- Giới thiệu
- I. Aggregation Framework
- 1. Introduction to the Aggregation Pipeline
- 2. $mach
- 3. $project
- 4. Arthmetic Expression Operators
- 5. String Expression Operators
- 6. Date Expression Operators
- 7. Comparison Expression Operators
- 8. Array Expression Operators
- 9. Conditional Expression Operators
- 10. $addFields
- 11. Cursor Stages
- 12. $group
- [[#13-bucket-and-bucketauto|13. bucketAuto]]
- 14. $facet
- 15. $sortByCount
- 16. User Variables
- 17. System Variables
- II. Indexes
- III. MongoDB Drivers (Python)
- Summary
- Tham khảo
Giới thiệu
Ở phần đầu tiên của series NoSQL, chúng ta đã cùng nhau tìm hiểu về khái niệm NoSQL, bối cảnh ra đời cũng như lý do các hệ quản trị cơ sở dữ liệu truyền thống không còn đáp ứng đủ nhu cầu của thời đại dữ liệu lớn. Những điểm khác biệt quan trọng giữa NoSQL và SQL, các nhóm NoSQL phổ biến như document store, key-value, column-family hay graph đã được làm rõ. Đó là bước khởi động để bạn hình dung về “bản đồ” công nghệ lưu trữ hiện đại. Sang đến phần 2, hành trình sẽ trở nên thực tế và thú vị hơn khi chúng ta “bước chân” vào thế giới của MongoDB – nền tảng NoSQL phổ biến nhất hiện nay. Bạn sẽ được chứng kiến cách MongoDB xử lý và biến hóa dữ liệu mạnh mẽ thông qua Aggregation Framework, hiểu vì sao index lại đóng vai trò như “phép tăng tốc” thần kỳ cho truy vấn, cũng như biết cách thao tác dữ liệu trực tiếp bằng Python thông qua PyMongo. Đây chính là những kỹ năng then chốt để biến lý thuyết NoSQL thành những ứng dụng thực sự trong công việc và dự án cá nhân. Nếu bạn chưa từng đọc qua phần trước, hãy dành thời gian xem lại để nắm vững nền tảng trước khi đi sâu vào thế giới thực hành của MongoDB: M01W1.5_NoSQL 1 Nếu bạn đã sẵn sàng, hãy cùng khám phá Aggregation Framework – siêu năng lực giúp xử lý dữ liệu lớn của MongoDB.
I. Aggregation Framework
Khi mới bắt đầu với MongoDB, bạn thường sẽ sử dụng các truy vấn đơn giản bằng Mongo Query Language (MQL) để lọc, tìm kiếm hoặc lấy ra một số dữ liệu thỏa điều kiện nào đó. Điều này khá giống với việc bạn dùng Google Search để tìm một câu trả lời đơn giản: nhanh, tiện, nhưng đôi khi vẫn còn hạn chế. Tuy nhiên, thực tế công việc với dữ liệu thường không chỉ dừng ở việc lấy ra rồi xem. Sẽ có lúc bạn cần phân tích, tổng hợp, biến đổi dữ liệu thành dạng hoàn toàn mới để phục vụ báo cáo hoặc trực quan hóa. Lúc này, MongoDB đưa ra một công cụ mạnh mẽ hơn rất nhiều: Aggregation Framework.
1. Introduction to the Aggregation Pipeline
Hãy hình dung Aggregation Pipeline như một dây chuyền sản xuất, nơi mỗi giai đoạn (stage) sẽ xử lý và biến tấu dữ liệu theo một cách nhất định. Dữ liệu sẽ đi qua từng trạm (Stage 1, Stage 2, Stage 3, …), và kết quả của giai đoạn trước sẽ trở thành nguyên liệu cho giai đoạn tiếp theo. Bạn có thể lọc dữ liệu ở bước đầu tiên, tính toán hoặc tạo field mới ở bước tiếp theo, và cuối cùng là nhóm, tổng hợp hoặc sắp xếp kết quả ở bước cuối cùng. Cách làm này cực kỳ linh hoạt và hiệu quả, đặc biệt khi làm việc với dữ liệu lớn hoặc các phân tích phức tạp.
 Giả sử bạn cần trả lời câu hỏi: Trong số tất cả các công ty được thành lập từ năm 2005 đến 2010, mỗi ngành có bao nhiêu công ty? Nếu dùng SQL, bạn sẽ phải viết một câu truy vấn khá dài với nhiều điều kiện. Với MongoDB, bạn có thể giải quyết bằng Aggregation Pipeline – mỗi “stage” sẽ làm một công việc rõ ràng.
Quy trình này giống như một dây chuyền lọc và chế biến tài liệu:
Giả sử bạn cần trả lời câu hỏi: Trong số tất cả các công ty được thành lập từ năm 2005 đến 2010, mỗi ngành có bao nhiêu công ty? Nếu dùng SQL, bạn sẽ phải viết một câu truy vấn khá dài với nhiều điều kiện. Với MongoDB, bạn có thể giải quyết bằng Aggregation Pipeline – mỗi “stage” sẽ làm một công việc rõ ràng.
Quy trình này giống như một dây chuyền lọc và chế biến tài liệu:
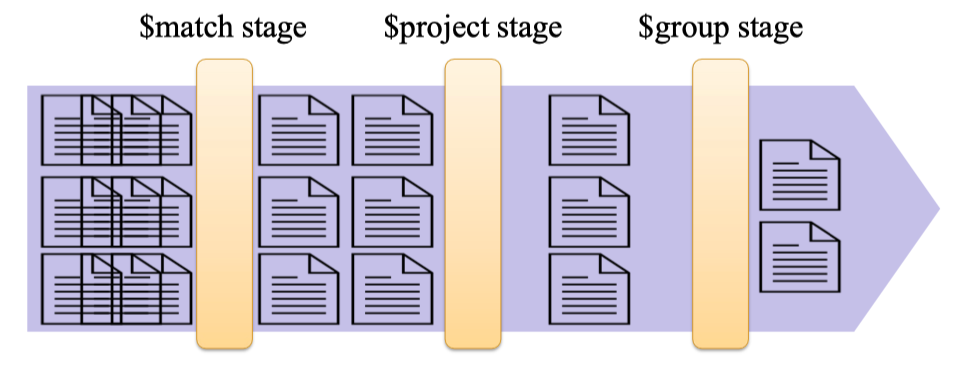 Bước đầu tiên là project stage, tại đây chỉ giữ lại các thông tin cần thiết như “category_code” để tránh dữ liệu thừa. Cuối cùng, mọi thứ được đưa tới $group stage, nơi các công ty được gom nhóm lại theo từng ngành và đếm số lượng thuộc mỗi nhóm.
Cứ như vậy, qua từng trạm kiểm soát, dữ liệu dần trở nên “sạch sẽ” và phù hợp với mục đích cuối cùng: chỉ còn lại danh sách các ngành cùng số lượng công ty tương ứng, đúng như yêu cầu của bài toán phân tích.
Đây cũng là sức mạnh nổi bật của Aggregation Pipeline – chia nhỏ bài toán lớn thành từng bước đơn giản, dễ kiểm soát và mở rộng.
Một ví dụ thực tế khác: Nếu bạn cần tổng hợp doanh số theo tháng, hãy tưởng tượng pipeline cũng sẽ có các stage: lọc đơn hàng theo thời gian, chỉ lấy trường cần thiết, rồi nhóm và tính tổng. Chính nhờ cách tư duy này mà việc xử lý dữ liệu lớn với MongoDB trở nên vừa linh hoạt vừa dễ “debug”.
