Table of Content
Important
Tham khảo
1. Introduction
2. Interactive Track
2.1. Keyframe selection
Vấn đề
 Nếu chỉ lấy cố định N keyframe mỗi scene như baseline đã bàn ở buổi trước, cách này đơn giản và nhất quán, nhưng sẽ gặp nhiều vấn đề và hạn chế khi áp dụng thực tế cho bài toán truy xuất video (video retrieval).
Nếu chỉ lấy cố định N keyframe mỗi scene như baseline đã bàn ở buổi trước, cách này đơn giản và nhất quán, nhưng sẽ gặp nhiều vấn đề và hạn chế khi áp dụng thực tế cho bài toán truy xuất video (video retrieval).
- Vấn đề: Độ dài và mức độ thay đổi hình ảnh của mỗi scene khác nhau.
- Scene ngắn → N khung hình có thể trùng lặp nhiều → lãng phí bộ nhớ và thời gian xử lý.
- Scene dài, nhiều hành động → N khung hình có thể bỏ sót các sự kiện quan trọng.
- Ảnh hưởng: Kết quả truy vấn có thể trả về khung hình không tiêu biểu, giảm độ chính xác.
- Vấn đề: Chọn khung hình theo khoảng thời gian cố định, không dựa vào ý nghĩa nội dung.
- Có thể chọn phải thời điểm “chết” (background trống, chuyển cảnh, tạm dừng).
- Hành động hoặc đối tượng quan trọng có thể rơi vào giữa các mốc sampling.
- Ảnh hưởng: Giảm khả năng tìm được khung hình khớp với truy vấn của người dùng.
- Vấn đề: Số N tối ưu cho từng loại video khác nhau.
- Thể thao → cần nhiều keyframe hơn để bắt kịp nhịp thay đổi nhanh.
- Thời sự → ít thay đổi, có thể giảm N.
- Ảnh hưởng: Hoặc là lấy dư thừa gây tốn tài nguyên, hoặc là lấy thiếu làm mất thông tin.
- Vấn đề: Tăng N giúp bao quát hơn nhưng đồng thời tăng số lượng vector phải so khớp.
- Ảnh hưởng: Tăng độ trễ (latency) của hệ thống retrieval khi dữ liệu lớn, đặc biệt với tìm kiếm có ràng buộc thời gian (temporal search).
- Vấn đề: N cố định không thích ứng với mật độ sự kiện theo thời gian.
- Hai sự kiện trong truy vấn (“A rồi B”) có thể xảy ra quá gần nhau → không đủ keyframe để bắt cả hai.
- Ảnh hưởng: Không đảm bảo tìm được chuỗi cảnh theo đúng thứ tự thời gian.
- Vấn đề: Chọn N khung hình không lọc theo độ rõ nét → có thể dính motion blur, bị che khuất hoặc thiếu sáng.
- Ảnh hưởng: Giảm độ chính xác của so khớp và truy xuất.
Giải pháp
Filtering function: loại bỏ những khung hình có độ tương đồng cao vượt quá một ngưỡng threshold.
Pseudo-code giải thích:
filtering_function(scenes, threshold):
for scene in scenes:
for idx, frame in enumerate(scene):
if idx == 0:
continue # Frame đầu tiên của scene luôn được giữ lại
else:
similarity = cosine(scene[idx-1], scene[idx])
if similarity >= threshold:
remove(frame) # Xóa frame nếu giống frame trước đó quá nhiềuÝ tưởng hoạt động:
-
Duyệt từng scene trong video.
-
Giữ lại frame đầu tiên (đại diện).
-
Với mỗi frame tiếp theo:
- Tính độ tương đồng cosine với frame liền trước.
- Nếu độ tương đồng ≥
threshold→ coi như gần trùng lặp → loại bỏ.
-
Kết quả: chỉ giữ lại các frame thực sự khác biệt.

Những hạn chế
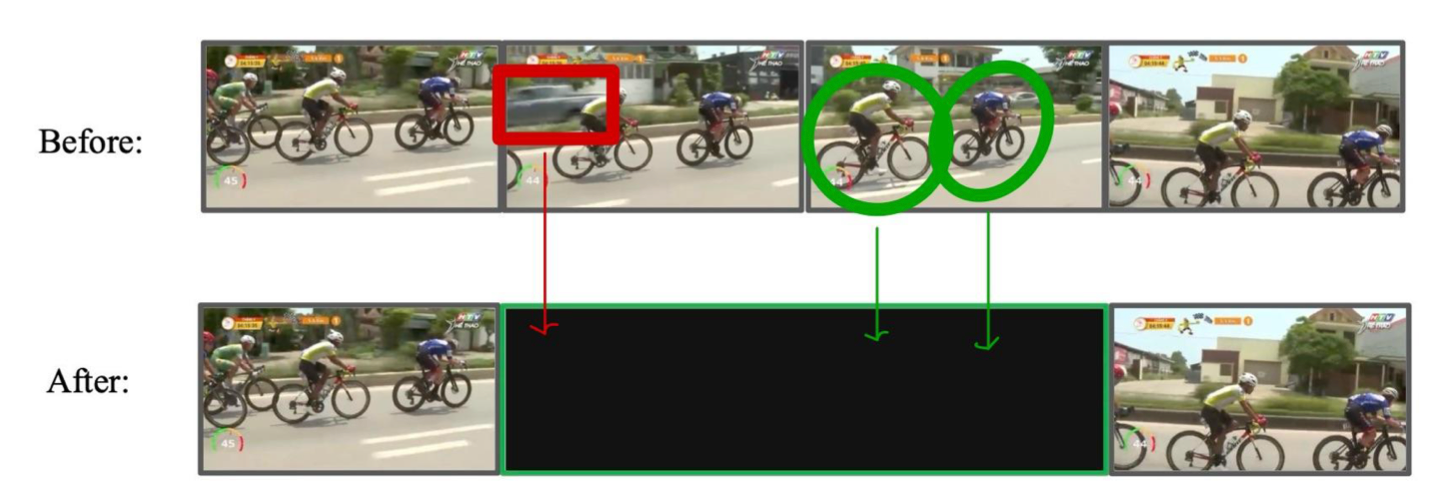

- Chỉ dùng cosine similarity giữa các khung hình liền kề.
- Cosine similarity tính trên pixel thô hoặc embedding đơn giản có thể không bền vững trước thay đổi ánh sáng, rung máy, hoặc dịch chuyển nhỏ của đối tượng.
- Có thể xóa cả những khung hình nhìn tổng thể giống nhau nhưng lại có thay đổi quan trọng ở chi tiết nhỏ (ví dụ: có người bước vào phía sau).
- Nếu đặt
thresholdquá cao, các thay đổi nhỏ nhưng quan trọng về mặt ngữ nghĩa vẫn bị coi là “giống nhau” và bị loại.- Ví dụ: Trong video giám sát, một người lấy vật từ bàn có thể chỉ làm thay đổi một vùng nhỏ của khung hình.
- Chỉ so sánh với khung hình ngay trước đó.
- Nếu hai khung hình giống nhau xuất hiện cách xa nhau về thời gian nhưng lại thuộc những thời điểm khác nhau trong câu chuyện, phương pháp này sẽ vẫn giữ cả hai → bỏ lỡ cơ hội lọc tốt hơn.
- Ngược lại, trong cảnh chuyển mờ hoặc cross-dissolve, khung hình liền kề có thể khác nhau chút ít và bị giữ lại, tạo ra dư thừa.
- Chỉ dùng một giá trị
thresholdcho mọi video/cảnh quay.- Ngưỡng tối ưu khác nhau với cảnh quay nhanh và cảnh tĩnh.
- Một giá trị cố định có thể lọc quá mạnh ở cảnh tĩnh và lọc quá yếu ở cảnh động.
Cách tối ưu
Hàm chọn keyframe cần:
- Giữ lại ít khung hình nhất có thể nhưng vẫn bảo toàn toàn bộ thông tin quan trọng.
- Thực hiện bằng cách:
- Loại bỏ các khung hình có biến đổi giữa các frame (inter-frame variation) rất nhỏ → cách tiếp cận mới nhất.
- Thêm các ràng buộc bổ sung để đảm bảo một số yếu tố cần thiết luôn được đáp ứng. Các ràng buộc bổ sung:
- Số lượng đối tượng trong khung hình (Number of objects).
- Thông tin màu sắc, vị trí (Color, Location Information).
- Các yếu tố khác tùy bài toán (ví dụ: góc quay, kích thước vật thể, trạng thái hành động, v.v.).
2.2. Temporal Search
Vấn đề
Để thiết kế temporal search tối ưu (tìm A rồi đến B trong khoảng thời gian ràng buộc). Mục tiêu: chính xác, nhanh, mở rộng.
Làm sao để thiết kế một hàm Temporal Search tối ưu?
