Table of Content
- Tham khảo
- I. Giới thiệu cuộc thi (Introduction)
- 1. Hình thức và Luật thi (Format & Rules)
- 2. Các Bài Toán Chính (Problem Statement)
- Video Corpus Moment Retrieval (Bài toán truy xuất khoảnh khắc từ kho dữ liệu video)
- Interactive Track (Truy vấn – phản hồi liên tục với người dùng)
- Video QA (Question Answering) - Trả lời câu hỏi về nội dung video
- Known-Item Search (KIS) - Tìm kiếm một cảnh quay/đoạn phim cụ thể
- Visual Question Answering (VQA)
- II. Cách tiếp cận kỹ thuật (Pipeline & Methods)
- III. Software
Important
Tham khảo
![[M03W02.2_-HCMC_AI_Challenge(Buoi_1)_Slide_v2-HCMC_AI_2025.pdf]]
I. Giới thiệu cuộc thi (Introduction)
HCMC AI Challenge là sân chơi dành cho những người yêu thích trí tuệ nhân tạo, đặc biệt tập trung vào xây dựng trợ lý ảo thông minh để truy xuất thông tin từ kho dữ liệu đa phương tiện (ảnh, video, âm thanh, văn bản). Cuộc thi cập nhật đúng xu hướng mới nhất trên thế giới về các bài toán Video Corpus Moment Retrieval, Visual Question Answering và Known-Item Search. Câu hỏi gợi mở: Tại sao các bài toán này lại quan trọng trong bối cảnh AI hiện nay? Hãy thử tưởng tượng bạn có hàng ngàn giờ video và cần tìm đúng một khoảnh khắc đặc biệt – công nghệ nào giúp bạn làm điều đó trong vài giây thay vì vài ngày?
1. Hình thức và Luật thi (Format & Rules)
-
Cuộc thi có hai vòng: Vòng loại online và vòng chung kết onsite (các đội đến thi trực tiếp, xử lý truy vấn thời gian thực, kết quả chấm trên hiệu quả và tốc độ).
→ Nên chuẩn bị hết trước ở nhà (vòng online), để dùng trick
-
Được phép sử dụng mọi mô hình AI đã huấn luyện sẵn hoặc thương mại.
-
Có thể dùng máy tính cá nhân, không được dùng điện thoại trong vòng chung kết.
-
Ban tổ chức cung cấp một kho dữ liệu lớn (video, ảnh, âm thanh…), có thể dùng thêm embedding, website, keyframes mà BTC cho phép.
-
Không yêu cầu đào sâu vào nghiên cứu lý thuyết mà nhấn mạnh vào khả năng giải quyết thực tiễn nhanh chóng, kỹ năng teamwork, tự tin và chiến lược tìm kiếm. Ví dụ thực tế: Một đội phải tìm nhanh cảnh “một nhóm trẻ em đạp xe qua cầu Long Biên lúc hoàng hôn” trong hàng ngàn video.
2. Các Bài Toán Chính (Problem Statement)
Video Corpus Moment Retrieval (Bài toán truy xuất khoảnh khắc từ kho dữ liệu video)
Định nghĩa: Bạn có một kho video cực lớn (có thể hàng nghìn giờ phim, chương trình, video đời sống). Cho trước một truy vấn dưới dạng mô tả tự do (câu, đoạn văn), yêu cầu hệ thống AI tìm ra những khoảnh khắc chính xác (moment) trong tập video đó khớp nhất với mô tả, thường trả về danh sách top-K kết quả. Đầu vào:
- Query: câu hỏi/mô tả tự do (tiếng Anh hoặc Việt).
- Video Corpus: tập hợp video lớn, mỗi video có thể có ASR (transcript audio), metadata. Đầu ra:
- Danh sách các khoảnh khắc [(video_id, start_time, end_time, score)], với start/end là thời gian hoặc frame index trong video. Ví dụ thực tế: Bạn nhập truy vấn: “A man in a red shirt walks into a coffee shop and orders a drink”. Hệ thống phải trả về chính xác đoạn trong video nào có cảnh người đàn ông áo đỏ bước vào quán và gọi đồ, bất kể vị trí, thứ tự trong toàn bộ kho video. Câu hỏi đào sâu: Nếu chỉ có mô tả ngắn gọn (“a man enters a room”), làm sao AI phân biệt được khoảnh khắc đúng trong hàng chục video có nội dung tương tự? Các yếu tố như bối cảnh, hành động tiếp nối, đặc điểm nhận diện (màu áo, đồ vật, background) sẽ được AI xử lý như thế nào?
