1. Linear Regression
Đọc thêm: Linear regression
Tại sao gọi là Bias: Khi chưa có giá trị các biến (x) thì rõ ràng y = bias. Lúc này hiểu là thiên kiến của model khi chưa có bất kì thông tin gì.
1.1. Area-based house price prediction
Ví dụ với bài toán: Dự đoán giá nhà dựa trên diện tích ta có với weight và bias đã cho giống như trong ảnh dưới ta sẽ có phương trình đường thằng và các giá trị predicted, error:
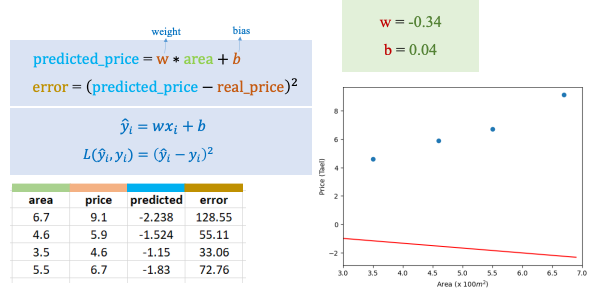
Nếu ta thay đổi weight và bias theo ảnh dưới ta sẽ có được solution mới có error thấp hơn.
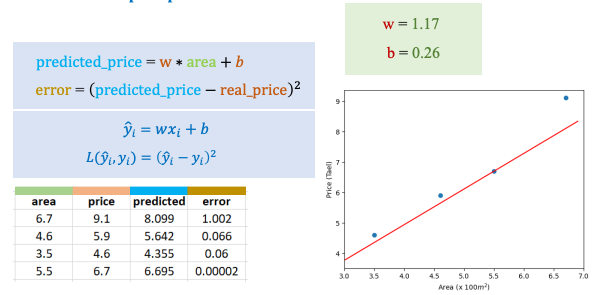
Thật sự thì với bộ weight và bias sẽ gọi là một solution và tất cả solution đều có thể chấp nhận, tuy nhiên chúng ta mong muốn rằng error phải thấp. Vì vậy ở ảnh đầu đây vẫn là một solution chỉ là nó không hiểu quả thôi.
Các bước thực hiện linear regression được thực hiện theo các bước dưới đây:
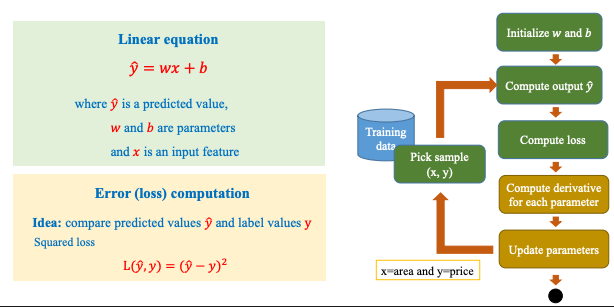
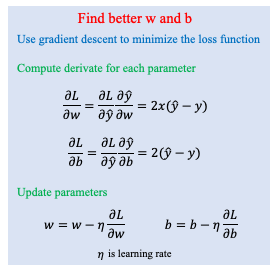
1.2. Ví dụ tính toán Linear Regression:
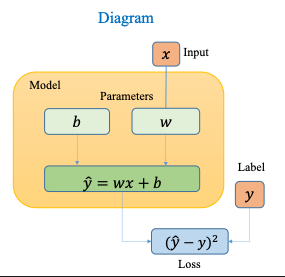
Đây là Diagram cho bài toán Linear Regression:
Iteration đầu tiên:
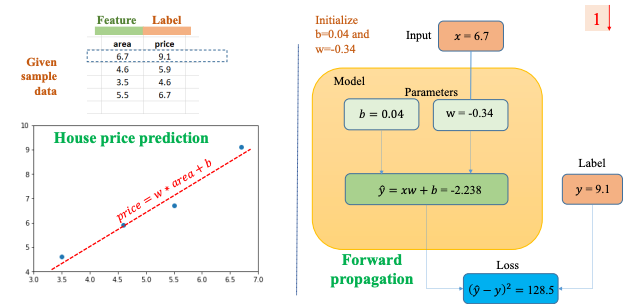
Từ Input x = 6.7 và hai giá trị b = 0.04 và w = -0.34 khởi tạo trước ta tính được = -2.238. Theo Label (giá trị test) thì ta tính được Loss = 128.5
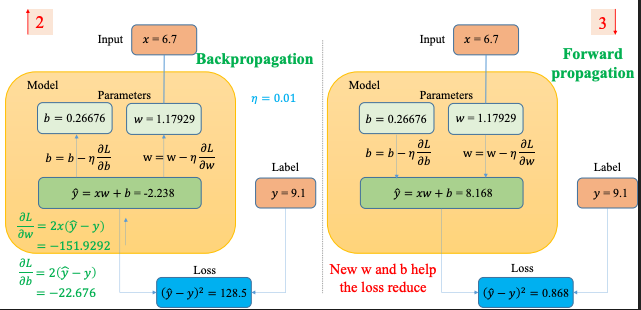
Từ Loss ta cập nhật trọng số sẽ có được b = 0.26676 và w = 1.17929 Bước này có thể gọi là Backpropagation
Sau đó với giá trị b và w mới ta tính lại → Đây là Forward propagation
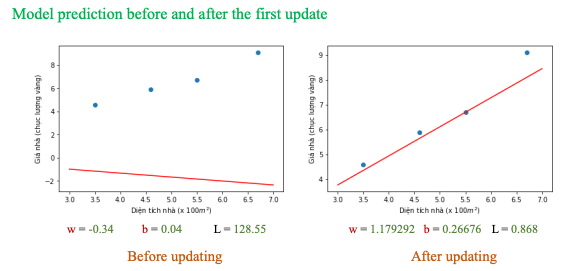
Sau khi update b và w dần dần ta sẽ có:
1.3. Computation graph
Computation Graph (đồ thị tính toán) là một cách biểu diễn trực quan quá trình tính toán của một hàm toán học phức tạp dưới dạng đồ thị có hướng (DAG – Directed Acyclic Graph). Trong đồ thị này:
- Nút (node): biểu diễn toán hạng (số, vector, ma trận) hoặc một phép toán (cộng, nhân, hàm sigmoid, ReLU…).