Cú pháp tổng quát sử dụng Aggregation Pipeline:
Bước đầu tiên là project stage, tại đây chỉ giữ lại các thông tin cần thiết như “category_code” để tránh dữ liệu thừa. Cuối cùng, mọi thứ được đưa tới $group stage, nơi các công ty được gom nhóm lại theo từng ngành và đếm số lượng thuộc mỗi nhóm.
Cứ như vậy, qua từng trạm kiểm soát, dữ liệu dần trở nên “sạch sẽ” và phù hợp với mục đích cuối cùng: chỉ còn lại danh sách các ngành cùng số lượng công ty tương ứng, đúng như yêu cầu của bài toán phân tích.
Đây cũng là sức mạnh nổi bật của Aggregation Pipeline – chia nhỏ bài toán lớn thành từng bước đơn giản, dễ kiểm soát và mở rộng.
Một ví dụ thực tế khác: Nếu bạn cần tổng hợp doanh số theo tháng, hãy tưởng tượng pipeline cũng sẽ có các stage: lọc đơn hàng theo thời gian, chỉ lấy trường cần thiết, rồi nhóm và tính tổng. Chính nhờ cách tư duy này mà việc xử lý dữ liệu lớn với MongoDB trở nên vừa linh hoạt vừa dễ “debug”.
Cú pháp tổng quát sử dụng Aggregation Pipeline:
db.collection_name.aggregate(
[
{ stage 1 },
{ stage 2 },
...,
{ stage N }
],
{ options }
)Bạn sẽ truyền vào một mảng các stage (mỗi stage là một object đặc biệt, ví dụ như $match, $project, $group, v.v.), và MongoDB sẽ thực hiện lần lượt các bước đó trên dữ liệu của collection.
Điểm thú vị là bạn có thể sắp xếp các stage tùy ý, kết hợp linh hoạt để giải quyết hầu như mọi dạng bài toán xử lý dữ liệu. Nếu cần tối ưu, bạn có thể bổ sung thêm các tùy chọn (options) phía sau để kiểm soát kết quả trả về hoặc hiệu năng.
2. $mach
Trong một pipeline của MongoDB, match với điều kiện về trường "founded_year" như sau:
db.companies.aggregate([
{ $match: { "founded_year": { $gte: 2005, $lte: 2010 } } }
])Ngoài ra, bạn cũng có thể lọc bằng danh sách các giá trị cụ thể nhờ toán tử $in, ví dụ lọc theo từng năm:
db.companies.aggregate([
{ $match: { "founded_year": { $in: [2005, 2006, 2007, 2008, 2009, 2010] } } }
])Như vậy, $match không chỉ linh hoạt mà còn giúp bạn tối ưu hóa hiệu suất pipeline ngay từ bước đầu tiên, nhất là khi làm việc với những tập dữ liệu lớn.
3. $project
Sau khi dữ liệu đã đi qua $match và chỉ còn lại những bản ghi phù hợp, bạn sẽ thường cần lấy ra một vài trường cụ thể để sử dụng tiếp. Đây chính là nhiệm vụ của $project trong Aggregation Pipeline.
Lọc trường
Cơ chế hoạt động của $project khá đơn giản: nó “chuyển tiếp” những trường mà bạn yêu cầu sang cho các stage tiếp theo, đồng thời loại bỏ toàn bộ phần dữ liệu thừa không cần thiết. Bạn có thể hình dung giống như việc lấy một tờ hồ sơ và chỉ giữ lại các mục bạn quan tâm – những gì không quan trọng sẽ bị cắt bỏ ngay từ giai đoạn này.
 Ví dụ, nếu bạn chỉ muốn giữ lại trường
Ví dụ, nếu bạn chỉ muốn giữ lại trường "founded_year" và "category_code" của các công ty, cú pháp sẽ như sau:
db.companies.aggregate([
{ $project: { "founded_year": 1, "category_code": 1 } }
])Nếu kết hợp với $match để lọc các công ty thành lập từ 2005 đến 2010, sau đó chỉ giữ lại hai trường trên, pipeline sẽ như sau:
db.companies.aggregate([
{ $match: { "founded_year": { $gte: 2005, $lte: 2010 } } },
{ $project: { "founded_year": 1, "category_code": 1 } }
])Tạo trường mới
Ngoài việc loại bỏ các trường không cần thiết, $project còn cho phép bạn tạo mới trường dữ liệu ngay trong quá trình xử lý pipeline. Giả sử bạn muốn giữ lại trường number_of_employees và đồng thời tạo thêm một trường mới có tên no_of_employees, có giá trị y hệt:
db.companies.aggregate([
{
$project: {
"number_of_employees": 1,
"no_of_employees": "$number_of_employees"
}
}
])Kết quả trả về sẽ gồm cả hai trường, thuận tiện cho việc chuẩn hóa tên trường hoặc phục vụ các phép tính về sau.
Ứng dụng
Không chỉ dừng lại ở đó, $project còn có thể can thiệp sâu vào cấu trúc dữ liệu. Ví dụ, nếu trong một document chứa một field lồng nhiều lớp như địa chỉ, bạn hoàn toàn có thể “rút ruột” chỉ lấy ra giá trị tọa độ từ field “start station location” mà không cần giữ nguyên cấu trúc gốc. Điều này giúp dữ liệu trả về gọn gàng, dễ dùng, đặc biệt khi làm việc với dữ liệu địa lý hoặc các ứng dụng bản đồ.
Để kết hợp linh hoạt hơn, bạn có thể phối hợp $match và $project trong cùng một pipeline. Ví dụ, muốn lọc ra tất cả mã zip của thành phố HOUSTON có dân số trên 40.000, nhưng chỉ trả về hai trường “zip” và “pop”, bạn sẽ áp dụng $match trước để chọn đúng đối tượng, sau đó dùng $project để cấu hình trường dữ liệu cần hiển thị. Thậm chí, nếu muốn loại bỏ trường _id mặc định, chỉ cần đặt _id: 0 trong $project là xong.
db.zips.aggregate([
{
$match: {
"city": "HOUSTON",
"pop": { $gt: 40000 }
}
},
{
$project: {
"pop": 1,
"zip": 1,
"_id": 0
}
}
])Các ví dụ trên cho thấy, nếu biết tận dụng sức mạnh của $project, bạn có thể tùy biến dữ liệu đầu ra một cách cực kỳ linh hoạt, phục vụ tối ưu cho mọi nhu cầu phân tích và trình bày báo cáo.
4. Arthmetic Expression Operators
Toán tử số học – “Phép tính động” trong pipeline
Khi phân tích dữ liệu, nhu cầu tính toán, chuyển đổi số liệu là điều không thể thiếu. MongoDB cung cấp sẵn bộ toán tử số học cực kỳ mạnh mẽ trong Aggregation Pipeline, cho phép bạn thực hiện các phép cộng, trừ, nhân, chia, làm tròn… ngay khi dữ liệu đang đi qua các stage.
Bạn có thể sử dụng các toán tử như $add, $subtract, $multiply, $divide, $round và nhiều phép toán nâng cao hơn như lấy số tuyệt đối ($abs), làm tròn lên ($ceil), logarit ($log), căn bậc hai ($sqrt), chia lấy dư ($mod), hoặc luỹ thừa ($pow)…

 Cách dùng rất tự nhiên, ví dụ:
Nếu muốn chuyển số phút sang số giờ cho trường
Cách dùng rất tự nhiên, ví dụ:
Nếu muốn chuyển số phút sang số giờ cho trường tripduration và làm tròn đến 1 chữ số thập phân:
db.trips.aggregate([
{
$project: {
"tripduration": 1,
"tripduration_hrs": { $round: [ { $divide: [ "$tripduration", 60 ] }, 1 ] }
}
}
])Trong ví dụ trên, $divide giúp chia số phút cho 60 để ra số giờ, còn $round giúp làm tròn kết quả. Nếu muốn tính tổng hai trường hoặc nhân nhiều trường với nhau, chỉ cần thay toán tử tương ứng.