Interactive Track (Truy vấn – phản hồi liên tục với người dùng)
Định nghĩa: Không chỉ trả lời truy vấn một lần, hệ thống cần lặp lại quy trình:
- Trả về 1 khoảnh khắc dự đoán.
- Nhận phản hồi từ người dùng (liên quan/không, hoặc nhận xét chi tiết).
- Sử dụng feedback để đưa ra dự đoán mới, cho đến khi tìm ra moment đúng nhất. Câu hỏi gợi mở: Làm sao thiết kế thuật toán cập nhật kết quả theo phản hồi người dùng nhanh và thông minh nhất? Nếu user nói “not quite right, the man comes in from the left”, hệ thống sẽ chỉnh truy vấn hoặc reranking như thế nào? Ứng dụng thực tế: Tìm kiếm đoạn video phù hợp trong ngành truyền thông, giáo dục, kiểm duyệt nội dung, nơi con người thường phải xác nhận lại nhiều lần để chọn đúng.
Video QA (Question Answering) - Trả lời câu hỏi về nội dung video
Định nghĩa: Cho trước một video (có thể là clip hoặc cả bộ phim) và một câu hỏi bất kỳ liên quan đến nội dung video, yêu cầu hệ thống trả lời ngắn gọn và chính xác dựa trên thông tin trong video. Đầu vào:
- Video (file, url, hoặc trích xuất frame, audio,…)
- Question (tự do, thường là tiếng Anh) Đầu ra:
- Answer (span ngắn, thường là chuỗi text hoặc chọn từ danh sách đáp án đóng). Ví dụ:
- “What is the color of the car at 02:15 in the video?”
- “How many dogs are crossing the road in the scene?”
- “What is the name of the main character?” Câu hỏi mở rộng: Khi nào thì model sẽ thất bại? Ví dụ: câu hỏi cần ghép nối thông tin từ nhiều cảnh khác nhau, hoặc câu hỏi yêu cầu hiểu ngữ cảnh lịch sử của câu chuyện.
Known-Item Search (KIS) - Tìm kiếm một cảnh quay/đoạn phim cụ thể
Định nghĩa: KIS gồm hai dạng:
- Visual KIS (KIS-V): Cho người chơi xem một đoạn video ngắn (ví dụ 5-10s), yêu cầu tìm đúng vị trí đoạn này nằm ở đâu trong toàn bộ kho video.
- Textual KIS (KIS-T): Cho một mô tả bằng văn bản về đoạn cần tìm, yêu cầu xác định chính xác khoảnh khắc đó trong toàn bộ tập video. Dạng mở rộng (KIS-C): Ban đầu chỉ cung cấp thông tin rất hạn chế về cảnh cần tìm, các chi tiết bổ sung chỉ dần dần lộ ra dựa vào câu hỏi, tương tác từ người tham gia. Ví dụ thực tế:
- Visual: Xem một đoạn 10s cảnh “người phụ nữ đội nón lá dắt xe đạp qua cầu”, bạn phải tìm được đoạn này trong hơn 200 giờ video du lịch Việt Nam.
- Textual: Tìm đoạn “A dog jumps into a swimming pool at night” dựa trên mô tả, không xem trước hình ảnh. Câu hỏi gợi mở: Nếu bạn chỉ có mô tả rất chung chung, bạn sẽ xây dựng truy vấn như thế nào để thu hẹp tìm kiếm trong kho dữ liệu cực lớn?
Visual Question Answering (VQA)
Hỏi đáp sâu về video – yêu cầu phân tích hình ảnh, hành động, bối cảnh Định nghĩa: Người chơi đặt ra các câu hỏi chi tiết về video (thường khó hơn QA thông thường), yêu cầu AI trả lời đúng nhờ hiểu về cả hình ảnh, audio, chuỗi hành động. Ví dụ thực tế:
- “How many times does the scene change from day to night before this moment?”
- “What is the woman holding in her right hand when she enters the shop?” Câu hỏi mở rộng: Làm sao AI học được khái niệm “scene change”, “bối cảnh ngày/đêm”, hoặc xác định chính xác vật thể khi chỉ có một số frame bị mờ hoặc bị che khuất?
