1. Giới thiệu
Khi huấn luyện một mô hình Machine Learning trong môi trường lab, mọi thứ thường khá “đẹp”: dữ liệu sạch, độ sáng ổn định, không có nhiều trường hợp ngoại lệ và hệ thống compute không bị giới hạn. Nhưng ngay khi mô hình được đưa ra thực tế, điều đầu tiên mình nhận thấy là các dự đoán bỗng nhiên thiếu ổn định.
Một ví dụ quen thuộc là việc triển khai một mô hình YOLO để nhận diện công nhân trên công trường: trong môi trường huấn luyện thì mô hình hoạt động rất tốt, nhưng khi ánh sáng thay đổi hoặc camera hơi tối, mô hình lập tức suy giảm hiệu suất.
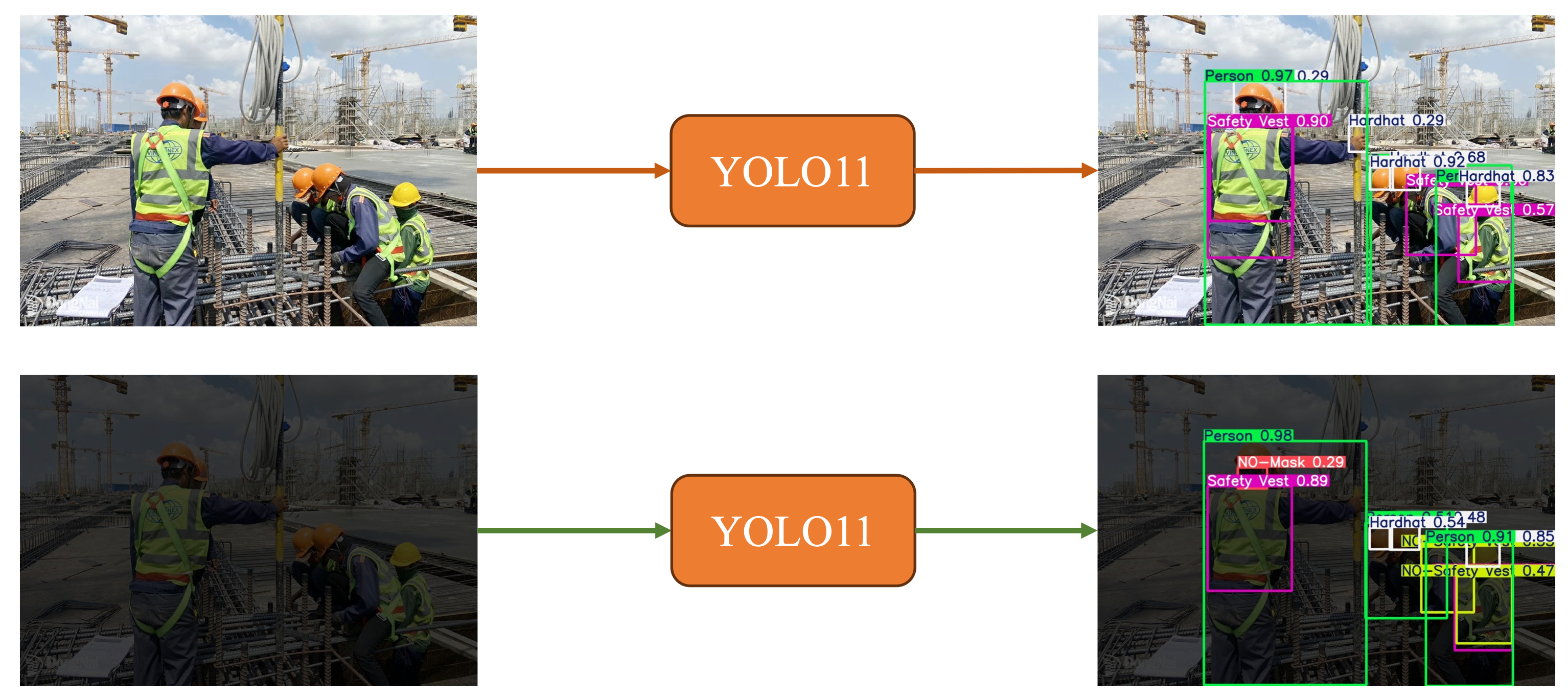
Mình muốn bắt đầu bằng một câu hỏi đơn giản: làm thế nào để biết mô hình ML hoạt động đúng và ổn định theo thời gian? Đây không phải câu hỏi lý thuyết, mà là yêu cầu sống còn của mọi ứng dụng AI trong đời thực. Hãy tưởng tượng backend phục vụ mô hình GPT, nhưng CPU, RAM tăng lên bất thường, số lượng request lỗi tăng mạnh, hoặc input của người dùng bỗng xuất hiện những phân phối khác lạ. Nếu không có cơ chế cảnh báo, mô hình có thể “âm thầm” tạo ra lỗi ngay cả khi vẫn đang chạy bình thường.