Dùng fixed time T (ví dụ chấm điểm):
score = sim(Q1, F_i) + max(sim(Q2, F_{i+1 : i+T}))) làm baseline có những vấn đề & hạn chế sau:
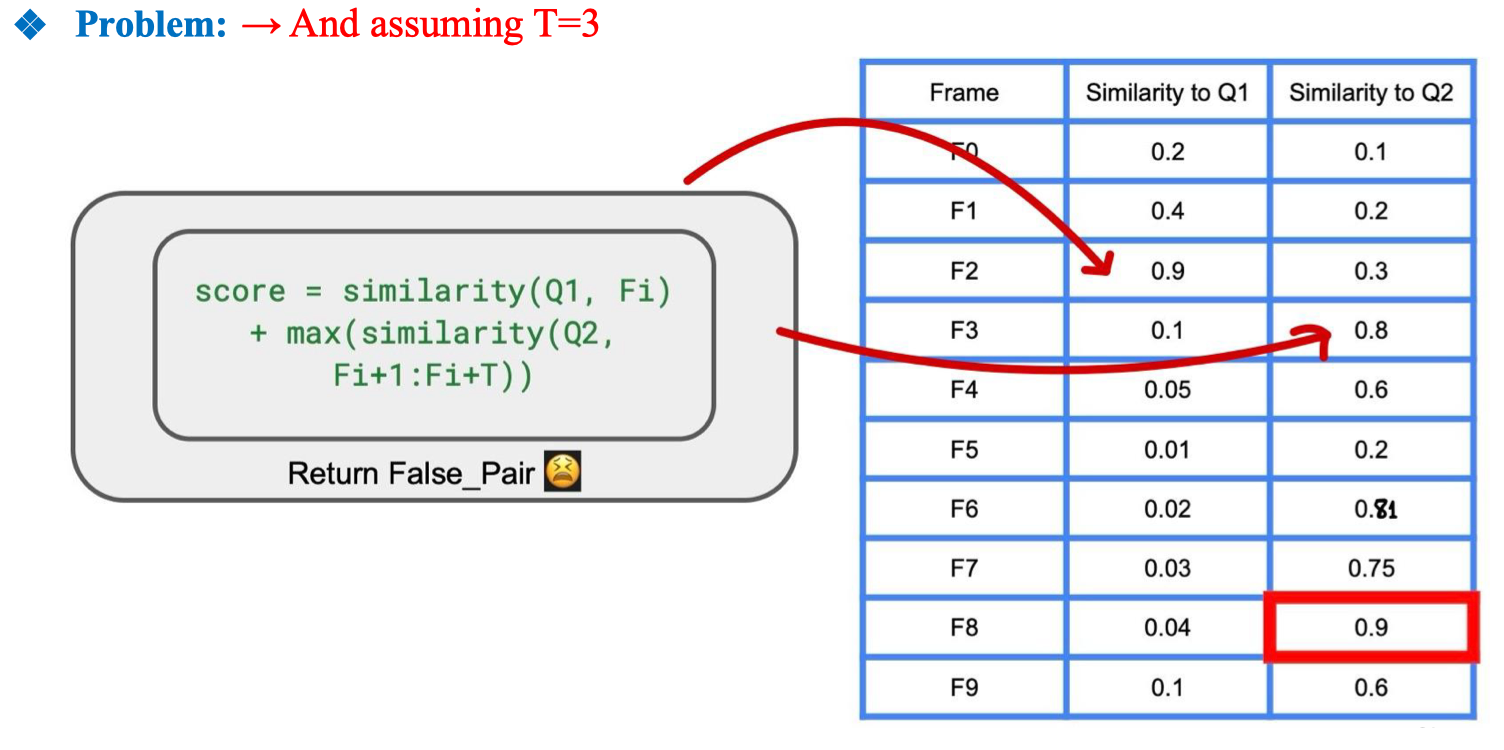
- Ở đây, F2 có similarity với Q1 rất cao (0.9), nên được chọn làm ứng viên cho event A.
- Trong cửa sổ kế tiếp
F3:F5(T=3 frame sau F2), frame F3 có similarity với Q2 = 0.8 → cao nhất trong cửa sổ. - Nhưng: F3 không liên quan về mặt ngữ nghĩa với F2 trong bối cảnh câu truy vấn, chỉ tình cờ có điểm cao với Q2.
- Kết quả: hệ thống ghép F2 (Q1) với F3 (Q2) → tạo false pair (cặp sai). Nguyên nhân
- Chỉ xét max trong cửa sổ T → dễ bị “ăn nhầm” outlier (frame điểm cao nhưng không đúng bối cảnh).
- Không kiểm tra tính liền mạch ngữ nghĩa hoặc mối quan hệ thực sự giữa F_Q1 và F_Q2.
- Không phạt khoảng cách thời gian → F3 dù rất sát về thời gian nhưng có thể thuộc một bối cảnh khác hoàn toàn.
- Không giới hạn theo scene → Q1 và Q2 có thể ở hai scene khác nhau nhưng vẫn được ghép nếu nằm trong T. Hệ quả
- Tạo ra nhiều false positive, làm giảm precision.
- Với video dài hoặc nhiều nhân vật, khả năng chọn sai tăng mạnh.
- Nếu Q2 xuất hiện nhiều lần, hệ thống có thể chọn một lần xuất hiện không đúng cặp với Q1.
Phương án xử lý
Ý tưởng
- Thay vì cố định T (cửa sổ tìm Q2), ta mở rộng tìm kiếm cho đến khi đủ điều kiện dừng.
- Dùng tolerance để cho phép bỏ qua một số frame không cải thiện similarity, nhưng không dừng ngay khi gặp 1 frame điểm thấp.
tolerance = 0 # Số frame liên tiếp không cải thiện điểm
best = 0 # Giá trị similarity cao nhất tìm được
threshold = 3 # Cho phép tối đa 3 frame liên tiếp không cải thiện
for idx in range(current_idx+1, end_idx):
similarity = cosine(current_kf, kfs[idx]) # Độ tương đồng Q2 với frame idx
if best < similarity: # Nếu tìm thấy điểm cao hơn
best = similarity
tolerance = 0 # Reset tolerance
else:
tolerance += 1 # Tăng số frame không cải thiện
if tolerance == threshold: # Nếu chạm ngưỡng không cải thiện
return # Dừng tìm kiếmƯu điểm so với fixed T
- Linh hoạt hơn: Không giới hạn số frame cứng → có thể tìm Q2 xa hơn nếu cần.
- Giảm false positive: Nếu chỉ gặp 1 điểm cao rồi liên tiếp nhiều điểm thấp, vòng lặp sẽ dừng → tránh chọn Q2 không ổn định.
- Tự động tối ưu theo nội dung: Tolerance điều chỉnh việc mở rộng/dừng tùy theo phân bố similarity.
Hạn chế tiềm ẩn
- Nếu Q2 xuất hiện rất muộn sau Q1, vòng lặp có thể dừng sớm và bỏ sót → cần kết hợp với giới hạn max search range.
- Không xét thêm ràng buộc ngữ nghĩa (đối tượng, màu, scene), chỉ dựa vào similarity score. Vì vậy ra phải cân bằng Mục tiêu (TARGET): Tìm ra thời điểm tối ưu vừa nhanh vừa chính xác bằng cách cân bằng giữa:
- Exploitation – tận dụng tối đa thông tin hiện tại để tăng tốc tìm kiếm.
- Exploration – mở rộng tìm kiếm để không bỏ lỡ kết quả quan trọng nhất.
2.3. Reranking
Áp dụng Additional Constraints cho truy vấn tìm kiếm khung hình video.

-
Truy vấn ban đầu:
"Khung cảnh thời sự trên kênh truyền hình VTV"→ Hệ thống trả về một loạt khung hình có cảnh ngập lụt trên VTV, nhưng chưa ưu tiên khung cảnh nào cụ thể.
-
Thêm ràng buộc mới (Additional Constraint):
Thêm từ khóa
"NEW COFFEE"vào truy vấn.→ Lúc này hệ thống sẽ rerank (xếp hạng lại) kết quả, đưa những khung hình có chứa biển hiệu “NEW COFFEE” lên vị trí đầu tiên.
Các hạn chế
- Rất khó để tìm ra một cách tiếp cận chung mà có thể áp dụng cho mọi tình huống.
- Ví dụ không thể biết được các meta data nếu input cho dạng text hoặc là quá ít thông tin. → Từ đó rất khó để thiết kế và add thêm các ràng buộc cho truy vấn.
Các cách tiếp cận khác:
Using MLLM Model
-
Ý tưởng: Sử dụng MLLM (Multimodal Large Language Model) cho video/vision để đánh giá mức độ phù hợp về ngữ nghĩa giữa từng phân đoạn shot/keyframe và truy vấn đầu vào.
-
Mô hình sẽ tạo ra điểm liên quan (relevance score) trong khoảng [0, 1] cho mỗi phân đoạn.
-
Sau đó, các phân đoạn sẽ được xếp hạng giảm dần theo điểm này.
-
Những phân đoạn có điểm cao nhất sẽ được chọn làm kết quả truy xuất cuối cùng.
Quy trình minh họa (Example):
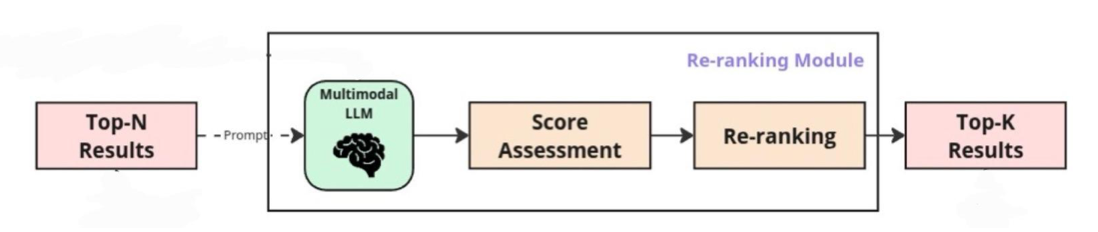
- Lấy Top-N kết quả ban đầu từ hệ thống tìm kiếm.
- Gửi chúng vào MLLM đa phương thức cùng với truy vấn (prompt).
- Đánh giá điểm (Score Assessment) cho từng kết quả.
- Xếp hạng lại (Re-ranking) dựa trên điểm số.
- Chọn ra Top-K kết quả cuối cùng.