Đặc điểm tổng quát của các bài toán
- Đòi hỏi khả năng kết hợp trích xuất đặc trưng hình ảnh, xử lý ngôn ngữ tự nhiên, retrieval vector và thậm chí là kết hợp phản hồi con người (feedback).
- Tốc độ, độ chính xác, sự thông minh của pipeline quyết định thắng thua, bên cạnh yếu tố teamwork, may mắn và chiến lược vận hành hệ thống.
- Hệ thống cần tối ưu cả về tốc độ truy xuất (retrieval speed), hiệu quả bộ nhớ (storage), khả năng mở rộng, và tích hợp nhiều kỹ thuật như object detection, OCR, audio analysis, translation, reranking, temporal search.
Câu hỏi tổng hợp để tự đào sâu thêm
- Khi dữ liệu cực lớn, làm sao đánh đổi giữa tốc độ và độ chính xác khi truy xuất moment?
- Làm sao để hệ thống trả về top-K kết quả vẫn đảm bảo khoảnh khắc quan trọng không bị loại bỏ, đặc biệt khi moment rất ngắn?
- Khi người dùng nhập truy vấn bằng tiếng Việt, pipeline dịch, embedding, truy xuất sẽ được tối ưu ra sao?
- Phản hồi của người dùng (feedback loop) có thể được tích hợp vào model như thế nào để liên tục nâng cao hiệu quả retrieval?
II. Cách tiếp cận kỹ thuật (Pipeline & Methods)
1. Video-level retrieval
EDA
- Duration distribution (seconds)
- Frame rate (fps)
- Spatial resolution & aspect ratio
- Visual diversity (color entropy, object counts)
- Audio presence / bitrate (if relevant) g
- Metadata Analysis (weather, place,…)
- …..
Video Corpus Moment Retrieval = Video Retrieval + Boundary Shot Detection
Tìm kiếm đoạn video (moment) trong kho dữ liệu lớn phù hợp nhất với một truy vấn dạng tự nhiên (câu/đoạn mô tả sự kiện, hành động, tình huống). SOTA Video Retrieval (VR):
- GRAM: (https://openreview.net/pdf?id=ftGnpZrW7P)
- VideoRAG ( https://arxiv.org/pdf/2501.05874) SOTA Boundary Shot Detection (BSD):
- QCLPL (https://ieeexplore.ieee.org/document/10843770)
- PREM (https://arxiv.org/pdf/2402.13576) Video-level nghĩa là: Thay vì xử lý từng khung hình (image-level), hệ thống sẽ trích xuất đặc trưng (feature/embedding) đại diện cho toàn bộ video hoặc từng phân đoạn (shot, scene) lớn, dùng những đặc trưng này để thực hiện việc tìm kiếm và truy vấn. Phương pháp này phù hợp với các bài toán cần nhận diện nội dung hoặc xác định đoạn video phù hợp nhất với một mô tả tổng quát. Các pipeline hiện đại gồm:
- Encode toàn bộ video thành vector embedding.
- Dùng Vector Database (như FAISS) để truy xuất nhanh các video gần nhất với truy vấn.
- Sau đó dùng mô hình riêng cho moment retrieval (như QCLPL, PREM…) để xác định chính xác khoảnh khắc. Vấn đề gặp phải:
- Nếu video dài, moment ngắn thì khả năng khoảnh khắc cần tìm sẽ bị rank thấp trong top-K.
- Đòi hỏi tài nguyên máy tính lớn (nhiều RAM/GPU, lưu trữ hàng trăm GB dữ liệu).
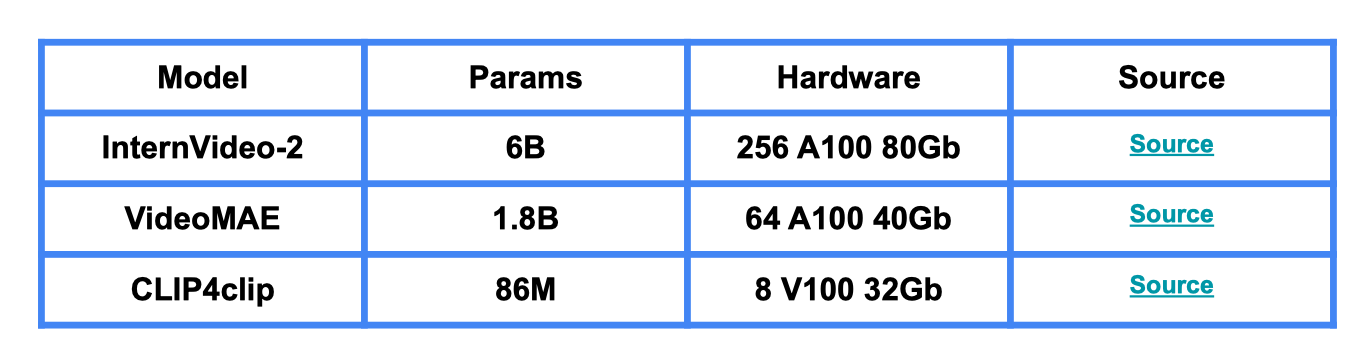
- Chúng ta cần phải lưu trữ dữ liệu rất lớn Câu hỏi đào sâu: Nếu hệ thống cần tìm một cảnh dài 5 giây trong một video dài 2 giờ thì phương pháp nào tối ưu nhất để không bỏ lỡ kết quả?