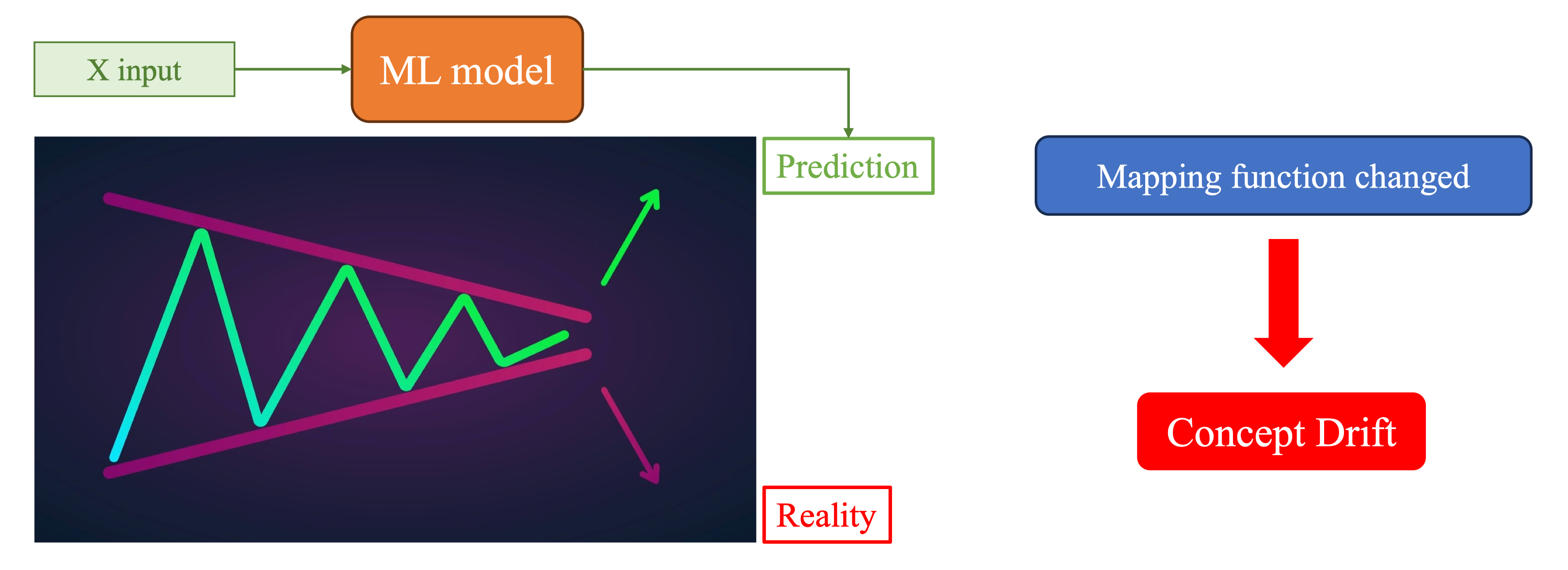
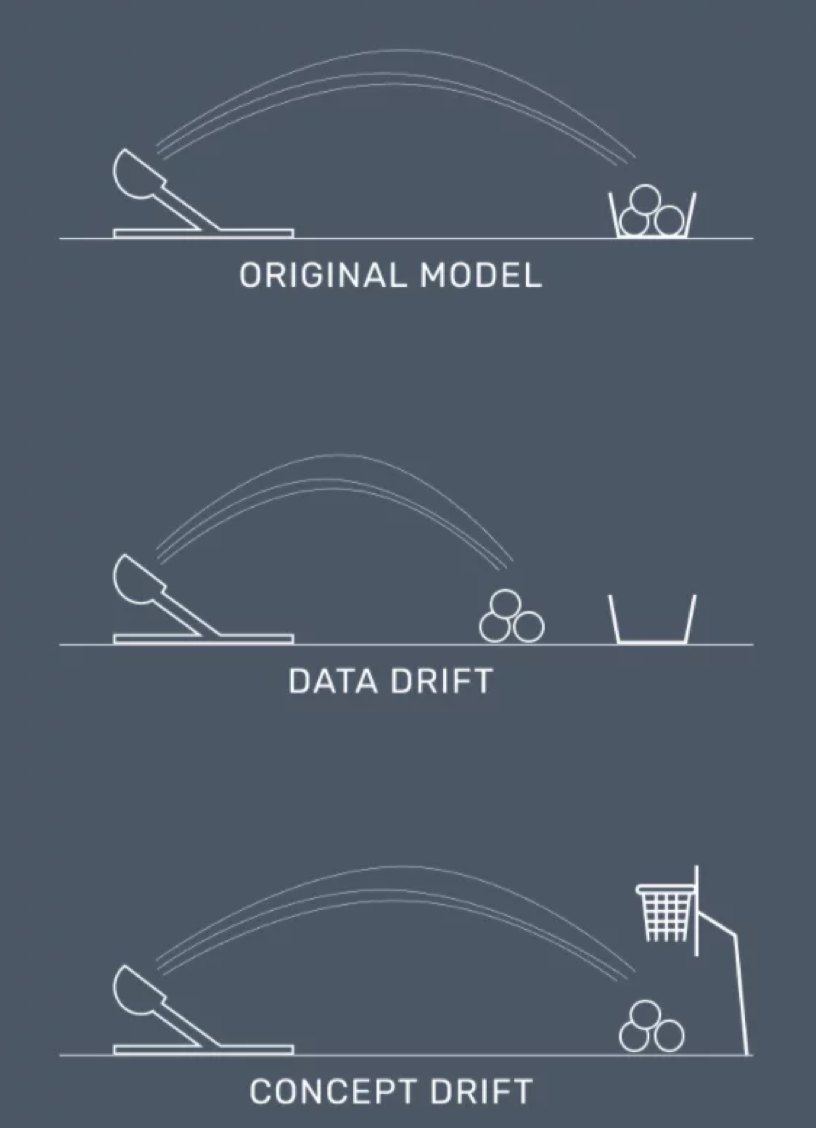
Phần lớn vấn đề bắt đầu từ việc dữ liệu thực tế khác dữ liệu train/val/test. Dữ liệu huấn luyện được thu trong điều kiện chuẩn hóa, còn dữ liệu hiện trường thay đổi liên tục nên mô hình phải đối mặt với data drift (thay đổi phân phối đầu vào) và concept drift (thay đổi mối quan hệ giữa input và output) . Đây chính là điểm khiến mô hình bị sai lệch và cần có hệ thống theo dõi để phát hiện.