Using Cross-Encoder Model
-
Ý tưởng: Thay vì dùng kiến trúc bi-encoder (mã hóa độc lập truy vấn và dữ liệu ứng viên), phương pháp này dùng cross-encoder để xử lý chung cả truy vấn và dữ liệu ứng viên trong cùng một mô hình.
-
Cách này giúp mô hình hiểu rõ ngữ cảnh và đánh giá độ liên quan chính xác hơn nhờ tương tác trực tiếp giữa hai đầu vào.
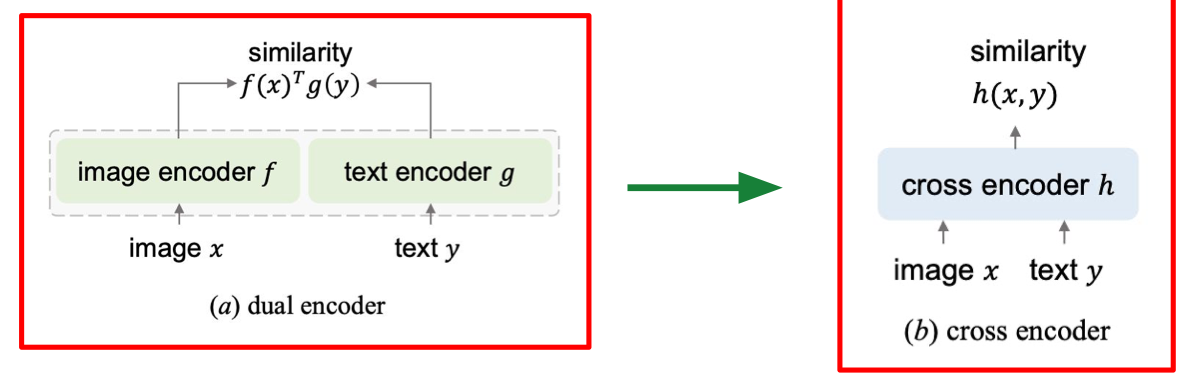
So sánh minh họa:
- Bi-encoder (dual encoder):
- Ảnh và văn bản được đưa vào hai encoder riêng biệt.
- Tính độ tương đồng dựa trên tích vô hướng giữa hai vector kết quả.
- Cross-encoder:
- Ảnh và văn bản được đưa cùng nhau vào một encoder chung.
- Mô hình trực tiếp học ra điểm tương đồng từ dữ liệu kết hợp, cho phép tương tác ngữ cảnh tốt hơn.
- Bi-encoder (dual encoder):
Using Cross-Modal Region–Phrase Alignment
-
Ý tưởng:
Thay vì chỉ so khớp toàn bộ ảnh với toàn bộ câu, ta chia ảnh thành các vùng cục bộ (local patches) hoặc các đề xuất đối tượng (object proposals, ví dụ từ Faster R-CNN hoặc bản đồ attention của ViT).
Sau đó, từng vùng ảnh sẽ được ghép nối với các cụm từ mô tả tương ứng trong văn bản.
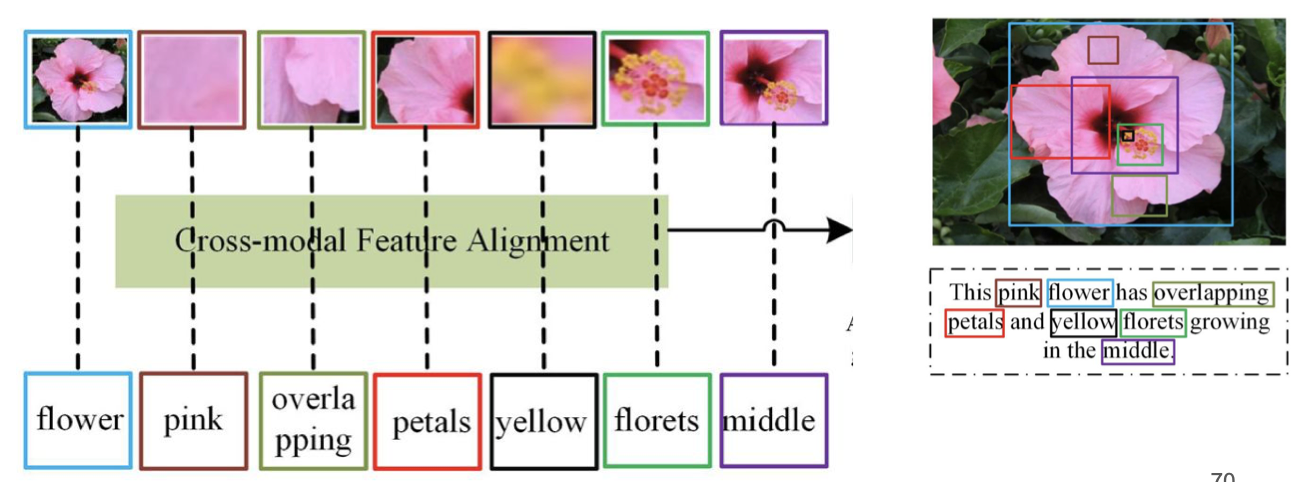
-
Quy trình minh họa:
- Ảnh hoa được chia thành nhiều vùng khác nhau: cánh hoa, nhụy hoa, phần giữa, màu sắc, v.v.
- Văn bản mô tả chứa các cụm từ như: flower, pink, overlapping petals, yellow florets, middle.
- Cross-modal Feature Alignment sẽ nối từng vùng ảnh với cụm từ phù hợp, ví dụ:
- Vùng chứa toàn bộ bông hoa → flower
- Vùng màu hồng → pink
- Vùng nhụy vàng → yellow florets
- Vùng giữa bông → middle
-
Lợi ích:
- Hiểu chi tiết và chính xác hơn mối liên kết giữa hình ảnh và ngôn ngữ.
- Hữu ích cho các tác vụ như image captioning, visual question answering, fine-grained retrieval.
Tuy nhiên ở đây vẫn có vấn đề của phương pháp model-based reranking
- Không phù hợp cho ứng dụng thực tế vì cần tài nguyên tính toán lớn để chạy.
- Độ trễ cao do mỗi lần reranking đều phải chạy lại mô hình từ đầu. Yêu cầu đối với phương pháp thay thế
- Hoạt động với yêu cầu tài nguyên ở mức vừa phải.
- Giảm thiểu độ trễ khi xử lý.
- Loại bỏ nhu cầu trích xuất đặc trưng cục bộ phức tạp.
- (Có thể bổ sung) Dễ triển khai và áp dụng trong môi trường thực tế.
Global Features
Ref: Global Features are All You Need for Image Retrieval and Reranking
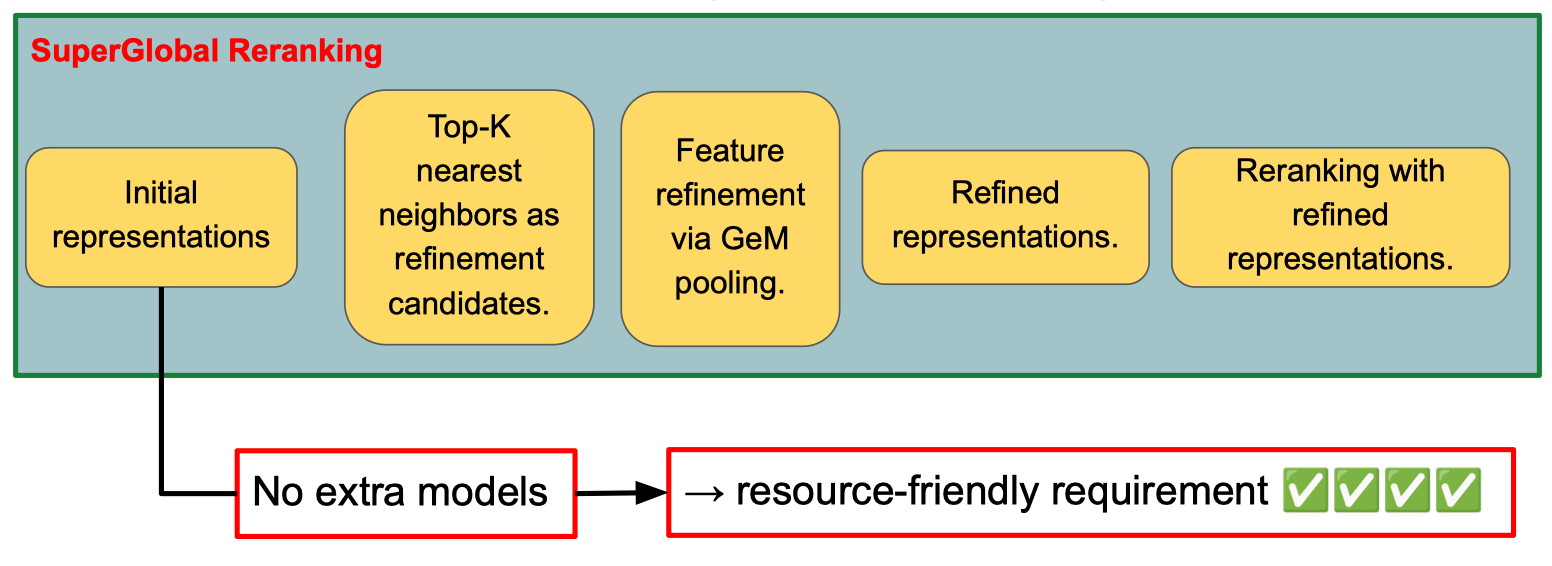 Cách tiếp cận SuperGlobal Reranking với các đặc điểm chính:
Cách tiếp cận SuperGlobal Reranking với các đặc điểm chính:
- Initial representations: Sử dụng đặc trưng ban đầu của ảnh.