2. Image-level retrieval và Keyframe-based
- Tiền xử lý video thành các keyframe đại diện cho từng cảnh (scene).
- Tìm keyframe phù hợp nhất với truy vấn, sau đó quay lại xác định moment tương ứng. Lợi ích:
- Giảm tài nguyên tính toán và bộ nhớ (có thể giảm từ 500GB còn 80GB dữ liệu). Nhược điểm:
- Không giải quyết được các truy vấn có tính liên tục thời gian (temporal queries).
- Ví dụ: “A person enters the room and then sits next to the TV” cần theo dõi chuỗi sự kiện. Gợi mở: Làm sao để chọn keyframe tối ưu? Khi nào thì retrieval theo keyframe là đủ, khi nào cần tới moment retrieval?
Shot Boundary Model (SBD)
Shot Boundary Model (SBD) – mô hình phát hiện ranh giới cảnh trong video. Nó gồm nhiều khung hình (frames) được trích từ một bản tin dự báo thời tiết, hiển thị theo thứ tự thời gian:
- Hàng 1: Chuyển cảnh từ màn hình tiêu đề “Dự báo thời tiết” sang hình người dẫn chương trình và bản đồ.
- Hàng 2: Các khung hình liên tiếp khi người dẫn chương trình trình bày.
- Hàng 3: Tiếp tục các khung hình liên tiếp, sau đó chuyển sang một cảnh khác (có khung xanh/đen viền khác nhau báo hiệu ranh giới). Các đường viền màu (đen, xanh lá, xanh dương) có thể biểu thị:
- Viền xanh lá: khung hình đánh dấu cảnh mới bắt đầu (hard cut).
- Viền xanh dương: soft transition hoặc fade.
- Viền đen: các khung hình liên tục trong cùng một cảnh. Tham khảo: AutoShot: https://openaccess.thecvf.com/content/CVPR2023W/NAS/papers/Zhu_AutoShot_A_Short_Video_Dataset_and_State-of-the-Art_Shot_Boundary_Detection_CVPRW_2023_paper.pdf TransNetv2: https://arxiv.org/pdf/2008.04838 đây là hai phương pháp/mô hình phổ biến để phát hiện shot boundary.
Ví dụ sử dụng Transnetv2: Code: https://colab.research.google.com/drive/1nNkzYe3tq2AaCjXSEuyBp09Hu1u9Z7Hv?usp=sharing
import torch
from transnetv2_pytorch import TransNetV2
with torch.no_grad():
# video có dạng: batch_size x num_frames x height x width x RGB_channels
video_torch = torch.from_numpy(video) # ví dụ: torch.Size([4113, 227, 48, 3])
# Chuyển tensor sang dạng batch (thêm chiều batch) và đưa lên GPU
single_frame_pred, all_frame_pred = model(video_torch.unsqueeze(0).cuda())
# Kết quả dự đoán cho từng frame
single_frame_pred = torch.sigmoid(single_frame_pred).cpu().numpy()
# Kết quả dự đoán cho toàn bộ video (một mảng nhiều-hot cho các cảnh)
all_frame_pred = torch.sigmoid(all_frame_pred["many_hot"]).cpu().numpy()Ý nghĩa các biến:
video: dữ liệu video đã load sẵn và convert sang RGB (không phải BGR).single_frame_pred: xác suất cho từng frame có phải là cảnh chuyển tiếp hay không.all_frame_pred["many_hot"]: mảng nhị phân đánh dấu toàn bộ các frame nằm trong một shot..unsqueeze(0): thêm chiều batch vào dữ liệu để phù hợp input model..cuda(): chạy trên GPU để tăng tốc. Đây là tiền xử lý video trước khi đưa vào SBD:
import time
start_time = time.time()
video_stream, err = ffmpeg.input(video_path).output(
"pipe:", # xuất ra luồng dữ liệu (pipe) thay vì file
format="rawvideo", # định dạng video thô
pix_fmt="rgb24", # ảnh màu 3 kênh RGB
s="48x27" # resize khung hình về 48x27 pixel
).run(capture_stdout=True, capture_stderr=True)
video = np.frombuffer(video_stream, np.uint8).reshape(
[-1, INPUT_HEIGHT, INPUT_WIDTH, 3] # số frame x cao x rộng x 3 kênh
)
end_time = time.time()
print(end_time - start_time)Ý nghĩa các bước:
- Bắt đầu đo thời gian để biết quá trình load video mất bao lâu.