Vì vậy, mục tiêu của bài blog này là giúp bạn hiểu một cách trực quan và chậm rãi: tại sao Tracking và Logging lại quan trọng, Prometheus và Grafana giải quyết vấn đề gì, và cách chúng tạo nên hệ thống giám sát trọn vẹn cho MLOps. Mình sẽ đi từ trực giác, tới kiến trúc, rồi triển khai thực nghiệm bằng code và Docker.
1.2. Logging – Metrics – Dashboard
Khi nhìn vào hệ thống thực tế, chúng ta cần ba lớp quan sát cơ bản: Logging, Metrics, và Dashboard . Mỗi lớp đóng vai trò bổ sung lẫn nhau.
Logging giúp mình ghi lại mọi sự kiện trong ứng dụng, bao gồm request đến mô hình, đầu vào bất thường, độ sáng ảnh trung bình hoặc trạng thái hệ thống backend. Đây là lớp quan sát giúp hiểu bối cảnh của mỗi yêu cầu.
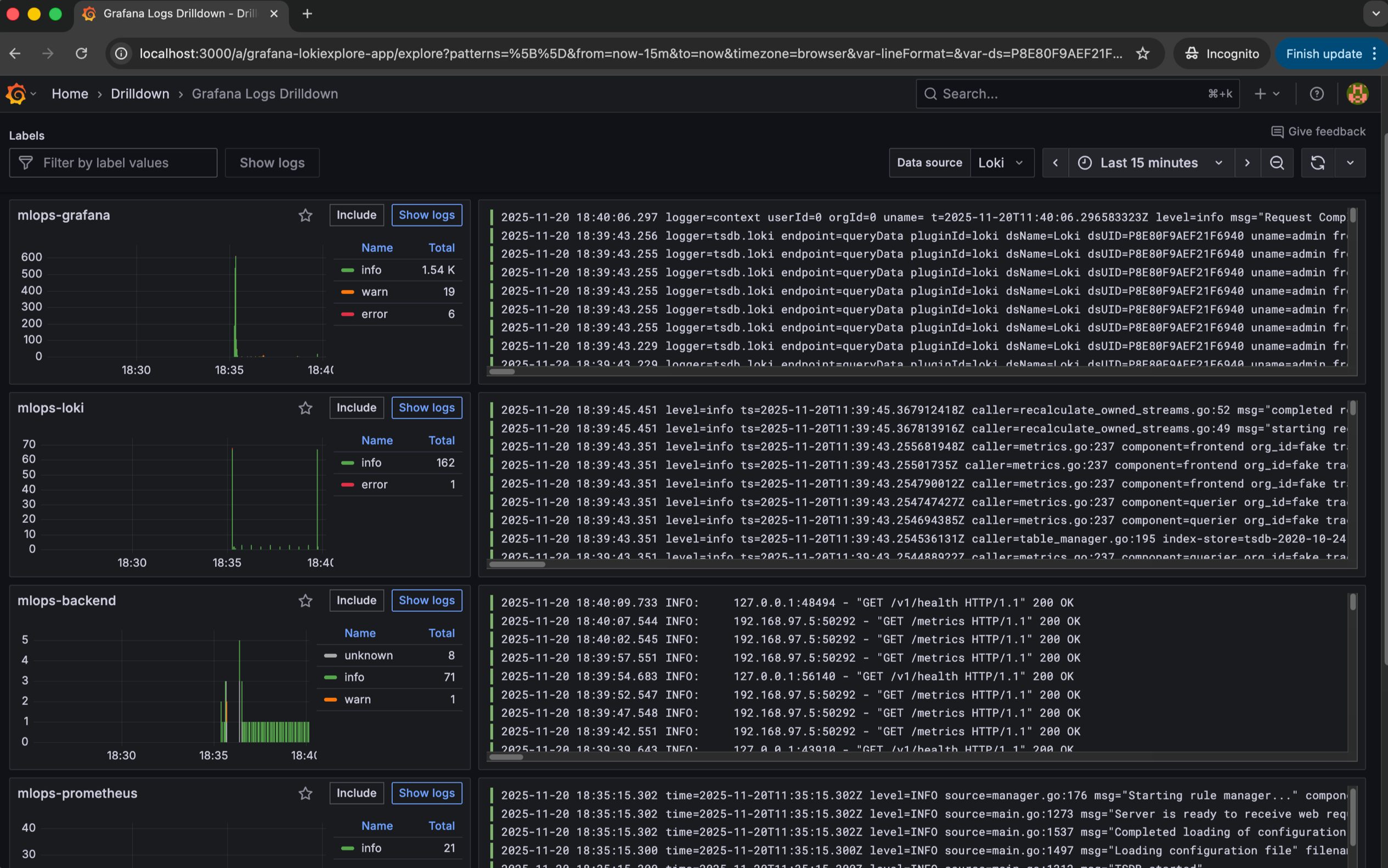
Metrics cho phép theo dõi những con số thay đổi theo thời gian: số request, độ trễ, tỉ lệ lỗi, độ sáng trung bình của ảnh input, hay độ dài văn bản được gửi đến mô hình NLP. Những chỉ số này tạo nên chuỗi thời gian (time series), cho phép ta nhận ra xu hướng và phát hiện drift.