- Top-K nearest neighbors: Chọn K ảnh gần nhất làm ứng viên tinh chỉnh.
- Feature refinement via GeM pooling: Tinh chỉnh đặc trưng bằng phương pháp GeM pooling.
- Refined representations: Có được đặc trưng đã tinh chỉnh.
- Reranking with refined representations: Xếp hạng lại dựa trên đặc trưng mới. Điểm mạnh nổi bật
- Không cần mô hình bổ sung → Đáp ứng tiêu chí tiết kiệm tài nguyên (resource-friendly).
Cách tiến hành:
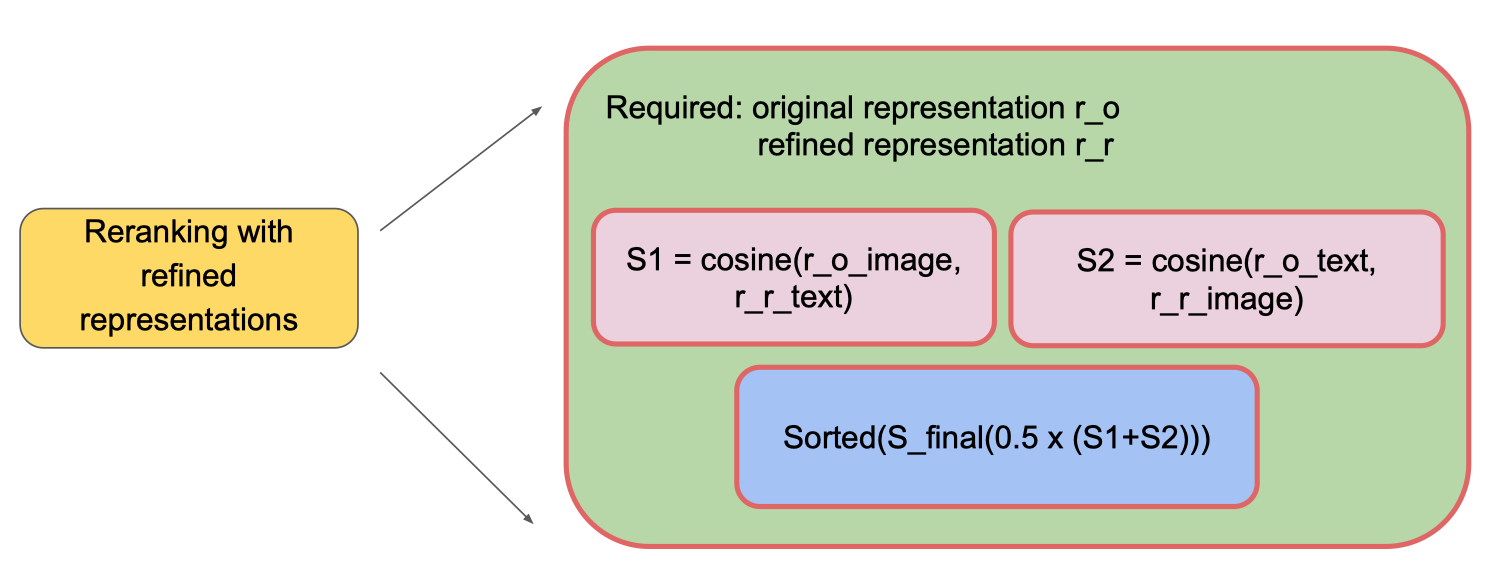
- Yêu cầu đầu vào
r_o: đặc trưng ban đầu (original representation).r_r: đặc trưng đã tinh chỉnh (refined representation).
- Tính toán điểm tương đồng
S1 = cosine(r_o_image, r_r_text)– độ tương đồng cosine giữa ảnh gốc và văn bản tinh chỉnh.S2 = cosine(r_o_text, r_r_image)– độ tương đồng cosine giữa văn bản gốc và ảnh tinh chỉnh.
- Kết hợp và xếp hạng lại
S_final = 0.5 × (S1 + S2)– lấy trung bình cộng của hai điểm tương đồng.- Sắp xếp các kết quả theo
S_finalgiảm dần để có thứ hạng cuối.
2.4. Conversational Chat
- Mục tiêu (TARGET)
- Kết quả ban đầu có thể chưa đáp ứng hoàn toàn mong đợi của người dùng.
- Phản hồi từ người dùng được sử dụng để tinh chỉnh các vòng lặp tiếp theo, giúp cải thiện kết quả.
- Công thức tính điểm
- Giải thích các thành phần
- : keyframe cần đánh giá trong vòng tiếp theo.
- : hàm tính cosine similarity.
- : vector embedding của truy vấn (query).
- : các frame mà người dùng đánh dấu là liên quan (related).
- : các frame mà người dùng đánh dấu là không liên quan (unrelated).
- Ý nghĩa
- Điểm số được tính dựa trên:
- Độ tương đồng giữa truy vấn và keyframe cần đánh giá.
- Cộng thêm ảnh hưởng từ các frame liên quan.
- Trừ đi ảnh hưởng từ các frame không liên quan.
- Điểm số được tính dựa trên:
Ref: https://link.springer.com/chapter/10.1007/978-3-031-27077-2_52
- NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search
- A Conceptual Framework for Conversational Search and Recommendation
- A Survey of Conversational Search
- ConvGQR: Generative Query Reformulation for Conversational Search
2.5. Others
Ensemble Search
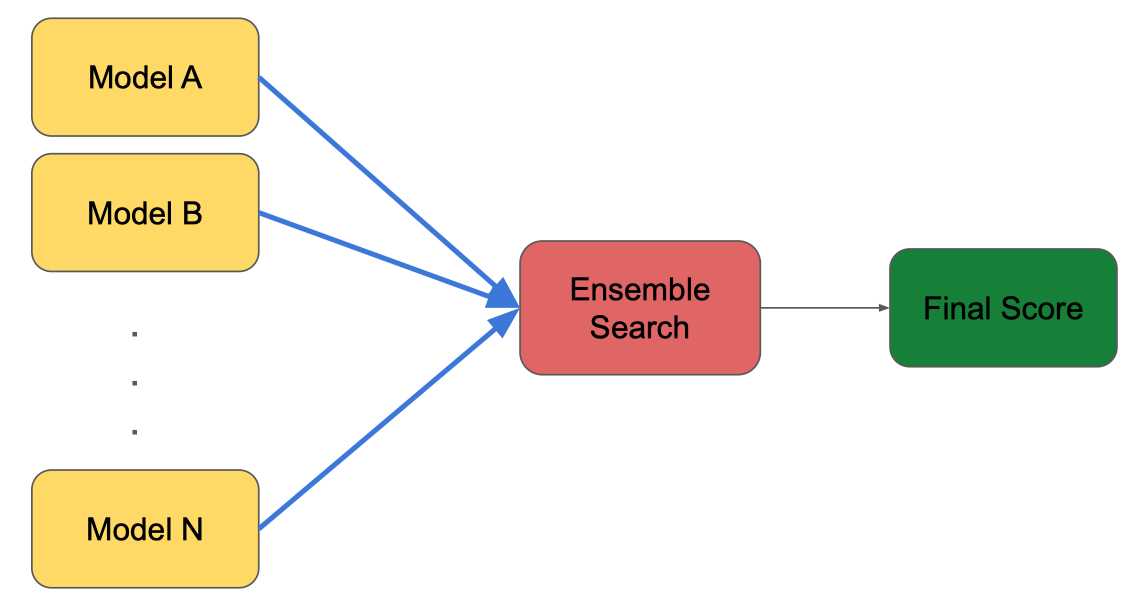
- Ý tưởng:
- Kết hợp nhiều mô hình tìm kiếm (Model A, Model B, …, Model N) để cải thiện chất lượng kết quả.
- Quy trình:
- Đầu vào: Các mô hình riêng lẻ (Model A, Model B, …, Model N) đưa ra điểm số hoặc kết quả tìm kiếm của riêng mình.
- Ensemble Search: Tổng hợp và kết hợp kết quả từ các mô hình này theo một phương pháp nhất định (ví dụ: trung bình trọng số, voting, hoặc stacking).
- Final Score: Xuất ra điểm số cuối cùng, dùng để xếp hạng hoặc lựa chọn kết quả tốt nhất.
- Mục tiêu: Tận dụng ưu điểm của từng mô hình riêng lẻ để tăng độ chính xác và độ tin cậy của kết quả tìm kiếm tổng hợp. Ref:https://openaccess.thecvf.com/content/CVPR2025W/IViSE/papers/Tran_Towards_Efficient_and_Robust_Moment_Retrieval_System_A_Unified_Framework_CVPRW_2025_paper.pdf
Filtering Mechanism
- Sử dụng metadata đã được trích xuất trước đó (ví dụ: Object Location, Quantity, Color, ASR, OCR, …) để lọc kết quả hiện tại.