**ffmpeg.input(video_path)**: mở video từ đường dẫn.**.output(...).run()**:- Xuất video thô dạng
rawvideovới kênh màuRGB(không phải BGR). - Resize video về kích thước nhỏ (
48x27) để tăng tốc độ xử lý. - Kết quả trả về ở dạng
byte stream.
- Xuất video thô dạng
**np.frombuffer(...)**:- Chuyển byte stream thành mảng NumPy kiểu
uint8. - Reshape thành tensor 4D:
(num_frames, height, width, 3).
- Chuyển byte stream thành mảng NumPy kiểu
- In ra thời gian thực thi (ví dụ ~6.73 giây trong ảnh).
Keyframe selection
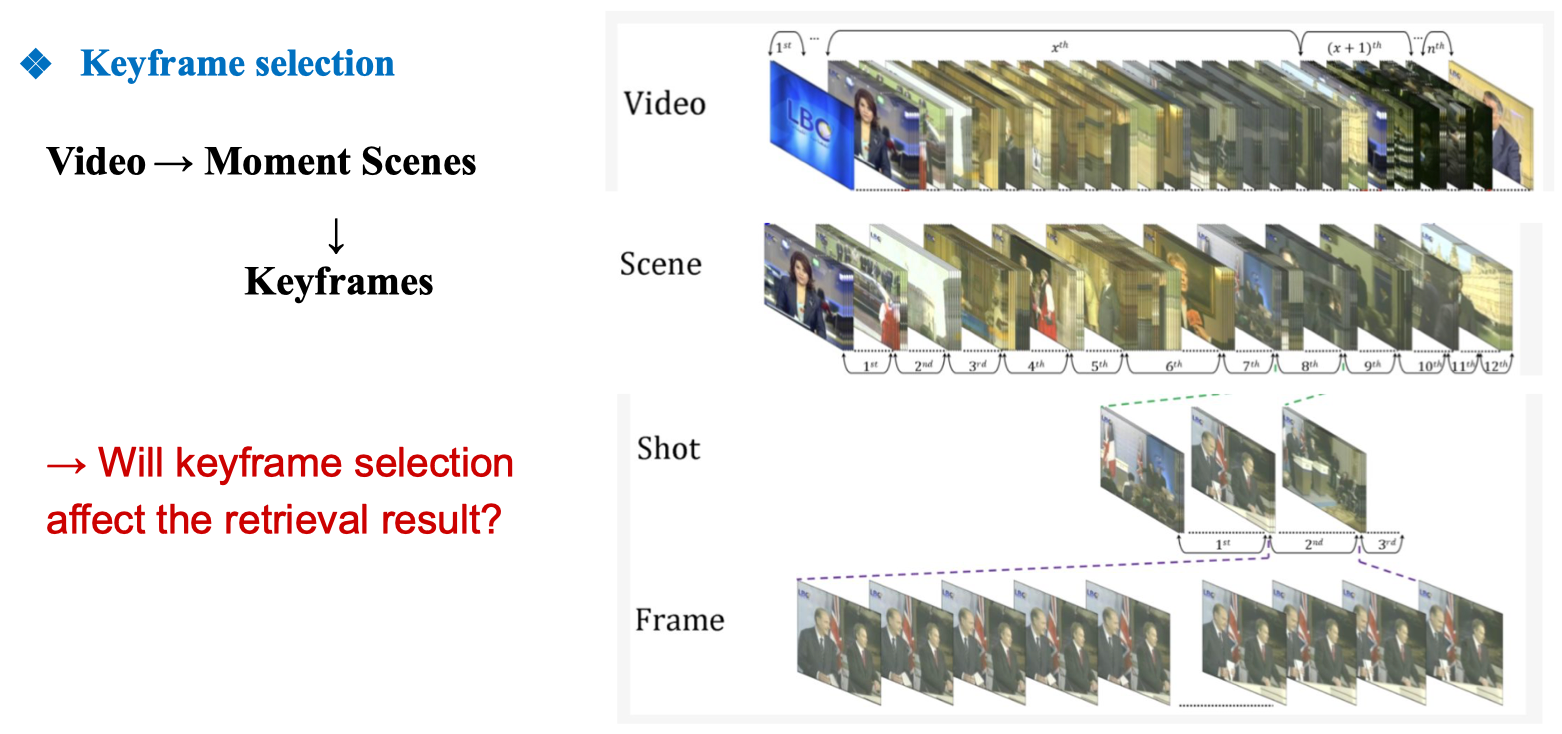
- Video: Chuỗi đầy đủ các frame theo thời gian.