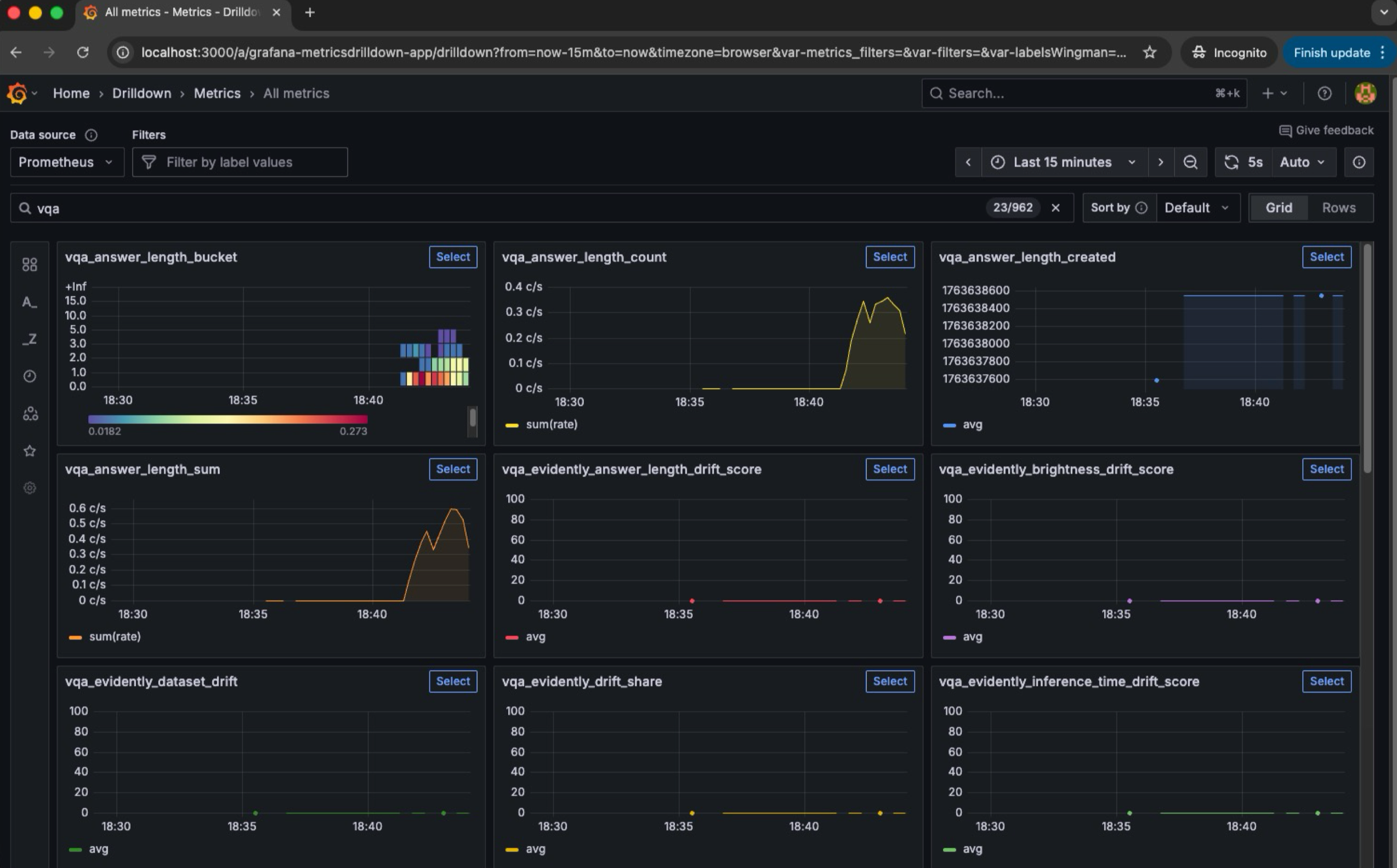
Dashboard giúp trực quan hóa toàn bộ hệ thống. Ảnh dưới trình bày một dashboard mẫu gồm dữ liệu drift, latency, số lượng request theo thời điểm, phân phối input, và tỉ lệ lỗi trên tổng số truy cập . Một dashboard tốt không chỉ hiển thị thông tin, mà còn giúp nhóm vận hành suy luận xem điều gì đang sai.