- Câu hỏi mở:
- Làm thế nào để luôn đảm bảo quá trình lọc đạt hiệu quả cao? Ref: https://drive.google.com/file/d/1Yjp0BmKodXY2KLOwUglTqhMFAb2BNOYb/view
Pose Estimation
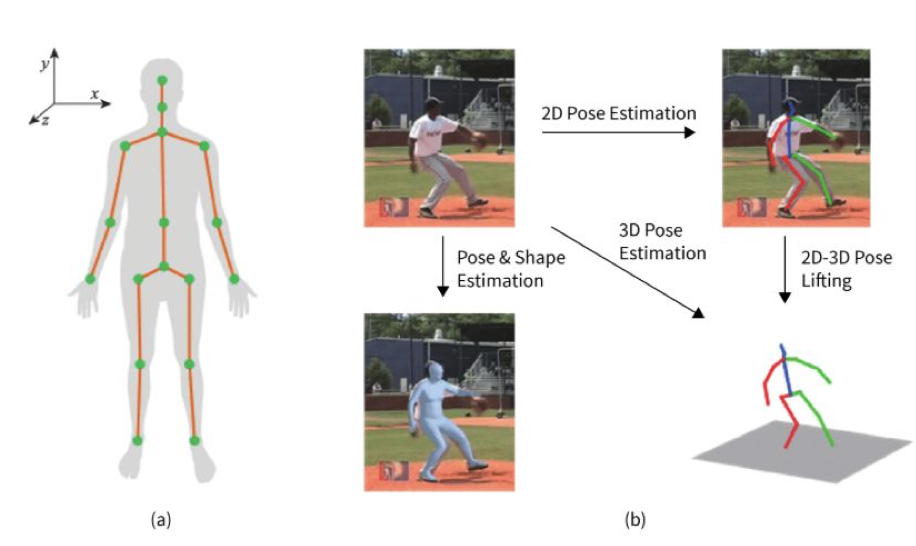 Pose Estimation – kỹ thuật xác định tư thế cơ thể người dựa trên ảnh hoặc video.
Pose Estimation – kỹ thuật xác định tư thế cơ thể người dựa trên ảnh hoặc video.
- Nhận diện khớp cơ thể
- Mô hình xác định các điểm đặc trưng (keypoints) của cơ thể như đầu, vai, khuỷu tay, đầu gối, mắt cá, cổ tay…
- Các điểm này được nối thành khung xương (skeleton) để mô tả tư thế.
- 2D Pose Estimation
- Từ ảnh đầu vào, hệ thống trích xuất vị trí các khớp trên mặt phẳng 2D (tọa độ x, y).
- Kết quả là hình người với các đường nối mô phỏng tư thế.
- 3D Pose Estimation
- Dự đoán vị trí khớp trong không gian 3D (tọa độ x, y, z) trực tiếp từ ảnh.
- Cho phép phân tích độ sâu và góc nhìn.
- 2D-3D Pose Lifting
- Bắt đầu từ dữ liệu 2D, mô hình dự đoán thêm trục z để nâng dữ liệu thành 3D.
- Giúp giảm nhu cầu dữ liệu huấn luyện 3D trực tiếp.
- Pose & Shape Estimation
- Ngoài khung xương, mô hình ước lượng hình dạng toàn bộ cơ thể (ví dụ: bề mặt 3D).
- Thích hợp cho ứng dụng mô phỏng và thực tế ảo.
Segmentation

- Semantic Segmentation (b)
- Phân loại từng pixel của ảnh vào một lớp (class) nhất định.
- Các đối tượng cùng loại sẽ có cùng màu (ví dụ: cả hai con chó đều màu hồng).
- Không phân biệt từng cá thể riêng biệt.
- Instance Segmentation (c)
- Vừa xác định loại đối tượng, vừa phân biệt từng cá thể trong cùng một lớp.
- Ví dụ: hai con chó được tô màu khác nhau (hồng và tím) và có khung bao (bounding box) riêng.
- Panoptic Segmentation (d)
- Kết hợp Semantic Segmentation và Instance Segmentation.
- Tất cả pixel đều được gán nhãn lớp, đồng thời các đối tượng cùng lớp nhưng khác cá thể vẫn được phân biệt.
- Giữ nguyên bối cảnh nền và phân biệt cả vật thể lẫn vùng không phải vật thể. Ref: https://arxiv.org/pdf/2408.12957
Tagging Search
Phương pháp gán nhãn (tags) cho hình ảnh để phục vụ tìm kiếm, so sánh giữa các mô hình nhận diện khác nhau. Cách hoạt động
- Input: ảnh cần gán nhãn.
- Output: danh sách các từ khóa (tags) mô tả nội dung ảnh.
- Mục tiêu: tìm ra các từ khóa đúng, đầy đủ, không thiếu (missing) và không sai (bad).

- Ảnh bên trái: phòng khách với ghế sofa, bàn, thảm, đèn, cây cảnh, chó,…
- Ảnh bên phải: chợ Giáng Sinh với cây thông, quầy hàng, tuyết, tòa nhà, người đi dạo,… So sánh mô hình
- RAM: Tương đối đầy đủ, nhận diện chi tiết nhiều vật thể, nhưng vẫn thiếu một số tag (lamp, carpet).
- Tag2Text: Nhận diện khá tốt, có phần “modern” mô tả phong cách, nhưng thiếu một số đối tượng và chưa đủ chi tiết.
- ML-Decoder: Thêm các tag mô tả chi tiết nội thất, nhưng đôi khi xuất hiện tag sai (“property”, “design”).
- BLIP: Ngắn gọn, bắt được các đối tượng chính, nhưng thiếu nhiều chi tiết phụ.
- Google Tagging API: Một số tag không liên quan (“event”, “television”), bỏ sót nhiều đối tượng quan trọng. Ý nghĩa
- Tagging Search giúp tìm kiếm hình ảnh dựa trên nội dung, hữu ích cho thư viện ảnh lớn, hệ thống gợi ý sản phẩm, hoặc phân loại dữ liệu huấn luyện AI.
- Đánh giá mô hình dựa trên độ chính xác (accuracy), độ bao phủ (recall), và tỷ lệ tag sai (false positive).
 Ref: https://arxiv.org/pdf/2306.03514
Ref: https://arxiv.org/pdf/2306.03514
Keyphrase Search
Tìm kiếm và trích xuất các cụm từ khóa quan trọng từ văn bản. Cách hoạt động
- Input: Một đoạn văn bản (document).
- Output:
- Present keyphrases: Các cụm từ khóa xuất hiện trong văn bản và có liên quan đến chủ đề (tô màu xanh).
- Absent keyphrases: Các cụm từ khóa quan trọng nhưng không xuất hiện trực tiếp trong văn bản (tô màu đỏ).
- Mục tiêu: Hệ thống không chỉ nhận ra các từ khóa xuất hiện trong văn bản, mà còn dự đoán được các từ khóa liên quan dù chúng không được đề cập trực tiếp.
Ví dụ trong hình

- Văn bản nói về việc chọn wavelet tối ưu để phát hiện singularities trong dữ liệu giao thông.
- Present keyphrases (có trong văn bản):
- wavelet transform
- oblique cumulative curve
- short time fourier
- the mexican hat wavelet
- Absent keyphrases (không xuất hiện nhưng có liên quan):
- singularity detection
- traffic data analysis Ý nghĩa
- Phương pháp này đặc biệt hữu ích trong tìm kiếm học thuật, phân loại tài liệu, và truy vấn mở rộng.
- Việc phát hiện được absent keyphrases giúp nâng cao khả năng truy vấn khi người dùng tìm kiếm bằng các thuật ngữ liên quan nhưng không xuất hiện trực tiếp trong tài liệu. Ref: https://arxiv.org/pdf/2106.04847
Causality Relation
Mối quan hệ nhân quả (Causality Relation) giữa hai biến số:
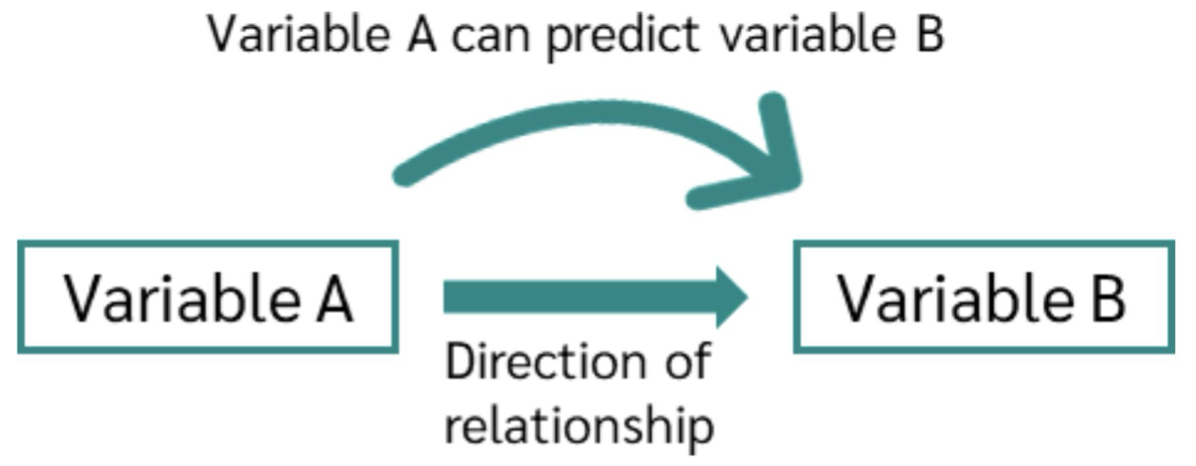
-
Variable A: Biến nguyên nhân hoặc biến dự đoán.
-
Variable B: Biến kết quả hoặc biến được dự đoán.
-
Ý nghĩa:
- Khi Variable A thay đổi, nó có thể dự đoán hoặc gây ảnh hưởng đến Variable B.
- Mũi tên thể hiện chiều tác động (direction of relationship) từ A sang B.
- Đây là mối quan hệ có định hướng (directed relationship), khác với tương quan (correlation) vốn không chỉ ra nguyên nhân – kết quả. Ví dụ minh họa
-
A = “Số giờ học mỗi ngày”
-
B = “Điểm thi cuối kỳ”
→ Tăng số giờ học (A) có thể dự đoán điểm thi (B) tăng, nếu giả định các yếu tố khác không đổi.