- Scene: Video được chia thành nhiều cảnh (scene) dựa trên kết quả Shot Boundary Detection.
- Shot: Mỗi cảnh có thể gồm nhiều shot – các đoạn liên tục không có sự thay đổi cảnh đột ngột.
- Frame: Bên trong mỗi shot có nhiều frame liên tiếp.
- Keyframes: Từ các frame, ta chọn ra một hoặc vài frame tiêu biểu (đại diện cho toàn bộ shot/scene).
Việc chọn frame nào làm keyframe có ảnh hưởng đến kết quả truy vấn/tìm kiếm video (video retrieval) hay không?
- Nếu chọn keyframe không tiêu biểu hoặc bị mờ/nhiễu, khả năng khớp nội dung sẽ giảm.
- Nếu chọn keyframe tiêu biểu, mô hình retrieval sẽ có nhiều khả năng trả về kết quả chính xác hơn. Code: https://colab.research.google.com/drive/1CnfoC9E7zx4Kgy-vs2AgL3iD7OAF4ExY?usp=sharing
Temporal search
Mục tiêu (TARGET):
- Tìm một chuỗi keyframe mà:
- Đầu tiên khớp với first query
- Sau đó khớp với second query
- Cả hai xảy ra trong một khoảng thời gian cụ thể (specific time range).
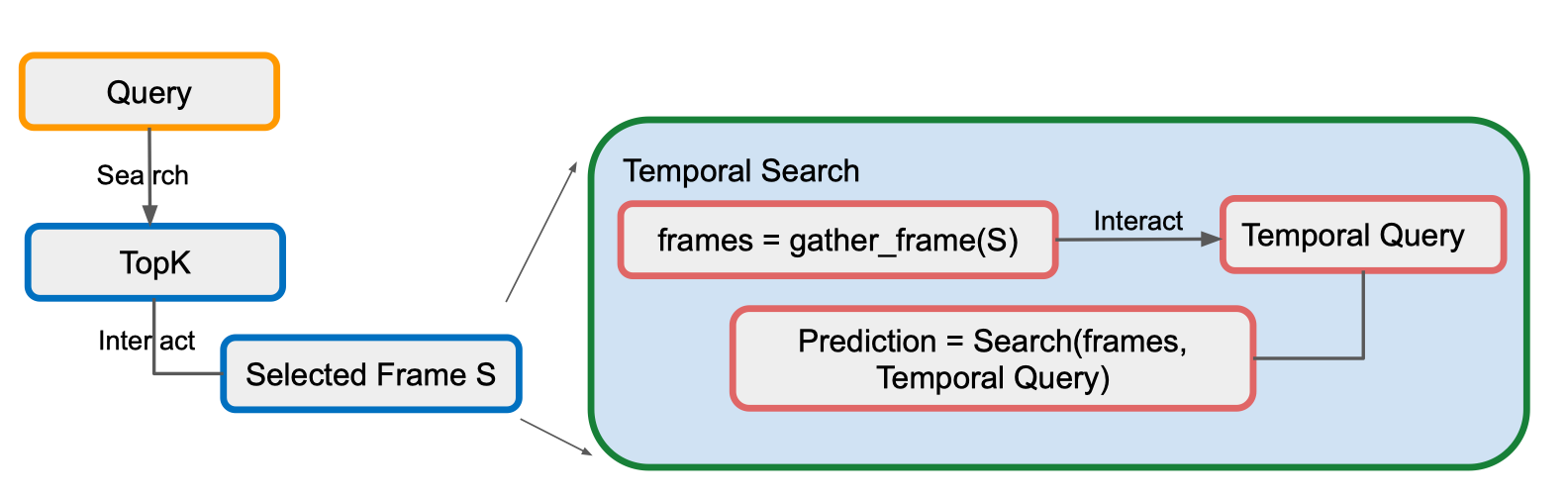 Quy trình minh họa:
Quy trình minh họa:
- Query ban đầu
- Người dùng đưa vào một truy vấn (Query).