Đặc biệt, các phép toán này có thể lồng nhau, kết hợp với nhau trong một dòng pipeline. Bạn hoàn toàn có thể áp dụng các công thức động, như:
{ $add: [ "$field1", "$field2", 10 ] }
{ $multiply: [ "$price", "$quantity" ] }
{ $mod: [ "$score", 5 ] }
{ $sqrt: "$value" }Đôi khi, bạn cần thực hiện nhiều phép tính liên tiếp trên một trường dữ liệu. Ví dụ, nếu trường tripduration trong collection đang lưu số phút và bạn muốn chuyển thành số giờ với một chữ số thập phân, bạn có thể kết hợp hai toán tử $divide và $round ngay trong $project.
Cách làm như sau: đầu tiên, dùng $divide để chia giá trị "tripduration" cho 60, sau đó dùng $round để làm tròn kết quả đến một chữ số sau dấu phẩy. Toàn bộ quá trình này diễn ra trong một stage duy nhất, cực kỳ ngắn gọn và tối ưu.
db.trips.aggregate([
{
$project: {
"tripduration": 1,
"tripduration_hrs": { $round: [ { $divide: [ "$tripduration", 60 ] }, 1 ] }
}
}
])Kết quả trả về sẽ có cả trường tripduration (giữ nguyên giá trị phút) và trường tripduration_hrs (số giờ đã làm tròn), rất tiện cho việc báo cáo, hiển thị.
Toán tử số học trong pipeline sẽ giúp bạn xử lý, chuẩn hóa và phân tích dữ liệu trực tiếp mà không cần hậu xử lý ngoài, tiết kiệm rất nhiều thời gian so với thao tác truyền thống.
5. String Expression Operators
Không chỉ dừng lại ở các phép toán số học, MongoDB còn cung cấp một loạt các toán tử thao tác với kiểu chuỗi trong Aggregation Pipeline, cho phép bạn dễ dàng nối chuỗi, chuyển đổi chữ hoa/thường, kiểm tra hoặc trích xuất nội dung bằng biểu thức chính quy, và nhiều phép biến đổi nâng cao khác.
 Các toán tử thường gặp nhất là
Các toán tử thường gặp nhất là $concat, dùng để ghép nhiều trường hoặc giá trị lại thành một chuỗi hoàn chỉnh, và $toUpper, $toLower giúp chuyển đổi toàn bộ chuỗi sang chữ hoa hoặc chữ thường. Ví dụ, nếu muốn tạo một trường mới journey là sự kết hợp tên trạm đi và trạm đến, bạn có thể viết như sau:
db.trips.aggregate([
{
$project: {
"start station name": 1,
"end station name": 1,
"journey": { $concat: [ "$start station name", " - ", "$end station name" ] }
}
}
])Bên cạnh đó, các toán tử như $regexMatch cho phép bạn kiểm tra chuỗi theo biểu thức chính quy, rất hữu ích khi cần lọc dữ liệu chứa ký tự đặc biệt hoặc có định dạng nhất định. Ví dụ:
{ $regexMatch: { input: "$field", regex: "^A", options: "i" } }Bạn cũng có thể dùng các toán tử khác như $split để tách chuỗi, $substrBytes để lấy một đoạn con, $toString để ép kiểu, hoặc $dateToString để chuyển đổi ngày tháng sang định dạng text theo ý muốn.
6. Date Expression Operators
Khi dữ liệu của bạn liên quan đến ngày tháng – ví dụ giao dịch, đơn hàng, lịch sử truy cập – các toán tử ngày giờ của MongoDB sẽ trở thành công cụ cực kỳ mạnh trong pipeline. Nhóm Date Expression Operators cho phép bạn cộng trừ, chuyển đổi, trích xuất các phần của ngày, hoặc đo khoảng cách giữa hai mốc thời gian chỉ với một vài dòng code.
 Bạn có thể dùng
Bạn có thể dùng $dateAdd để cộng thêm một số ngày, tuần, tháng hoặc bất kỳ đơn vị thời gian nào vào một trường ngày đã có. Nếu muốn biết hai mốc thời gian cách nhau bao lâu, chỉ cần gọi $dateDiff và khai báo đơn vị mong muốn như ngày, giờ, phút… Thậm chí, việc lấy ra tháng, ngày, hoặc giờ từ một trường ngày cũng chỉ cần dùng toán tử $month, $dayOfMonth, $hour…
Ví dụ, để lấy ra số tháng từ trường "start time":
db.trips.aggregate([
{
$project: {
"start time": 1,
"month_no": { $month: "$start time" }
}
}
])Còn nếu muốn tính số ngày giữa hai trường ngày:
{
$project: {
days_between: {
$dateDiff: {
startDate: "$date1",
endDate: "$date2",
unit: "day"
}
}
}
}Ngoài ra, MongoDB còn cung cấp hàng loạt toán tử khác như $dateFromParts, $dateToString, $isoWeek, $dayOfWeek, $second… giúp bạn thao tác với dữ liệu thời gian linh hoạt như trên Excel nhưng lại hoàn toàn tự động và realtime.
7. Comparison Expression Operators
Khi cần lọc, đánh dấu hoặc kiểm tra dữ liệu theo điều kiện, các toán tử so sánh là công cụ không thể thiếu. MongoDB hỗ trợ đầy đủ các phép so sánh quen thuộc như lớn hơn ($gt), lớn hơn hoặc bằng ($gte), nhỏ hơn ($lt), nhỏ hơn hoặc bằng ($lte), bằng ($eq), khác ($ne), và phép so sánh ba chiều ($cmp).