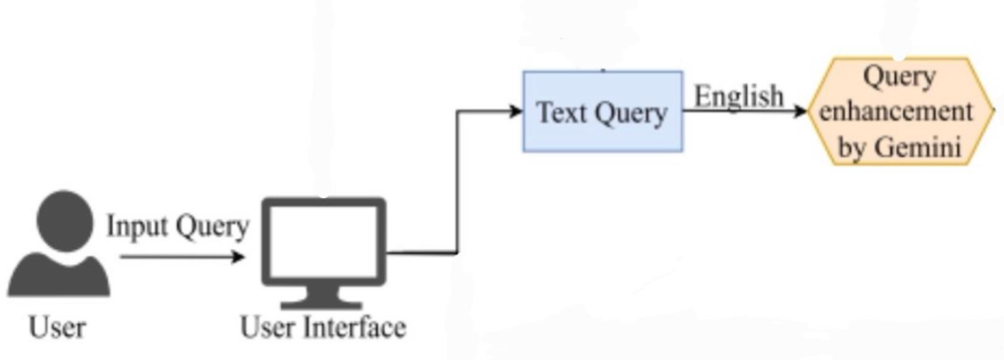
Query Enhancement
Cải thiện truy vấn ban đầu của người dùng để hệ thống hiểu rõ hơn ý định tìm kiếm và trả về kết quả chính xác hơn. Mô tả phương pháp:
-
Mục tiêu: Giải quyết vấn đề truy vấn đầu vào thường mơ hồ, không đầy đủ hoặc thiếu chính xác.
-
Cách tiếp cận:
- Phân tích ý định tìm kiếm từ câu truy vấn gốc của người dùng.
- Tái cấu trúc hoặc mở rộng truy vấn để mô tả đầy đủ và rõ ràng hơn.
- Áp dụng các kỹ thuật:
- Query Expansion: Thêm các từ khóa liên quan (đồng nghĩa, liên quan ngữ nghĩa).
- Query Rewriting: Viết lại câu truy vấn sao cho rõ ràng, chính xác hơn.
- Term Substitution: Thay thế thuật ngữ bằng từ tương đương hoặc phổ biến hơn.
- Hybrid Approaches: Kết hợp nhiều kỹ thuật trên.
- Triển khai:
- Người dùng nhập câu truy vấn → hệ thống nhận dạng và chuyển thành text query.
- Một mô-đun (ví dụ: Gemini) sẽ xử lý, nâng cấp câu truy vấn.
- Truy vấn cải thiện này được gửi tới hệ thống tìm kiếm để trả về kết quả tốt hơn. Ref: https://drive.google.com/file/d/17UT6afbJSfBXuq2tdEhv2MjmlTQlb6Sj/view
Others
-
Hiển thị theo mức độ tương đồng giảm dần – sắp xếp các kết quả hình ảnh theo thứ tự từ giống nhất đến ít giống hơn.

-
Hiển thị dưới dạng video – hỗ trợ phát trực tiếp hoặc xem lại theo chuỗi khung hình.
-
Lưu trữ ảnh với độ phân giải thấp và định dạng thay thế – tối ưu dung lượng lưu trữ, tăng tốc độ tải.
3. Automatic Track
3.1. Retrieval Task
- Bài toán: Video Corpus Moment Retrieval – tìm các khoảnh khắc trong tập video dựa trên truy vấn.
- Automatic Track:
- Input:
- Query – câu hoặc đoạn văn tự do.
- Video corpus – tập video (có thể kèm ASR hoặc metadata).
- Output:
-
Danh sách xếp hạng (top-K ≤ 100) các khoảnh khắc ứng viên:
-
Thời gian hoặc chỉ số khung hình trong timeline gốc.
-
- Input:
Pipeline
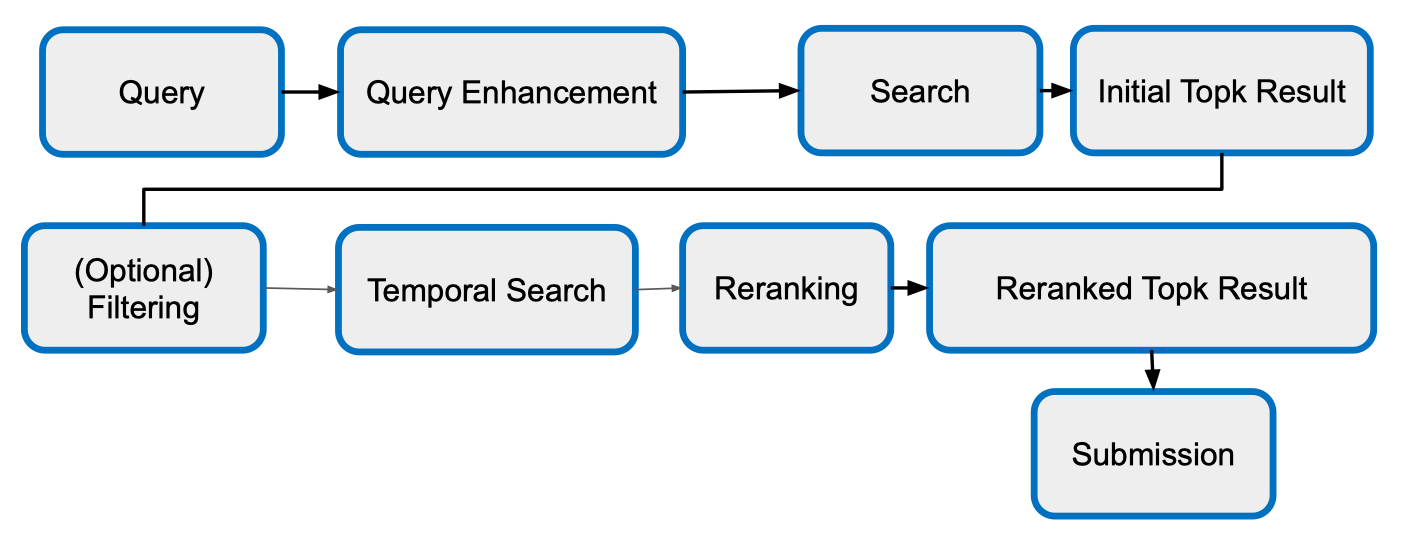
- Query – Người dùng đưa ra truy vấn dạng câu hoặc đoạn văn.
- (Optional) Query Enhancement – Tiền xử lý hoặc mở rộng truy vấn (ví dụ: đồng nghĩa, paraphrase) để cải thiện khả năng tìm kiếm.
- Search – Tìm kiếm trong tập video dựa trên truy vấn đã cải thiện.
- (Optional) Initial Top-k Result – Lấy danh sách kết quả top-k ban đầu (theo mức độ liên quan).
- (Optional) Filtering – Lọc bớt những kết quả không phù hợp (nếu cần).
- Temporal Search – Xác định các khoảng thời gian (moment) chính xác trong video khớp với truy vấn.
- Reranking – Xếp hạng lại kết quả dựa trên thông tin thời gian và các tiêu chí khác.
- Reranked Top-k Result – Danh sách kết quả đã được sắp xếp lại.
- Submission – Xuất danh sách cuối cùng để nộp hoặc sử dụng.
3.2. VQA Task
1. Problem Statement
- Mục tiêu: Cho một video và một câu hỏi dạng văn bản tự do, hệ thống cần đưa ra câu trả lời phù hợp dựa trên nội dung video. 2. Input
- Video V:
- Dữ liệu có thể là chuỗi RGB frames hoặc encoded video URI.
- Có thể kèm theo audio track, timestamps, và các metadata khác.
- Question Q:
- Câu hỏi dạng free-form text (ngôn ngữ tự nhiên, không giới hạn cấu trúc). 3. Output
- Answer A:
- Một đoạn văn bản ngắn, có thể là free text hoặc chọn từ một tập từ vựng cố định.
Agent
ref: https://arxiv.org/pdf/2503.21460
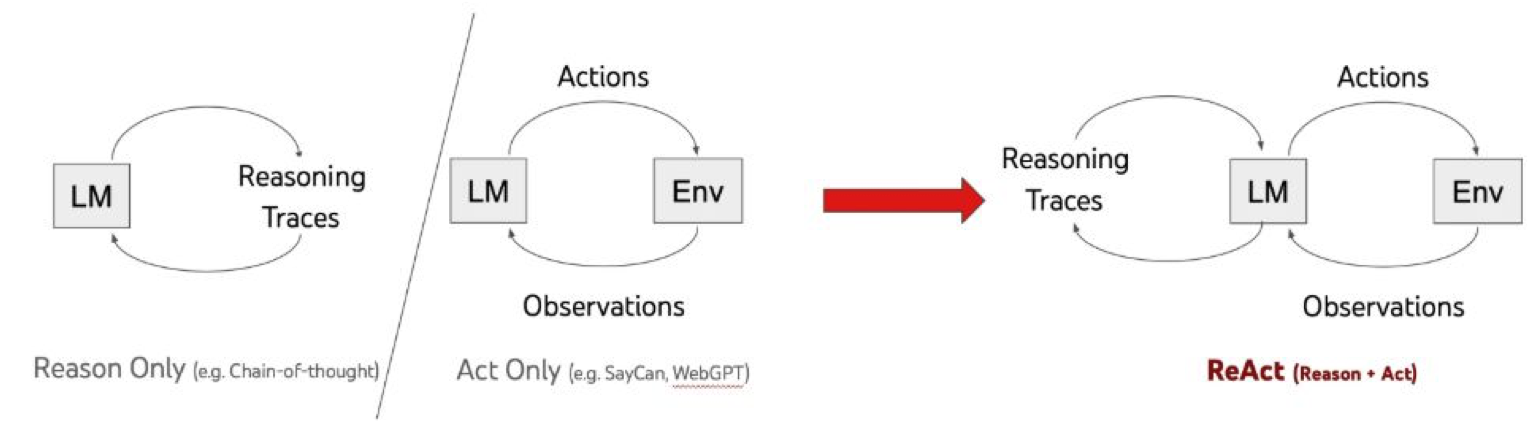 Reason Only (Chỉ suy luận)
Reason Only (Chỉ suy luận)
- Ví dụ: Chain-of-thought.