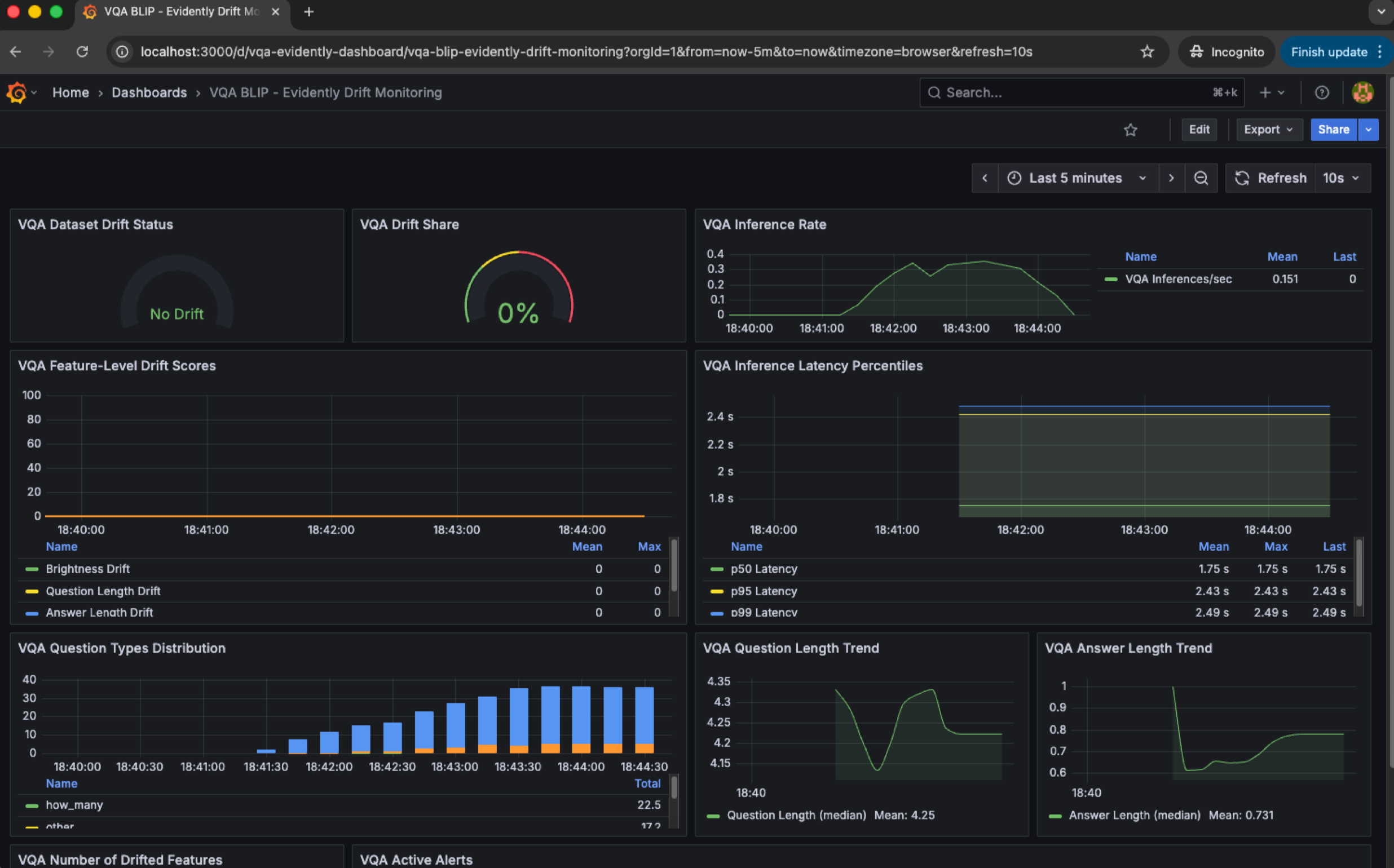
Kết hợp ba lớp này tạo nên một cơ chế quan sát toàn diện: quan sát chi tiết theo từng hành động (logging), theo dõi xu hướng theo thời gian (metrics), và phân tích hệ thống qua biểu đồ (dashboard).
1 .3. Data Distribution Changed và cách phát hiện
Trong quá trình deploy, backend nhận dữ liệu từ môi trường mà ta không thể kiểm soát. Đây chính là nguồn gốc của data drift và concept drift.
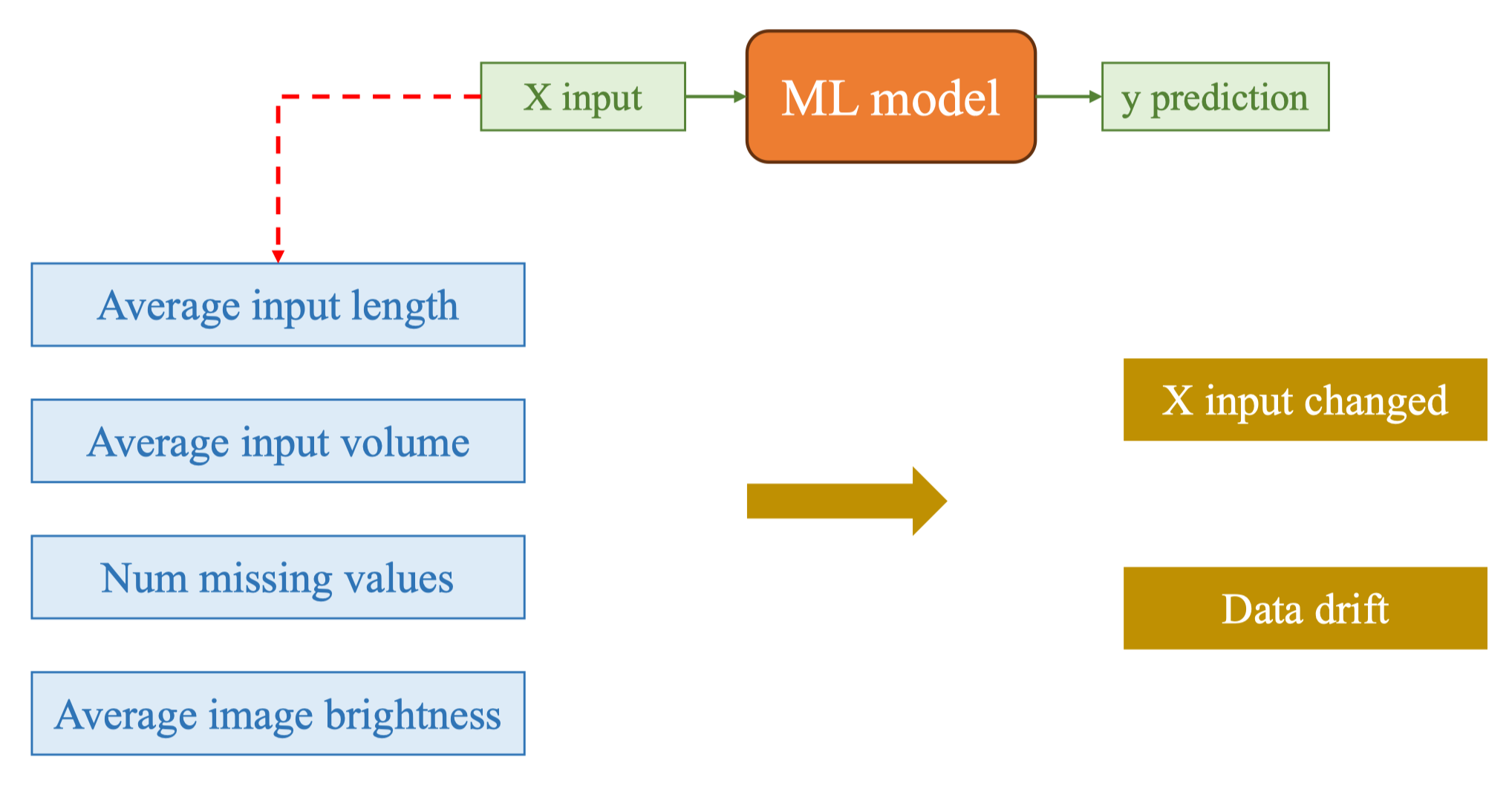
Data drift xảy ra khi thống kê của đầu vào thay đổi: độ sáng trung bình tăng lên, số pixel tối xuất hiện nhiều hơn, tỉ lệ missing values cao hơn, hoặc độ dài văn bản khác nhiều so với tập huấn luyện.