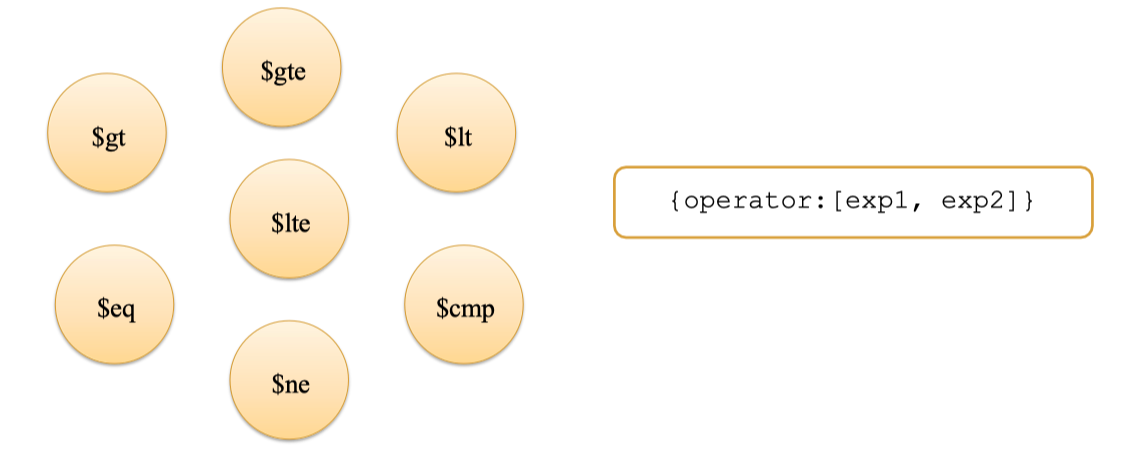 Có hai cách thường dùng để áp dụng toán tử so sánh:
Cách thứ nhất là dùng trực tiếp trong biểu thức filter kiểu
Có hai cách thường dùng để áp dụng toán tử so sánh:
Cách thứ nhất là dùng trực tiếp trong biểu thức filter kiểu { field: { $operator: value } }. Ví dụ, lọc các chuyến đi có thời gian trên 100 phút:
db.trips.aggregate([
{ $match: { "tripduration": { $gt: 100 } } }
])Cách thứ hai, mạnh mẽ hơn, là sử dụng biểu thức $expr khi bạn muốn so sánh hai trường dữ liệu hoặc biểu thức phức tạp. Ví dụ, đánh dấu (flag) tất cả các chuyến đi có thời gian lớn hơn 100 phút ngay trong quá trình $project:
db.trips.aggregate([
{
$project: {
"tripduration": 1,
"over100flag": { $gt: [ "$tripduration", 100 ] }
}
}
])Hoặc lọc những chuyến đi mà thời lượng lớn hơn 100 phút với $expr:
db.trips.aggregate([
{ $match: { $expr: { $gt: [ "$tripduration", 100 ] } } }
])Các toán tử so sánh cũng hỗ trợ những trường hợp phức tạp như so sánh giữa hai trường (ví dụ $gt: [ "$score1", "$score2" ]), hoặc so sánh nhiều giá trị trong cùng một bước pipeline. Khi kết hợp với các toán tử khác như $cond, $addFields, bạn hoàn toàn có thể xây dựng logic phức tạp, đánh dấu nhóm đặc biệt, hoặc xây dựng các “cờ” để phục vụ báo cáo.
Một lưu ý nhỏ: Nếu điều kiện của bạn chỉ so sánh trường với giá trị tĩnh, hãy dùng cú pháp trực tiếp để pipeline gọn nhẹ. Nếu cần so sánh động giữa hai trường hoặc nhiều biểu thức, $expr sẽ là lựa chọn bắt buộc.
8. Array Expression Operators
Dữ liệu dạng mảng (array) xuất hiện rất nhiều trong các ứng dụng thực tế, đặc biệt là khi bạn lưu trữ danh sách điểm số, lịch sử giao dịch, hoặc các tag liên quan đến một bản ghi. Aggregation Pipeline của MongoDB cung cấp một bộ toán tử mạnh mẽ để thao tác trực tiếp trên các trường mảng này.
Bạn có thể dùng $isArray để kiểm tra một trường có phải là mảng hay không, trả về kết quả dạng true/false rất tiện khi làm việc với dữ liệu không đồng nhất. Toán tử $size giúp đếm số phần tử trong một mảng, còn $first và $last cho phép lấy phần tử đầu hoặc cuối cùng của một mảng mà không cần phải viết code vòng lặp.
Nếu muốn kết hợp nhiều mảng lại thành một, chỉ cần dùng $concatArrays. Ngoài ra, MongoDB còn cung cấp các toán tử như $arrayElemAt để lấy phần tử tại vị trí bất kỳ, $slice để cắt một đoạn mảng, $in để kiểm tra sự xuất hiện của giá trị, $zip để “ghép đôi” hai mảng, hay $reverseArray để đảo ngược thứ tự các phần tử.
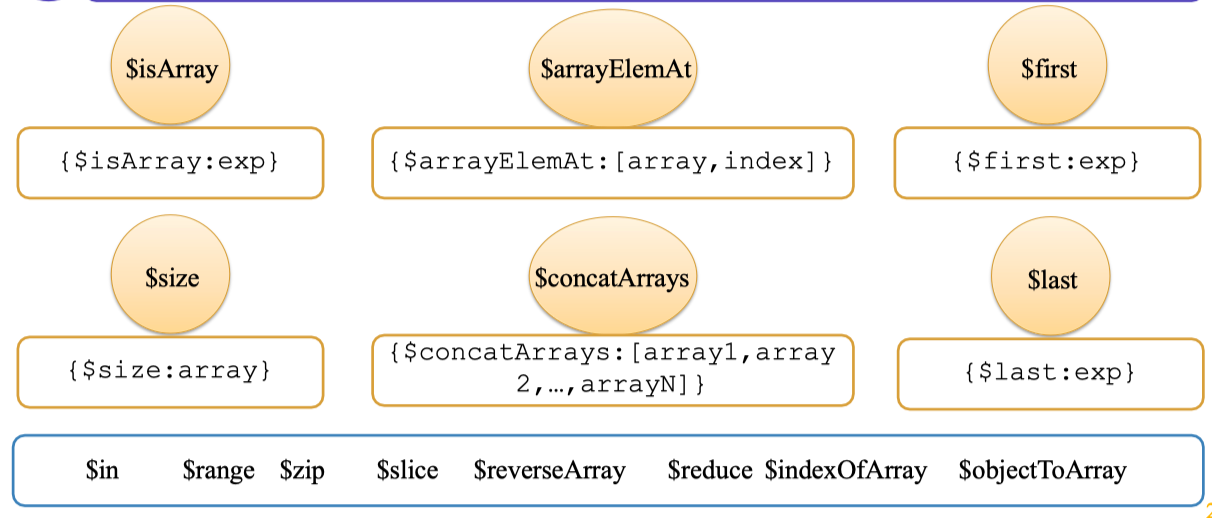 Ví dụ, kiểm tra trường
Ví dụ, kiểm tra trường scores có phải là mảng hay không:
db.grades.aggregate([
{
$project: {
"scores": 1,
"is_array": { $isArray: "$scores" }
}
}
])Hoặc lấy phần tử đầu tiên của mảng scores:
db.grades.aggregate([
{
$project: {
"first_element": { $first: "$scores" }
}
}
])Các toán tử này giúp việc xử lý dữ liệu dạng list trở nên gọn gàng, hiệu quả và đặc biệt phù hợp với dữ liệu thực tế ngày càng đa dạng, phức tạp.
9. Conditional Expression Operators
Trong thực tế phân tích dữ liệu, có rất nhiều trường hợp bạn cần sinh ra giá trị mới dựa trên điều kiện, giống như hàm IF trong Excel hay mệnh đề CASE WHEN trong SQL. Aggregation Pipeline của MongoDB cung cấp nhóm toán tử điều kiện cực kỳ linh hoạt: $cond, $ifNull, và $switch.
Toán tử $cond giúp bạn thực hiện câu lệnh “nếu-đúng-thì, nếu-không-thì” ngay trong pipeline. Cú pháp gồm ba phần: điều kiện, giá trị nếu đúng, giá trị nếu sai. Ví dụ, nếu muốn phân loại công ty dựa trên số nhân viên:
db.companies.aggregate([
{
$project: {
"number_of_employees": 1,
"size_employees": {
$cond: {
if: { $gt: [ "$number_of_employees", 1000 ] },
then: "large",
else: "not large"
}
}
}
}
])Toán tử $ifNull lại cực kỳ hữu ích khi bạn muốn thay thế giá trị null hoặc không tồn tại bằng một mặc định nào đó. Ví dụ, nếu number_of_employees bị thiếu sẽ trả về 0 thay thế:
db.companies.aggregate([
{
$project: {
"number_of_employees": { $ifNull: [ "$number_of_employees", 0 ] }
}
}
])Cuối cùng, $switch là lựa chọn tối ưu khi bạn cần nhiều nhánh điều kiện phức tạp (giống như nhiều CASE WHEN lồng nhau trong SQL). Bạn chỉ cần liệt kê các cặp điều kiện – kết quả, và một giá trị mặc định nếu không có nhánh nào khớp.