- Mô hình ngôn ngữ (LM) chỉ tạo ra Reasoning Traces (chuỗi suy nghĩ) để giải quyết vấn đề.
- Không thực hiện hành động tương tác với môi trường (Env). 2. Act Only (Chỉ hành động)
- Ví dụ: SayCan, WebGPT.
- LM chỉ tạo ra Actions (hành động) dựa trên Observations (quan sát) từ môi trường.
- Không có quá trình giải thích hoặc lưu lại suy nghĩ trung gian. 3. ReAct (Reason + Act)
- Kết hợp cả Reasoning Traces và Actions.
- Quy trình:
- LM quan sát dữ liệu từ môi trường (Observations).
- LM tạo ra cả suy luận (Reasoning Traces) và hành động (Actions).
- Môi trường phản hồi → LM tiếp tục cập nhật suy luận và hành động mới.
- Giúp tác nhân vừa có khả năng giải thích, vừa ra quyết định, tăng tính minh bạch và hiệu quả.
Pipeline
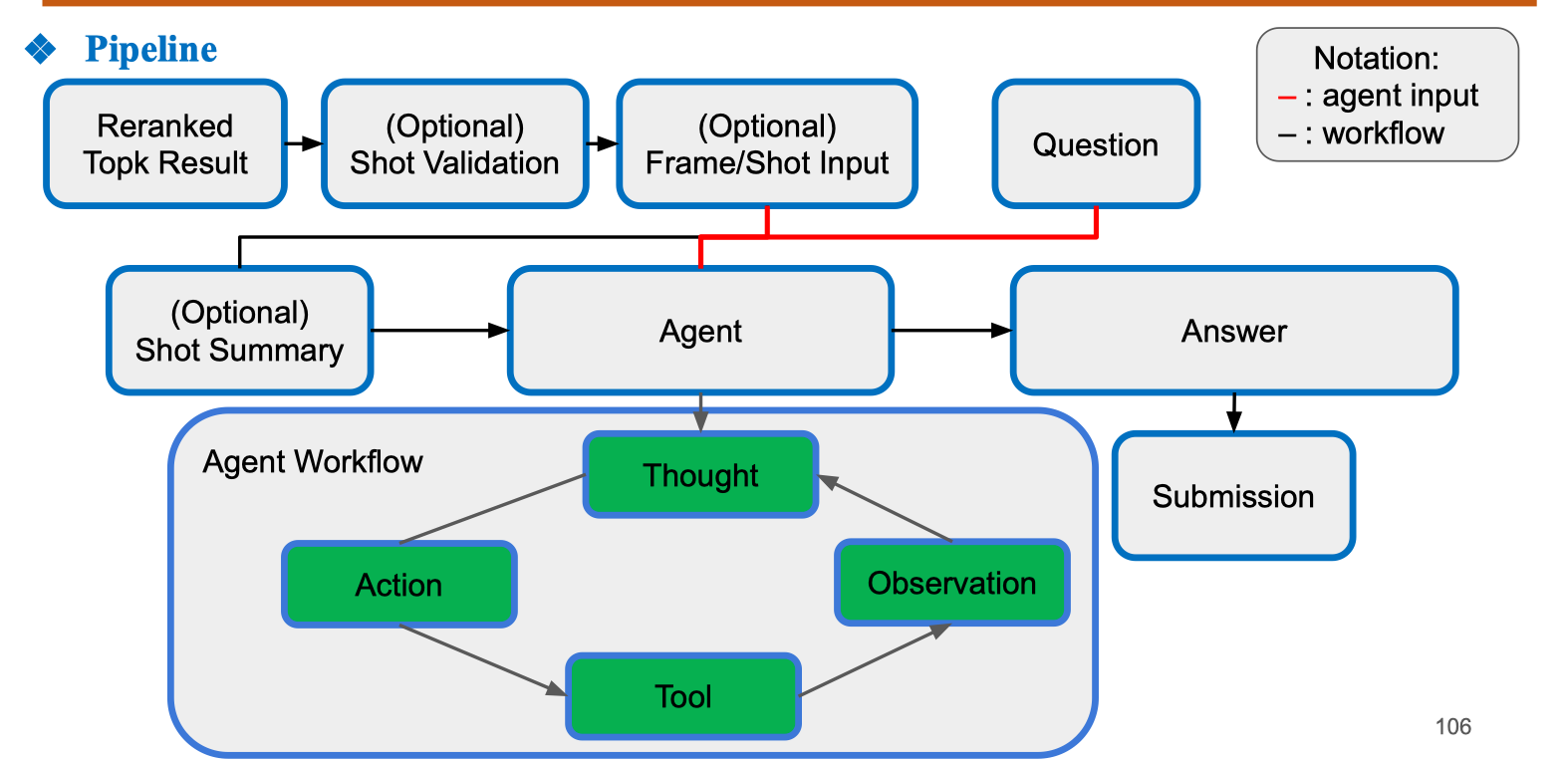 1. Dữ liệu đầu vào
1. Dữ liệu đầu vào
- Reranked Top-k Result: tập các kết quả khung hình/đoạn video đã được xếp hạng lại từ bước tìm kiếm ban đầu.
- (Optional) Shot Validation: kiểm tra lại độ chính xác của các shot video.
- (Optional) Frame/Shot Input: trích xuất khung hình hoặc đoạn video cụ thể để phân tích.
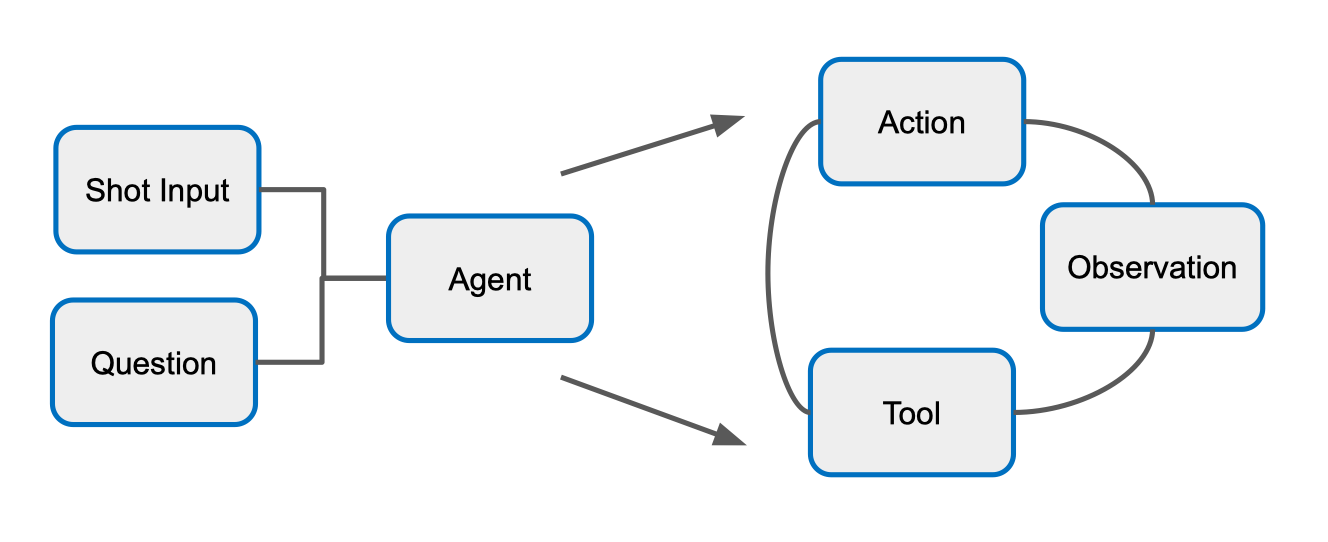
- Question: câu hỏi tự do liên quan đến nội dung video. 2. Agent Agent là thành phần trung tâm, nhận:
- Dữ liệu video (khung hình, shot, audio nếu có).
- Câu hỏi.
- Tóm tắt shot (nếu có). Agent sẽ thực hiện vòng lặp Reason + Act (ReAct) để trả lời câu hỏi. 3. Agent Workflow Bên trong Agent, workflow diễn ra tuần tự:
- Thought: mô hình sinh ra suy luận nội bộ (Reasoning trace).
- Action: dựa trên suy luận, Agent chọn hành động cần làm (vd: phân tích khung hình, dùng OCR, tìm kiếm thông tin).
- Tool: thực hiện hành động bằng công cụ cụ thể (model vision, speech-to-text, knowledge base,…).
- Observation: nhận kết quả trả về từ công cụ.
- Lặp lại quá trình Thought → Action → Tool → Observation cho đến khi đủ thông tin để trả lời. 4. Output
- Answer: câu trả lời ngắn gọn, có thể là văn bản tự do hoặc chọn từ tập từ vựng có sẵn.
- Submission: câu trả lời được gửi làm kết quả cuối.
Shot validation
- Base method: Lấy Top-1 frame (khung hình xếp hạng cao nhất) làm input cho agent.