Concept drift xảy ra khi mô hình dự đoán sai ngay cả khi input vẫn giống trước đây. Ví dụ: ảnh chụp công nhân vẫn đúng điều kiện ánh sáng, nhưng mô hình không còn nhận diện đúng vì quy tắc an toàn trang phục tại công trường đã thay đổi.
Vậy làm sao để phát hiện drift? Mình cần theo dõi:
-
Các thống kê đầu vào như độ sáng, số pixel, độ dài văn bản.
-
Các thống kê đầu ra như tần suất NULL, số lần người dùng infer lại, số lần người dùng chuyển sang mô hình khác (slide trang 21).
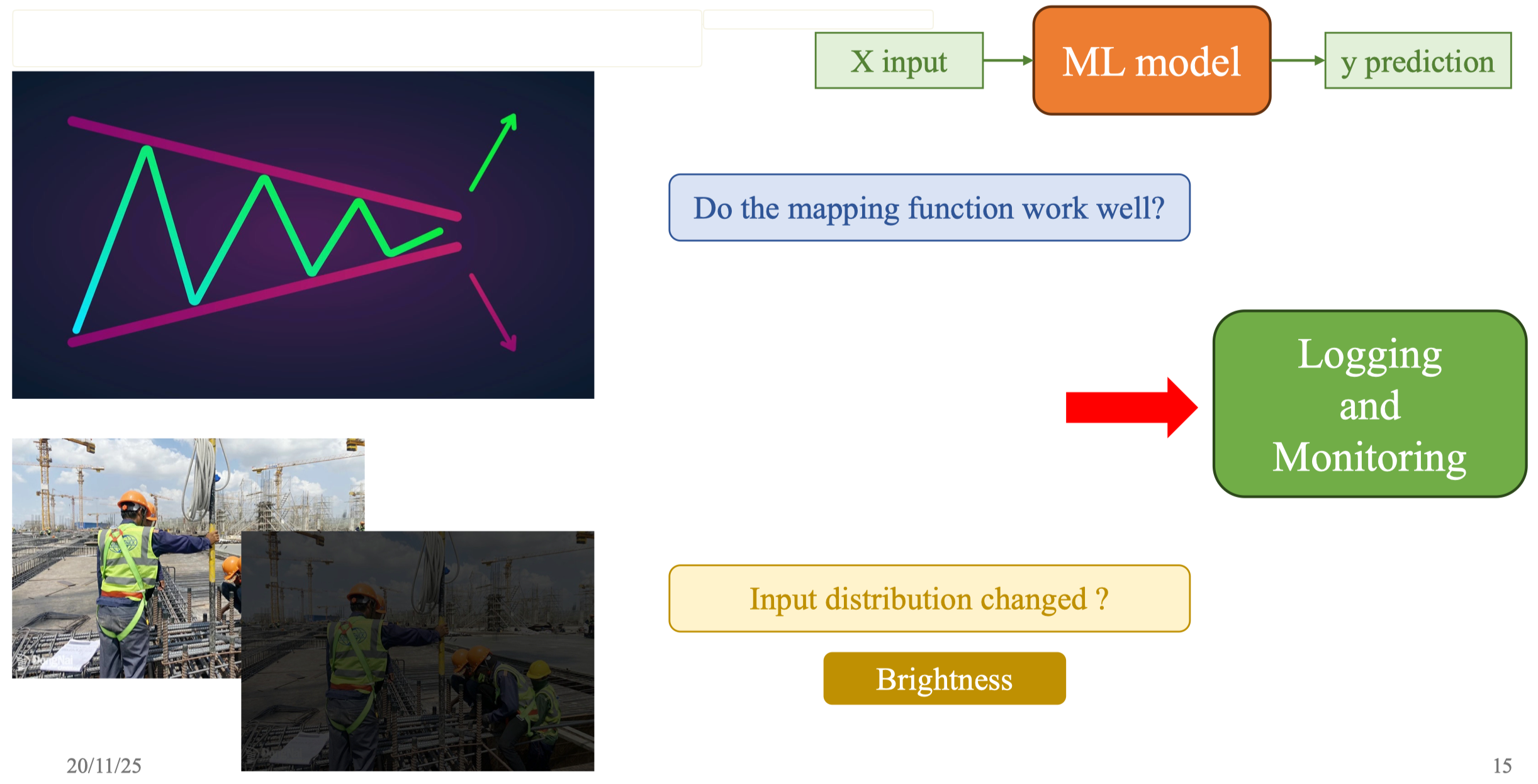
Những con số này được gửi vào hệ thống metrics (Prometheus), rồi hiển thị trên dashboard (Grafana). Khi giá trị vượt quá ngưỡng bình thường, alert được kích hoạt qua Alertmanager.