10. $addFields
Khi bạn muốn bổ sung thêm một trường mới cho mỗi document, nhưng không muốn thay đổi toàn bộ cấu trúc kết quả như $project, hãy dùng $addFields. Toán tử này cho phép bạn thêm một hoặc nhiều trường mới vào document gốc, giữ nguyên các trường còn lại, và hoàn toàn có thể gán giá trị bằng bất kỳ biểu thức toán học, chuỗi, ngày tháng, hoặc điều kiện nào bạn muốn.
Cách dùng $addFields cực kỳ trực quan, không cần dùng đến $expr như khi viết trong $project. Ví dụ, nếu bạn muốn tạo thêm trường tripduration_hrs bằng cách lấy giá trị tripduration chia cho 60 để chuyển phút thành giờ, chỉ cần viết như sau:
db.trips.aggregate([
{
$addFields: {
"tripduration_hrs": { $divide: [ "$tripduration", 60 ] }
}
}
])Kết quả trả về sẽ giữ nguyên toàn bộ document gốc, chỉ bổ sung thêm trường mới bạn vừa tính toán. Đây là điểm khác biệt lớn so với $project, vốn sẽ chỉ trả về những trường bạn liệt kê.
11. Cursor Stages
Khi pipeline đã xử lý xong các bước lọc, biến đổi và tổng hợp, bạn thường sẽ cần thêm các thao tác như sắp xếp, đếm số lượng, phân trang hoặc bỏ qua một số bản ghi. Những thao tác này được thực hiện thông qua nhóm cursor stages gồm: $sort, $count, $limit, $skip.
 Ví dụ, để sắp xếp danh sách các chuyến đi theo thời lượng giảm dần, chỉ cần dùng:
Ví dụ, để sắp xếp danh sách các chuyến đi theo thời lượng giảm dần, chỉ cần dùng:
db.trips.aggregate([
{ $sort: { "tripduration": -1 } }
])Nếu bạn chỉ muốn lấy hai bản ghi đầu tiên sau khi đã sắp xếp, hãy thêm $limit:
db.trips.aggregate([
{ $sort: { "tripduration": -1 } },
{ $limit: 2 }
])Để bỏ qua bản ghi đầu tiên và lấy hai bản ghi tiếp theo (phân trang), chỉ cần kết hợp thêm $skip:
db.trips.aggregate([
{ $sort: { "tripduration": -1 } },
{ $limit: 2 },
{ $skip: 1 }
])Khi cần đếm tổng số bản ghi sau một loạt các thao tác lọc, $count sẽ là lựa chọn cực kỳ gọn gàng. Ví dụ, đếm số chuyến đi có thời lượng trên 100 phút:
db.trips.aggregate([
{ $match: { "tripduration": { $gt: 100 } } },
{ $count: "total" }
])12. $group
Khi muốn tổng hợp, thống kê hay phân tích dữ liệu theo từng nhóm, stage $group là công cụ cốt lõi của Aggregation Pipeline. $group giúp gom các document lại thành từng nhóm dựa trên một biểu thức _id, và cho phép bạn thực hiện các phép toán tổng hợp như đếm, tính tổng, trung bình, giá trị lớn nhất, nhỏ nhất… trên từng nhóm này.
Cú pháp của $group gồm một object với _id là trường hoặc biểu thức bạn muốn nhóm theo, đi kèm các trường tổng hợp khác. Ví dụ, để đếm số lượng document của mỗi nhóm:
db.companies.aggregate([
{ $group: { "_id": "$category_code" } }
])Nếu muốn tính trung bình số nhân viên theo từng ngành, bạn chỉ cần bổ sung toán tử $avg:
db.companies.aggregate([
{
$group: {
"_id": "$category_code",
"avg_employees": { $avg: "$number_of_employees" }
}
}
])Bạn cũng có thể kết hợp $group với $sort để sắp xếp kết quả, ví dụ sắp xếp theo số nhân viên trung bình tăng dần:
db.companies.aggregate([
{
$group: {
"_id": "$category_code",
"avg_employees": { $avg: "$number_of_employees" }
}
},
{ $sort: { "avg_employees": 1 } }
])13. $bucket and $bucketAuto
Trong nhiều bài toán phân tích, bạn không chỉ muốn nhóm dữ liệu theo giá trị rời rạc mà còn muốn phân chia chúng thành các “khoảng” (bucket) – ví dụ, phân loại chuyến đi thành nhóm ngắn, trung bình, dài, hoặc chia khách hàng theo độ tuổi, thu nhập. MongoDB cung cấp hai stage mạnh mẽ cho nhu cầu này: bucketAuto.
$bucket
Với $bucket, bạn chủ động định nghĩa các mốc phân nhóm (boundaries) theo giá trị mong muốn. Mỗi document sẽ được phân vào đúng “xô” (bucket) tương ứng với khoảng giá trị chứa nó. Bạn cũng có thể quy định trường hợp nào rơi vào bucket “other” nếu nằm ngoài tất cả các khoảng đã khai báo.
Ví dụ, phân loại các chuyến đi dựa theo thời lượng:
db.trips.aggregate([
{
$bucket: {
groupBy: "$tripduration",
boundaries: [0, 100, 1000, 10000, 1000000]
}
}
])Nếu muốn thêm một nhóm đặc biệt “other” cho những chuyến đi vượt ngoài các khoảng này:
db.trips.aggregate([
{
$bucket: {
groupBy: "$tripduration",
boundaries: [0, 100, 1000, 10000],
default: "other"
}
}
])Ngoài ra, bạn có thể đính kèm các phép tổng hợp vào từng bucket bằng thuộc tính output để tính trung bình, đếm, tổng… cho từng khoảng giá trị.
Ví dụ, phân loại các chuyến đi thành từng nhóm thời lượng, đồng thời tính luôn số chuyến và thời lượng trung bình trong mỗi nhóm:
db.trips.aggregate([
{
$bucket: {
groupBy: "$tripduration",
boundaries: [0, 100, 1000, 10000],
default: "other",
output: {
"avg duration": { $avg: "$tripduration" },
"count": { $sum: 1 }
}
}
}
])Ở đây, mỗi bucket sẽ trả về hai thông tin: thời lượng trung bình và tổng số chuyến thuộc nhóm đó. Việc tổng hợp này giúp bạn lập báo cáo chi tiết mà không cần viết code xử lý ngoài, đặc biệt tiện lợi khi số lượng bản ghi rất lớn.
$bucketAuto
Trường hợp bạn không biết trước nên chọn mốc boundaries thế nào cho hợp lý, $bucketAuto sẽ tự động chia dữ liệu thành số nhóm bạn chỉ định sao cho các nhóm có số lượng bản ghi tương đương nhau.
Ví dụ, phân chia tự động tripduration thành 5 nhóm đều nhau về số lượng bản ghi và tính trung bình + số lượng bản ghi cho từng nhóm:
db.trips.aggregate([
{
$bucketAuto: {
groupBy: "$tripduration",
buckets: 5,
output: {
"avg duration": { $avg: "$tripduration" },
"count": { $sum: 1 }
}
}
}
])Kết quả trả về sẽ gồm 5 bucket, mỗi bucket thể hiện khoảng giá trị, số lượng record thuộc nhóm đó và giá trị trung bình của từng nhóm. Bạn hoàn toàn không cần phải xác định trước mốc boundaries, rất phù hợp khi dữ liệu phân phối không đều, hoặc bạn muốn chia đều cho mục đích trực quan hóa.