- Vấn đề: Top-1 frame không phải lúc nào cũng chứa ground truth shot (đoạn hình thực tế cần thiết để trả lời đúng).
- Yêu cầu cải tiến: Cần phát triển một cơ chế lựa chọn sao cho agent có thể tìm và chọn đúng ground truth shot thay vì chỉ dựa vào Top-1.

Dùng LLM để Reranking:
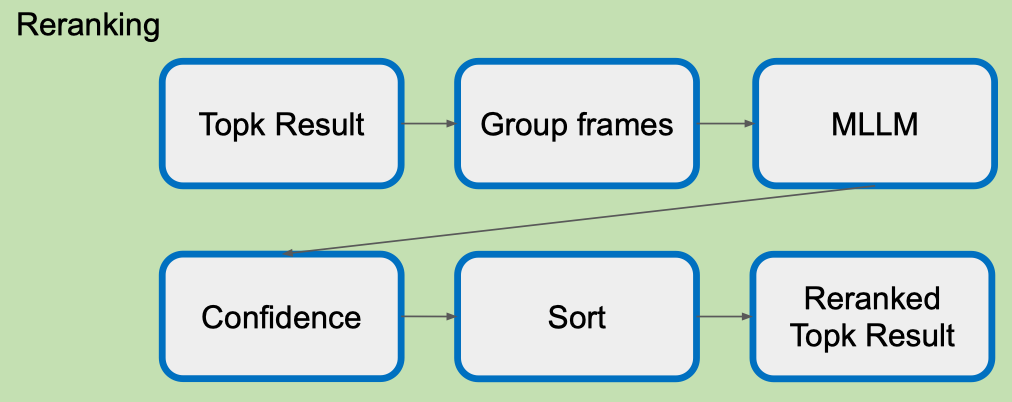
- Topk Result: Nhận danh sách các kết quả ban đầu (Top-k frames) từ bước tìm kiếm trước đó.
- Group frames: Gom các frame liên quan thành nhóm để xử lý ngữ cảnh tốt hơn.
- MLLM (Multimodal Large Language Model): Mô hình đa phương thức phân tích các nhóm frame, đánh giá mức độ liên quan đến câu hỏi.
- Confidence: Tính toán điểm tin cậy (confidence score) cho từng kết quả dựa trên phân tích từ MLLM.
- Sort: Sắp xếp các kết quả theo thứ tự điểm tin cậy giảm dần.
- Reranked Topk Result: Xuất ra danh sách Top-k mới đã được xếp hạng lại, dùng cho các bước tiếp theo (ví dụ: Shot Validation hoặc Agent Input).
Frame/Shot Input
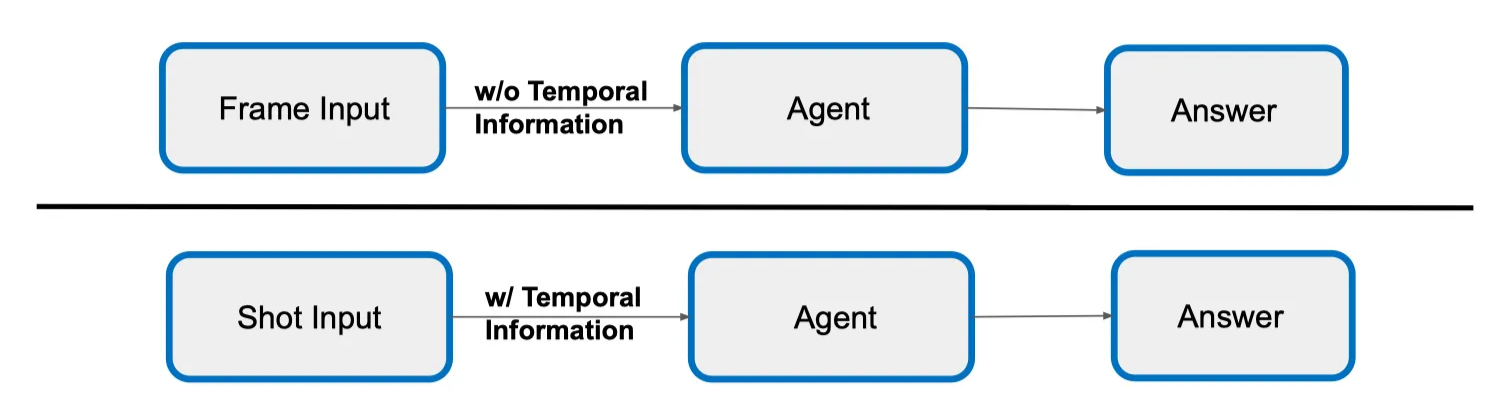
- Frame Input – w/o Temporal Information
- Frame Input: Chỉ cung cấp một hoặc vài khung hình đơn lẻ, không có thông tin về thứ tự thời gian.
- Agent: Xử lý dựa trên nội dung của từng frame độc lập.
- Answer: Đưa ra kết quả nhưng có thể thiếu bối cảnh hoặc mối quan hệ thời gian giữa các sự kiện.
- Ưu điểm: Đơn giản, nhanh.
- Nhược điểm: Có nguy cơ bỏ sót thông tin quan trọng nếu câu trả lời phụ thuộc vào diễn tiến thời gian.
- Shot Input – w/ Temporal Information
- Shot Input: Cung cấp cả đoạn video hoặc chuỗi frame liên tiếp, bao gồm thông tin thời gian và mối liên kết giữa các frame.
- Agent: Phân tích cả nội dung hình ảnh và chuỗi thời gian, giúp nắm bắt ngữ cảnh tốt hơn.
- Answer: Kết quả thường chính xác hơn cho các câu hỏi yêu cầu hiểu diễn biến hoặc hành động.
- Ưu điểm: Giữ nguyên thông tin bối cảnh, mối quan hệ sự kiện.
- Nhược điểm: Yêu cầu nhiều tài nguyên tính toán hơn.
Shot Summary
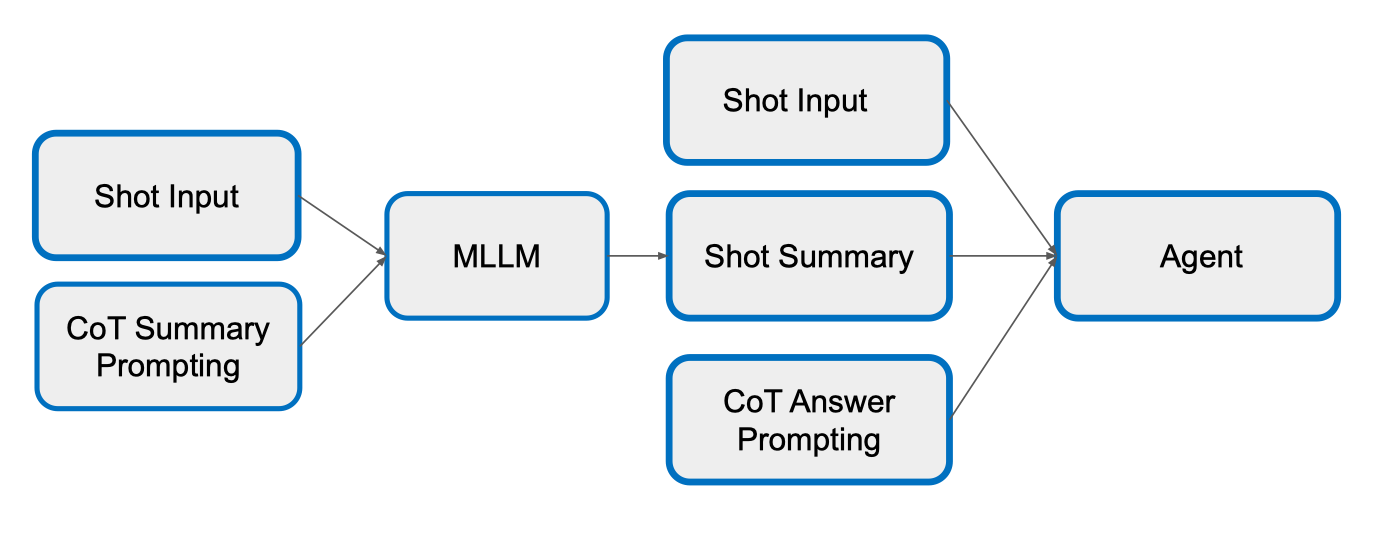
- Shot Input
- Đầu vào là một đoạn video hoặc chuỗi khung hình liên tiếp, giữ nguyên thông tin thời gian.
- CoT Summary Prompting
- Sử dụng kỹ thuật Chain-of-Thought để hướng dẫn mô hình tóm tắt, giúp nó suy luận tuần tự thay vì trả lời ngay.
- MLLM (Multimodal Large Language Model)
- Mô hình ngôn ngữ đa phương thức nhận cả Shot Input và hướng dẫn tóm tắt (CoT Summary Prompting) để sinh ra phần Shot Summary.
- Shot Summary
- Bản tóm tắt ngắn gọn nhưng đầy đủ ngữ cảnh, rút trích từ nội dung của shot.
- CoT Answer Prompting
- Tạo câu hỏi/hướng dẫn trả lời theo phương pháp Chain-of-Thought, dựa trên Shot Summary và các thông tin liên quan.
- Agent
- Nhận đồng thời:
-
Shot Input (giữ thông tin hình ảnh gốc)
-
Shot Summary (cung cấp ngữ cảnh tóm tắt)
-
CoT Answer Prompting (định hướng trả lời)
→ Từ đó đưa ra câu trả lời cuối cùng.
-
- Nhận đồng thời:
Agent