1.4. Blackbox Monitoring và Whitebox Monitoring
Hai khái niệm này là nền tảng quan trọng để hiểu cách hệ thống monitoring hoạt động trong MLOps.
Blackbox monitoring quan sát từ bên ngoài. Nó đo CPU, GPU, RAM, load average, uptime của service… Đây đều là chỉ số hệ thống, không cần chạm vào code của mô hình. Trong ML, blackbox monitoring giúp mình biết backend đang có vấn đề tài nguyên hay không.
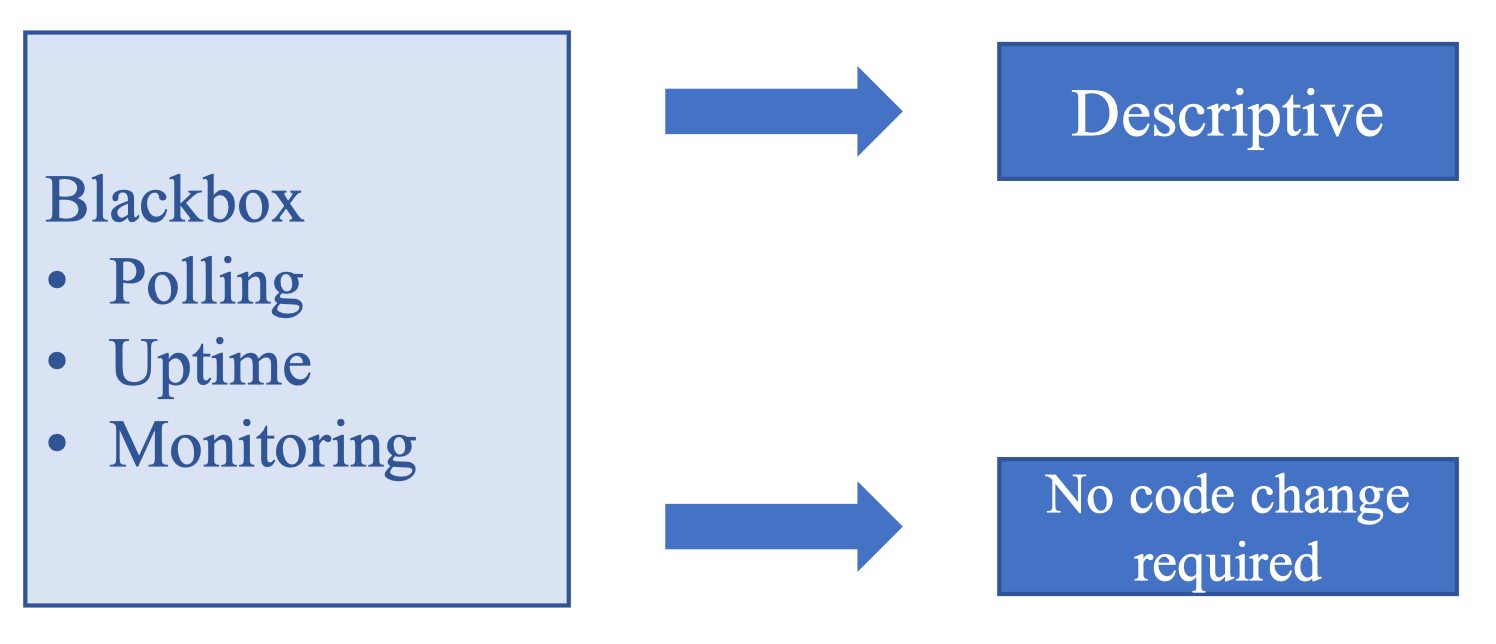
Whitebox monitoring quan sát từ bên trong. Đây là dạng giám sát mà chính code ứng dụng gửi metrics ra ngoài: số request, tỉ lệ lỗi, độ trễ, độ sáng ảnh input, phân phối dữ liệu, hoặc số lần infer lại. Đây là phần “ML-aware”, giúp mình theo dõi drift.