14. $facet
Khi bạn muốn xử lý cùng lúc nhiều phép tổng hợp, phân nhóm hoặc phân tích khác nhau trên cùng một tập dữ liệu đầu vào, thay vì chạy nhiều truy vấn độc lập rồi ghép kết quả lại, MongoDB cung cấp stage **facethoạt động như một “bản phân nhánh” – bạn định nghĩa các nhánh (mỗi nhánh là một pipeline riêng biệt với nhiều stage tuỳ ý), và kết quả trả về sẽ là một document duy nhất với từng nhánh là một trường con chứa mảng kết quả của pipeline đó. Ví dụ, bạn vừa muốn phân loại các chuyến đi thành bucket thủ công, vừa muốn tự động chia thành 5 nhóm bằng$bucketAuto` chỉ với một lệnh:
db.trips.aggregate([
{
$facet: {
"BucketManual": [
{
$bucket: {
groupBy: "$tripduration",
boundaries: [0, 100, 1000],
default: "other"
}
}
],
"BucketAuto": [
{
$bucketAuto: {
groupBy: "$tripduration",
buckets: 5
}
}
]
}
}
])Kết quả trả về sẽ gồm hai trường BucketManual và BucketAuto, mỗi trường chứa một mảng kết quả tương ứng với từng pipeline. Điều này đặc biệt mạnh mẽ khi bạn cần chuẩn bị nhiều dữ liệu thống kê hoặc so sánh nhiều kịch bản phân nhóm/phân khúc khác nhau trên dashboard, mà không phải thực hiện nhiều truy vấn tốn thời gian.
Một ứng dụng điển hình khác là kết hợp vừa phân nhóm, vừa thống kê tổng thể, vừa lấy các giá trị đặc biệt (top N, min/max…) chỉ trong một truy vấn, cực kỳ tối ưu cho các bài toán báo cáo hoặc trả dữ liệu về API tổng hợp.
15. $sortByCount
Khi bạn muốn vừa đếm số lượng document theo từng giá trị của một trường nào đó, vừa sắp xếp kết quả theo thứ tự giảm dần về số lượng, MongoDB cung cấp stage **group(để đếm số lượng theo nhóm) và$sort (để xếp hạng nhóm có số lượng nhiều nhất lên đầu), giúp bạn tiết kiệm rất nhiều dòng code. Ví dụ, muốn đếm số lượng từng loại người dùng (usertype) trong collection trips` và xếp loại nhiều nhất lên đầu, bạn chỉ cần:
db.trips.aggregate([
{ $sortByCount: "$usertype" }
])Cách làm thủ công tương đương sẽ là dùng $group để gom nhóm và đếm số lượng, rồi tiếp tục $sort kết quả theo trường count giảm dần:
db.trips.aggregate([
{ $group: { "_id": "$usertype", "count": { $sum: 1 } } },
{ $sort: { "count": -1 } }
])16. User Variables
Trong thực tế, các pipeline phức tạp thường bao gồm nhiều stage và dễ bị rối nếu viết trực tiếp mọi thứ vào hàm aggregate. Để tăng tính rõ ràng, tái sử dụng và kiểm soát pipeline, bạn có thể khai báo từng stage riêng lẻ thành các biến (user variables), sau đó ghép chúng lại thành một mảng stages khi gọi aggregate.
Ví dụ, bạn cần lọc các công ty thành lập trong giai đoạn 2005–2010, chỉ lấy trường category_code, rồi đếm và xếp hạng số lượng công ty theo từng ngành. Nếu viết trực tiếp, pipeline sẽ như sau:
db.companies.aggregate([
{ $match: { "founded_year": { $gte: 2005, $lte: 2010 } } },
{ $project: { "category_code": 1 } },
{ $sortByCount: "$category_code" }
])Nhưng nếu tách riêng từng bước, bạn sẽ có:
stage1 = { $match: { "founded_year": { $gte: 2005, $lte: 2010 } } }
stage2 = { $project: { "category_code": 1 } }
stage3 = { $sortByCount: "$category_code" }
db.companies.aggregate([ stage1, stage2, stage3 ])Việc này không chỉ giúp code của bạn dễ đọc, dễ debug hơn mà còn cho phép tái sử dụng từng stage ở nhiều pipeline khác nhau (ví dụ, chỉ thay đổi điều kiện lọc hoặc trường tổng hợp là xong).
17. System Variables
MongoDB cung cấp một số biến hệ thống (system variables) rất hữu ích, cho phép bạn truy xuất các thông tin động như thời gian hiện tại, thời gian ghi dữ liệu trên cluster, hoặc tham chiếu đến document gốc trong pipeline. Các biến này thường được dùng khi bạn cần gắn nhãn thời gian xử lý, kiểm tra thời điểm cập nhật, hoặc ghi log dữ liệu động mà không cần truy xuất thông tin ngoài. Một số biến hệ thống tiêu biểu:
$$NOW: Thời điểm hiện tại (theo server), rất thích hợp để ghi log, kiểm tra deadline, hay so sánh dữ liệu với thời gian thực.$$CLUSTER_TIME: Thời gian đồng bộ của cluster, đảm bảo mọi node đều nhất quán về mặt thời gian (đặc biệt hữu ích cho hệ thống phân tán).$$ROOT: Tham chiếu đến document gốc đang được xử lý trong pipeline. Ví dụ, khi muốn xuất ra dữ liệu điểm số của học sinh, kèm theo thời gian xử lý hiện tại và timestamp đồng bộ cluster, chỉ cần:
db.grades.aggregate([
{
$project: {
"student_id": 1,
"scores": 1,
"datetime": "$$NOW",
"timestamp": "$$CLUSTER_TIME"
}
}
])Nhờ các biến hệ thống này, bạn có thể xây dựng các pipeline “cập nhật theo thời gian thực”, đồng bộ hóa, kiểm tra chất lượng dữ liệu, hoặc tự động hóa việc log dữ liệu mà không cần xử lý ngoài. Điều này cực kỳ hữu ích khi triển khai các hệ thống báo cáo realtime, dashboard động, hoặc các luồng kiểm tra tự động trong môi trường lớn.
II. Indexes
1. Introduction to Indexes
Khi bạn tìm kiếm dữ liệu trong MongoDB mà không có chỉ mục, hệ thống buộc phải duyệt qua từng document trong collection để kiểm tra điều kiện, quá trình này gọi là COLLSCAN (collection scan). Hãy tưởng tượng bạn tìm một cuốn sách trong thư viện nhưng không có mục lục, bạn sẽ phải mở từng cuốn một – việc này cực kỳ tốn thời gian nếu dữ liệu lớn.
Ví dụ, câu lệnh:
 Nếu không có chỉ mục trên trường
Nếu không có chỉ mục trên trường name, MongoDB sẽ phải duyệt toàn bộ các document, kiểm tra từng bản ghi xem trường name có khớp với “Thai” hay không. Điều này không chỉ tốn thời gian mà còn tiêu tốn nhiều tài nguyên hệ thống, đặc biệt khi collection có hàng triệu bản ghi.
Chính vì vậy, indexes ra đời để giúp các truy vấn chạy hiệu quả hơn rất nhiều. Khi có index, MongoDB giống như có sẵn “mục lục” – chỉ cần tra nhanh là biết dữ liệu nằm ở đâu, không cần phải quét từng bản ghi như trước. Đây là nguyên tắc tối quan trọng để xây dựng các ứng dụng, dashboard, hệ thống báo cáo với hiệu suất cao trên nền tảng NoSQL.