- Hệ thống tìm ra TopK kết quả khớp nhất.
- Chọn frame S
- Người dùng chọn một frame hoặc segment cụ thể (Selected Frame S) từ danh sách TopK.
- Temporal Search
- frames = gather_frame(S): lấy tất cả các frame xung quanh frame S (có thể là một scene hoặc khoảng thời gian nhất định).
- Temporal Query: người dùng đưa ra một truy vấn thứ hai liên quan đến khoảng thời gian đó.
- Prediction = Search(frames, Temporal Query): hệ thống tìm kiếm trong tập frame vừa lấy, kiểm tra sự xuất hiện của pattern/truy vấn thứ hai, đồng thời đảm bảo trình tự và khoảng thời gian giữa 2 truy vấn đúng yêu cầu.
 Tham khảo: Efficient Search and Browsing of Large-Scale Video Collections with Vibro https://www.researchgate.net/publication/359223361_Efficient_Search_and_Browsing_of_Large-Scale_Video_Collections_with_Vibro
Ví dụ:
Tham khảo: Efficient Search and Browsing of Large-Scale Video Collections with Vibro https://www.researchgate.net/publication/359223361_Efficient_Search_and_Browsing_of_Large-Scale_Video_Collections_with_Vibro
Ví dụ:

- Phân tách câu truy vấn thành các sub-query (hoặc “events”).
- Tìm moment scenes tương ứng với từng phần.
- Đảm bảo thứ tự thời gian giữa các scene phù hợp với câu truy vấn gốc.
- Có thể đặt thêm time constraint — ví dụ hai cảnh phải cách nhau không quá X giây/phút.
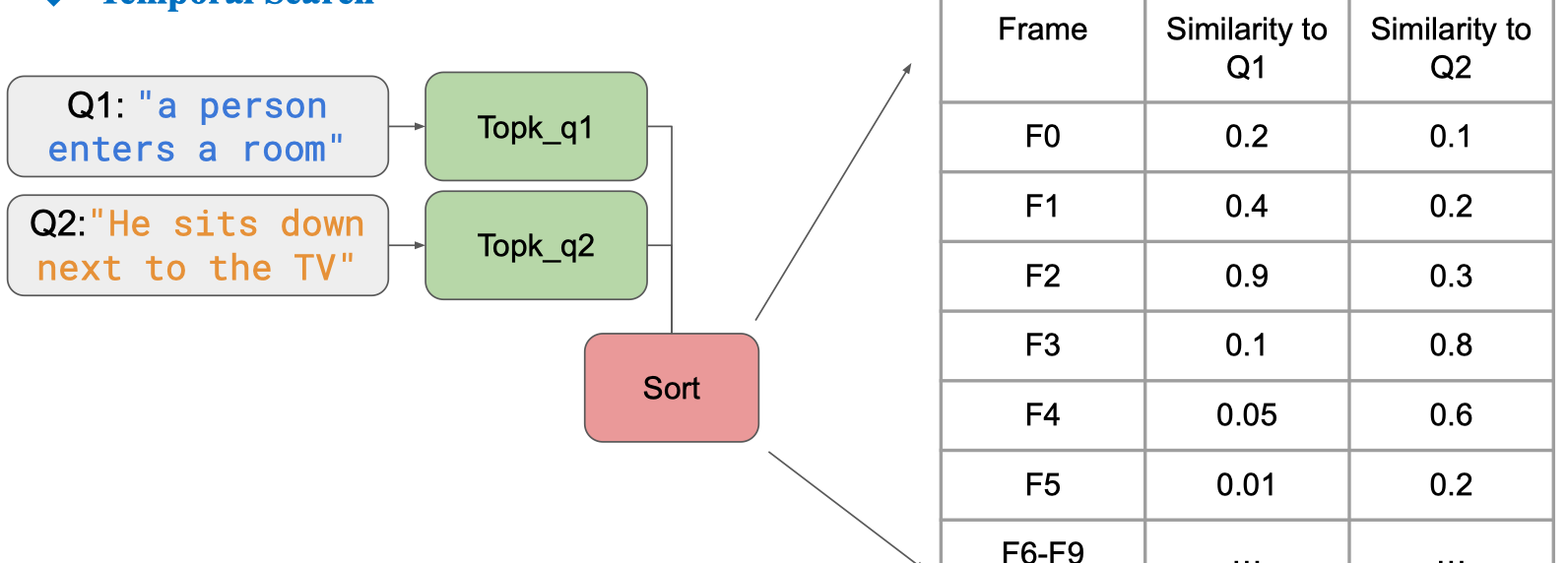
- Tách truy vấn ban đầu thành hai sub-query
- Q1:
"a person enters a room" - Q2:
"He sits down next to the TV"
- Q1:
- Tìm top-k frame cho từng query riêng biệt
- Topk_q1: tập hợp các frame khớp nhất với Q1.