- Cạnh (edge): biểu diễn luồng dữ liệu (giá trị đầu ra của phép toán này là đầu vào của phép toán khác). Mục đích của computation graph
- Theo dõi luồng dữ liệu: Biết được giá trị nào phụ thuộc vào giá trị nào.
- Tự động vi phân (autograd): Dễ dàng áp dụng quy tắc dây chuyền (chain rule) để tính đạo hàm. Đây là cơ sở cho backpropagation trong deep learning.
- Tối ưu hóa tính toán: Framework ML (TensorFlow, PyTorch) có thể tối ưu việc tính toán dựa trên đồ thị.
Ví dụ: Trong bài Linear regression này
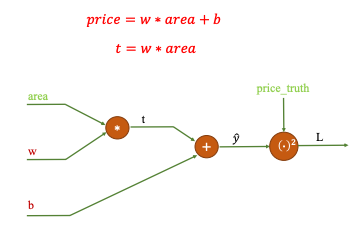 Các phép tính thực hiện trên Computation Graph ở iteration 1
Các phép tính thực hiện trên Computation Graph ở iteration 1

2. Mini-batch Training
Mini-batch training trong Linear Regression (và các mô hình học máy khác) là một kỹ thuật huấn luyện mô hình bằng cách chia tập dữ liệu lớn thành nhiều nhóm nhỏ (batch) — gọi là mini-batches — và cập nhật tham số sau mỗi batch thay vì sau từng mẫu (SGD) hay toàn bộ dữ liệu (Batch Gradient Descent).
| Lý do | Giải thích |
|---|---|
| Tối ưu tốc độ | Tận dụng tính song song của GPU/CPU để xử lý vector/matrix hiệu quả hơn. |
| Giảm dao động | So với SGD, trung bình trên batch giúp gradient ổn định hơn. |
| Tránh overfitting nhẹ | Batch nhỏ tạo nhiễu tự nhiên → giúp mô hình generalize tốt hơn. |
| Dễ điều chỉnh learning rate | Các thuật toán tối ưu như Adam, RMSProp hoạt động hiệu quả hơn với mini-batch. |
| Thực tế bắt buộc | Dataset lớn không thể load hết vào RAM/GPU, cần chia nhỏ để huấn luyện tuần tự. |
Các cách huấn luyện Giả sử ta có hàm mất mát cho Linear Regression: (a) Batch Gradient Descent
- Dùng toàn bộ tập dữ liệu để tính gradient mỗi lần cập nhật:
- Ưu: kết quả ổn định.
- Nhược: rất chậm nếu dữ liệu lớn.
(b) Stochastic Gradient Descent (SGD)
- Dùng chỉ 1 mẫu dữ liệu mỗi lần cập nhật:
- Ưu: nhanh, liên tục cập nhật.
- Nhược: nhiễu mạnh, dễ dao động quanh cực tiểu.
(c) Mini-Batch Gradient Descent (kết hợp 2 cách trên)
- Chia dữ liệu thành các mini-batch (ví dụ: 32, 64, 128 mẫu).
- Mỗi lần cập nhật, tính gradient trên một batch nhỏ:
với là kích thước batch.
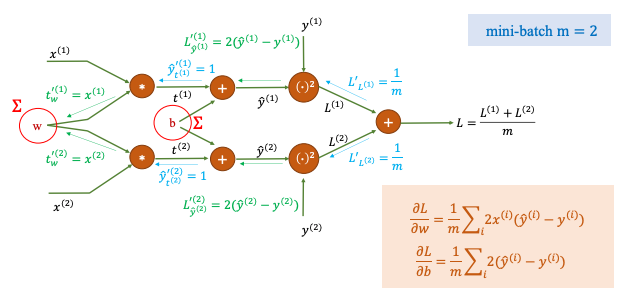
Đây là computation graph cho mini-batch = 2
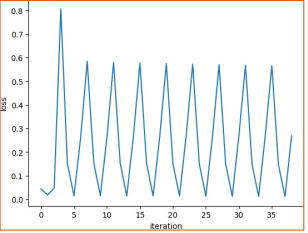
Lưu ý trong train model thực tế người ta không hay dùng early stop mà chủ yếu là quan sát, nếu loss còn giảm thì sẽ còn tiếp tục cho chạy.