Để thấy rõ sự khác biệt khi có chỉ mục (index), hãy hình dung MongoDB đã tạo một index trên trường name. Khi bạn thực hiện truy vấn như:
db.collection.find({ "name": "Thai" })thay vì phải duyệt qua toàn bộ các document trong collection, MongoDB sẽ tra cứu rất nhanh trên bảng chỉ mục – nơi lưu các giá trị đã được sắp xếp hoặc tổ chức tối ưu để tìm kiếm.
 Ví dụ, nếu index lưu các giá trị
Ví dụ, nếu index lưu các giá trị Hoa, Mai, Thai, khi bạn tìm "Thai", hệ thống chỉ cần lướt qua index, xác định vị trí đúng và ngay lập tức trả về document tương ứng. Nhờ vậy, tốc độ truy vấn tăng lên đáng kể, nhất là khi collection có hàng trăm nghìn hoặc hàng triệu bản ghi.
Bạn có thể hình dung index giống như bảng tra cứu trong sách giáo khoa: chỉ cần nhìn vào mục lục, bạn biết ngay trang nào chứa nội dung cần tìm, không cần phải lật từng trang như cách làm thủ công. Đó là lý do vì sao chỉ mục là thành phần không thể thiếu khi xây dựng các hệ thống dữ liệu hiệu suất cao.
Cấu trúc chỉ mục trong MongoDB
Khi tạo chỉ mục (index) trong MongoDB, dữ liệu chỉ mục sẽ được tổ chức dưới dạng một cây B-Tree (Balanced Tree), một cấu trúc dữ liệu cho phép truy xuất, tìm kiếm và chèn/xóa nhanh chóng ngay cả với lượng dữ liệu lớn. Mỗi node trong B-Tree chứa các khóa đã được sắp xếp, nhờ đó hệ thống có thể “rẽ nhánh” rất nhanh để đến được giá trị cần tìm thay vì phải duyệt tuần tự từng phần tử.
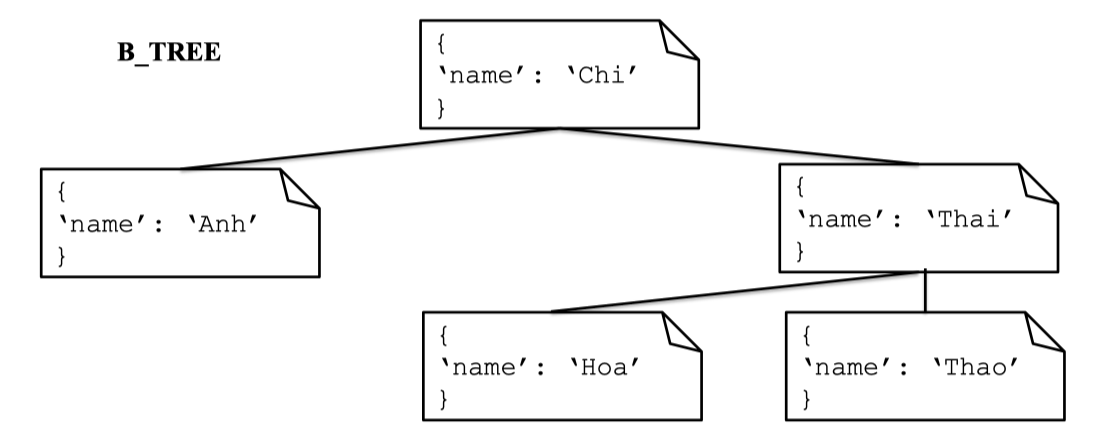 Ví dụ, một chỉ mục sắp xếp trên trường
Ví dụ, một chỉ mục sắp xếp trên trường name sẽ giúp việc tìm kiếm tên bất kỳ trở nên nhanh chóng, kể cả khi dữ liệu có hàng triệu dòng. Khi bạn tìm "Thai", hệ thống chỉ cần “đi” theo các nhánh đúng trong B-Tree là sẽ đến ngay document cần tìm.
Bạn có thể tạo chỉ mục đơn lẻ hoặc kết hợp nhiều trường (compound index) tuỳ ý, ví dụ:
db.collection.createIndex({
"first_name": 1, // Sắp xếp tăng dần
"last_name": -1 // Sắp xếp giảm dần
})Nếu cần xóa một chỉ mục không còn sử dụng nữa, chỉ cần gọi:
db.collection.dropIndex("last_name")Việc tận dụng B-Tree cho chỉ mục là lý do MongoDB giữ được hiệu suất cao kể cả khi dữ liệu phình to, giúp mọi thao tác tìm kiếm, lọc, sắp xếp đều sẽ nhanh chóng.
Đo hiệu suất truy vấn trong MongoDB
Bạn có thể đo đếm trực tiếp tác động của index lên hiệu suất truy vấn bằng cách so sánh kết quả .explain("executionStats") của cùng một truy vấn trước và sau khi tạo index.
Giả sử bạn muốn tìm tất cả công ty có số nhân viên lớn hơn 1000:
db.companies.aggregate([
{ $match: { "number_of_employees": { $gt: 1000 } } }
]).explain("executionStats")Khi chưa có index trên trường number_of_employees, MongoDB phải duyệt qua 9500 document (totalDocsExamined), chỉ để trả về 114 bản ghi đúng điều kiện. Thời gian thực thi mất 87 ms, toàn bộ quá trình này được gọi là COLLSCAN (Collection Scan) vì phải quét hết collection.
Khi bạn tạo index cho trường này:
db.companies.createIndex({ "number_of_employees": 1 })Cũng với truy vấn trên, nhưng giờ đây MongoDB chỉ cần kiểm tra đúng 114 document (bằng đúng số lượng cần trả về). Thời gian thực thi giảm mạnh còn 7 ms. Quá trình này được gọi là IXSCAN (Index Scan), tức là chỉ quét qua các entry trong index, không duyệt cả collection. So sánh trực tiếp hai trường hợp:
- Không có index: Quét toàn bộ dữ liệu (COLLSCAN), thời gian lâu, lãng phí tài nguyên.
- Có index: Chỉ quét phần nhỏ cần thiết (IXSCAN), tốc độ nhanh, tiết kiệm tài nguyên đáng kể. Đây là lý do vì sao index là “trợ thủ tốc độ” số 1 cho mọi truy vấn lớn trên MongoDB. Khi gặp một truy vấn chạy chậm, việc đầu tiên bạn nên làm là kiểm tra lại index, rất có thể chỉ cần bổ sung một chỉ mục đúng là hiệu năng cải thiện gấp nhiều lần.
2. Compound Indexes
Khi truy vấn của bạn thường xuyên cần kiểm tra nhiều trường cùng lúc, việc tạo chỉ mục kết hợp (compound index) sẽ giúp tăng tốc vượt trội so với chỉ mục đơn lẻ. Compound index cho phép MongoDB sắp xếp và tổ chức dữ liệu trên nhiều trường, từ đó tối ưu hóa các truy vấn lọc đồng thời.
Giả sử bạn muốn tìm bản ghi với điều kiện student_id = 1 và class_id = 329:
db.grades.find({ "student_id": 1, "class_id": 329 }).explain("executionStats")Nếu không có index, MongoDB phải quét toàn bộ 100.000 bản ghi để tìm ra 1 bản ghi đúng (COLLSCAN), thời gian thực thi kéo dài. Khi bạn tạo compound index:
db.grades.createIndex({ "student_id": 1, "class_id": 1 })Kết quả .explain() cho thấy MongoDB chỉ cần kiểm tra đúng 1 bản ghi, thời gian thực thi cực nhanh (IXSCAN).
