bởi 2 dòng trống
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 3. Tạo chuỗi pipeline RAG chain
rag_chain = (
{
"context": retriever | format_docs, # Truy xuất tài liệu liên quan từ vector DB, rồi format lại
"question": RunnablePassthrough() # Giữ nguyên câu hỏi đầu vào
}
| prompt # Áp dụng template prompt
| llm # Gửi đến mô hình LLM (ví dụ OpenAI hoặc HuggingFace)
| StrOutputParser() # Parse output từ dạng object -> string
)
# 4. Câu hỏi của người dùng
USER_QUESTION = "YOLOv10 là gì?"
# 5. Gọi pipeline và in kết quả
output = rag_chain.invoke(USER_QUESTION)
print(output)