- Topk_q2: tập hợp các frame khớp nhất với Q2.
- Kết hợp & sắp xếp (Sort)
- Gộp danh sách frame từ Topk_q1 và Topk_q2.
- Tính toán điểm liên quan (ví dụ dựa trên độ tương đồng cosine, CLIP similarity…) cho cả Q1 và Q2.
- Bảng kết quả minh họa
- Cột “Similarity to Q1”: mức độ khớp frame với Q1.
- Cột “Similarity to Q2”: mức độ khớp frame với Q2.
- Ví dụ:
- Frame F2 có similarity 0.9 với Q1 → khả năng cao là frame cho sự kiện “người bước vào phòng”.
- Frame F3 có similarity 0.8 với Q2 → khả năng cao là frame cho sự kiện “ngồi cạnh TV”.
- Bước tiếp theo
- Áp dụng ràng buộc thời gian (temporal constraint) để lọc ra các cặp (F_Q1, F_Q2) xuất hiện theo đúng thứ tự và trong khoảng thời gian hợp lệ.
Embedding model
Thực tiễn & Kinh nghiệm thi đấu
- Thường thì đội thắng không chỉ nhờ mô hình tốt mà còn nhờ teamwork, chiến lược tìm kiếm, thao tác nhanh và thậm chí là may mắn!
- Việc tối ưu bộ nhớ và thời gian truy xuất là then chốt. Năm trước, đội giải nhất đã giảm được 500GB còn 80GB dữ liệu nhờ pipeline tối ưu.
III. Software
III.1. Tech Stack
- Backend: FastAPI (Python)
- Vector Search: FAISS hoặc các vector DB mới nhất.
- Model: BLIP/BLIP2, BEIT, CLIP, InternVL…
- Translation: NLLB, M2M100, Google Translate API.
- Object Detection: YOLO, DINO, Co-DETR…
- OCR: MMOCR, VietOCR.
Gợi ý cấu trúc project & tổ chức nhóm
- Cần tối thiểu một thành viên Dev backend.
- Chia nhỏ team: Xử lý dữ liệu, AI modeling, UI/UX, tối ưu hệ thống, documentation.
- Đăng ký mentor nếu cần hỗ trợ về ý tưởng, viết báo cáo.
Câu hỏi để tự kiểm tra/đào sâu
- Nếu chỉ dùng keyframe thì loại truy vấn nào sẽ gặp giới hạn?
- Làm thế nào để kiểm soát chi phí lưu trữ khi dữ liệu lên đến hàng TB?
- Nếu người dùng truy vấn bằng tiếng Việt, làm sao hệ thống tìm đúng moment nếu embedding model không hỗ trợ đa ngôn ngữ?
- Đâu là yếu tố quyết định để thắng cuộc thi: model, pipeline, hay teamwork?
Ví dụ thực tiễn
- Một truy vấn: “Người đàn ông mặc áo đỏ đi vào quán cà phê, sau đó gọi một ly cà phê sữa đá.”
- Nếu chỉ dùng keyframe, bạn có chắc tìm đúng được không?
- Nếu cần pipeline tự động nhận diện hành động, object detection, OCR (đọc tên quán, biển số xe…), bạn sẽ xử lý thế nào?