Một điểm thú vị là chỉ mục kết hợp vẫn tối ưu cho truy vấn chỉ lọc theo trường đầu tiên trong index, ví dụ:
db.grades.find({ "student_id": 1 }).explain("executionStats")Ở đây, chỉ 10 bản ghi cần kiểm tra, quá trình cũng dùng IXSCAN, cực kỳ hiệu quả.
Tuy nhiên, nếu bạn truy vấn chỉ theo trường không phải đầu tiên trong chỉ mục (ví dụ chỉ class_id: 329), MongoDB lại phải COLLSCAN như trước, không tận dụng được index.
Điều này lý giải tại sao khi thiết kế chỉ mục kết hợp, bạn nên cân nhắc thứ tự các trường theo đúng nhu cầu truy vấn thực tế. Trường được lọc nhiều nhất hoặc quan trọng nhất nên đứng đầu trong key pattern của index.
3. Partial Indexes
Không phải lúc nào bạn cũng muốn tạo index cho toàn bộ dữ liệu. Trong nhiều trường hợp, chỉ một phần dữ liệu mới thực sự cần tối ưu hiệu suất truy vấn. Partial Index ra đời để giải quyết bài toán này: chỉ xây index cho những document thỏa mãn điều kiện nhất định (partialFilterExpression).
Ví dụ, nếu bạn chỉ quan tâm tối ưu truy vấn cho các chuyến đi có tripduration lớn hơn 100 phút, bạn có thể tạo partial index như sau:
db.trips.createIndex(
{ "tripduration": 1 },
{ partialFilterExpression: { "tripduration": { $gt: 100 } } }
)Lúc này, MongoDB chỉ xây index cho các bản ghi có tripduration > 100, tiết kiệm không gian lưu trữ index và giảm chi phí cập nhật khi ghi dữ liệu mới.
Khi bạn truy vấn các chuyến đi có thời lượng lớn hơn 150 phút:
db.trips.find({ "tripduration": { $gt: 150 } }).explain("executionStats")MongoDB có thể tận dụng index này để tìm kiếm rất nhanh (IXSCAN). Ngược lại, với truy vấn những bản ghi nhỏ hơn 100 phút:
db.trips.find({ "tripduration": { $lt: 100 } }).explain("executionStats")Lúc này index sẽ được dùng cho đúng phần dữ liệu có index (IXSCAN), còn lại sẽ thực hiện COLLSCAN như thường. Partial index cực kỳ hữu ích khi dữ liệu lớn nhưng chỉ có một phần nhỏ thường xuyên được truy vấn (ví dụ: đơn hàng trên một giá trị nhất định, khách hàng đặc biệt, dữ liệu còn hiệu lực…). Bạn sẽ tiết kiệm được tài nguyên hệ thống, đồng thời vẫn giữ được tốc độ truy vấn tối ưu cho những trường hợp cần nhanh chóng.
III. MongoDB Drivers (Python)
Một điểm mạnh lớn của MongoDB là khả năng kết nối linh hoạt với mọi nền tảng lập trình nhờ vào MongoDB Drivers. Bạn có thể truy cập, thao tác dữ liệu MongoDB từ các ứng dụng viết bằng Python, Java, C#, Node.js, Go, PHP, Ruby, Rust, TypeScript… Tất cả đều có driver chính thức, được cộng đồng hỗ trợ mạnh mẽ.
 Với Python – ngôn ngữ phổ biến trong khoa học dữ liệu, backend và tự động hóa – driver chuẩn là PyMongo. PyMongo là thư viện chính thức để các ứng dụng Python giao tiếp với MongoDB, thực hiện toàn bộ các thao tác CRUD: Create (tạo), Read (đọc), Update (cập nhật), Delete (xóa) dữ liệu.
Với Python – ngôn ngữ phổ biến trong khoa học dữ liệu, backend và tự động hóa – driver chuẩn là PyMongo. PyMongo là thư viện chính thức để các ứng dụng Python giao tiếp với MongoDB, thực hiện toàn bộ các thao tác CRUD: Create (tạo), Read (đọc), Update (cập nhật), Delete (xóa) dữ liệu.
 Một ứng dụng Python điển hình sẽ cài đặt PyMongo, kết nối tới MongoDB (trực tiếp hoặc thông qua nền tảng cloud như Atlas), từ đó có thể thêm, lấy, chỉnh sửa hoặc xóa dữ liệu, đồng thời khai thác mọi sức mạnh của Aggregation Pipeline, Index, Transactions… tương tự như khi thao tác trong shell MongoDB.
Việc kết nối này không chỉ dừng ở các ứng dụng backend mà còn mở rộng tới web, mobile, microservices, các ứng dụng AI/ML, và cả tích hợp cloud (Atlas, Stitch QueryAnywhere…). Đây là lý do MongoDB trở thành lựa chọn hàng đầu cho hệ thống đa nền tảng hiện đại.
Một ứng dụng Python điển hình sẽ cài đặt PyMongo, kết nối tới MongoDB (trực tiếp hoặc thông qua nền tảng cloud như Atlas), từ đó có thể thêm, lấy, chỉnh sửa hoặc xóa dữ liệu, đồng thời khai thác mọi sức mạnh của Aggregation Pipeline, Index, Transactions… tương tự như khi thao tác trong shell MongoDB.
Việc kết nối này không chỉ dừng ở các ứng dụng backend mà còn mở rộng tới web, mobile, microservices, các ứng dụng AI/ML, và cả tích hợp cloud (Atlas, Stitch QueryAnywhere…). Đây là lý do MongoDB trở thành lựa chọn hàng đầu cho hệ thống đa nền tảng hiện đại.
Summary
Chúng ta vừa đi qua một hành trình khám phá các tính năng thực tế của MongoDB – từ Aggregation Framework cho phép biến hóa, tổng hợp, phân tích dữ liệu theo mọi chiều, đến hệ thống Index mạnh mẽ giúp truy vấn dữ liệu lớn nhanh như chớp mắt. Bạn đã làm quen với cách thao tác, chuẩn hóa dữ liệu qua các stage như $match, $project, $group, $addFields, phân nhóm động với $bucket, $bucketAuto, chạy song song nhiều pipeline bằng $facet, cũng như cách tận dụng các toán tử số học, chuỗi, mảng và điều kiện trong quá trình xử lý.
Quan trọng hơn, bạn đã hiểu được vai trò của các loại index – từ single index, compound index cho tới partial index, và tận mắt thấy sức mạnh tối ưu hiệu suất mà index mang lại. Không chỉ dừng lại ở thao tác dữ liệu, bài viết còn hướng dẫn bạn cách kết nối MongoDB vào thực tế ứng dụng Python với PyMongo – cầu nối giúp các ý tưởng dữ liệu trở thành sản phẩm và báo cáo hữu ích.
Từ đây, bạn đã đủ công cụ để xử lý dữ liệu lớn, xây dựng báo cáo động, tự động hóa thao tác và mở rộng khả năng cho bất kỳ hệ thống nào cần lưu trữ và khai thác dữ liệu phi cấu trúc. Hãy thử áp dụng từng thao tác, từng pipeline vào chính dự án hoặc dữ liệu thực tế của bạn.
Tham khảo
Bài viết này dựa trên nội dung của bài giảng NoSQL 2 của khóa học AIO25 - Vinh Dinh Nguyen - PhD in Computer Science