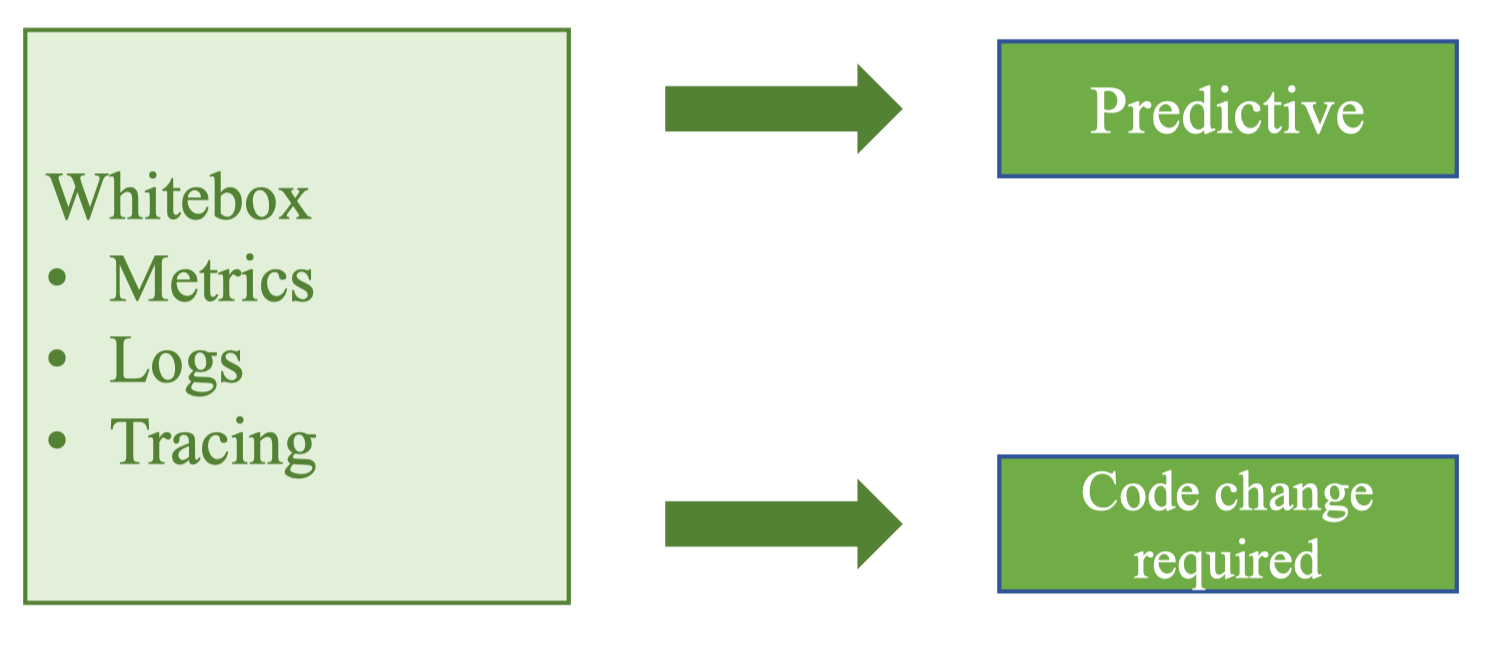
Sự kết hợp giữa hai loại monitoring giúp mình phân biệt: mô hình sai do tài nguyên, hay dữ liệu thay đổi, hay concept bị drift.
1.5. Giải pháp: Prometheus và Grafana
Prometheus và Grafana là hai thành phần xuất hiện trong hầu hết hệ thống MLOps thực tế. Lý do là vì chúng rất phù hợp với đặc thù của ML:
-
Prometheus thu thập dữ liệu theo mô hình pull, phù hợp với các service ML có endpoint metrics.
-
PromQL cho phép phân tích chuỗi thời gian để phát hiện drift.
-
Grafana trực quan hóa phân phối input, độ sáng ảnh, latency, và drift score.
-
Loki giúp xem lại log để phân tích lỗi chi tiết.
Với những mô hình phức tạp như YOLO hoặc GPT, việc có một hệ thống monitoring mạnh sẽ giúp team phát hiện sớm vấn đề và phản ứng kịp thời trước khi ảnh hưởng đến người dùng thật.
2. Prometheus
Vậy tại sao lại là Prometheus cho hệ thống giám sát mô hình ML?
Câu trả lời nằm ở cấu trúc thời gian thực của bài toán MLOps. Mô hình cần theo dõi liên tục các chỉ số như số request, độ trễ, độ sáng ảnh input, tỉ lệ NULL output, hoặc phân phối kích thước văn bản người dùng gửi vào. Tất cả những thứ này đều là dạng time series, và Prometheus sinh ra để lưu trữ chúng một cách hiệu quả nhất.
 Trang chủ Prometheus: https://prometheus.io/
Trang chủ Prometheus: https://prometheus.io/
2.1. Giới thiệu về Prometheus
Prometheus được giới thiệu đầu tiên bởi SoundCloud vào năm 2012, sau đó trở thành một dự án độc lập và được CNCF bảo trợ. Mình có thể hình dung Prometheus giống như một “máy quét” thời gian thực, liên tục đi qua hệ thống ML, gửi yêu cầu đến các endpoint /metrics của backend, lấy về các chỉ số và ghi vào cơ sở dữ liệu dạng time series.

Điều quan trọng mình muốn nhấn mạnh ở đây là Prometheus không yêu cầu mình phải xây dựng một pipeline dữ liệu phức tạp. Thay vì gửi dữ liệu chủ động, ứng dụng chỉ cần mở một endpoint chứa số liệu, và Prometheus sẽ tự động lấy dữ liệu theo chu kỳ. Trong MLOps, điều này rất phù hợp vì:
-
Mô hình ML thường chạy dưới dạng API service.
-
Việc thu thập metrics qua HTTP rất dễ tích hợp.
-
Mình có toàn quyền định nghĩa metrics theo ý muốn (data drift, concept drift, độ sáng ảnh, số lần infer lại).
Prometheus trở thành nền tảng để mình theo dõi “sức khỏe” của mô hình và của cả hệ thống.
Features
Đây là các tính năng chính của Prometheus:
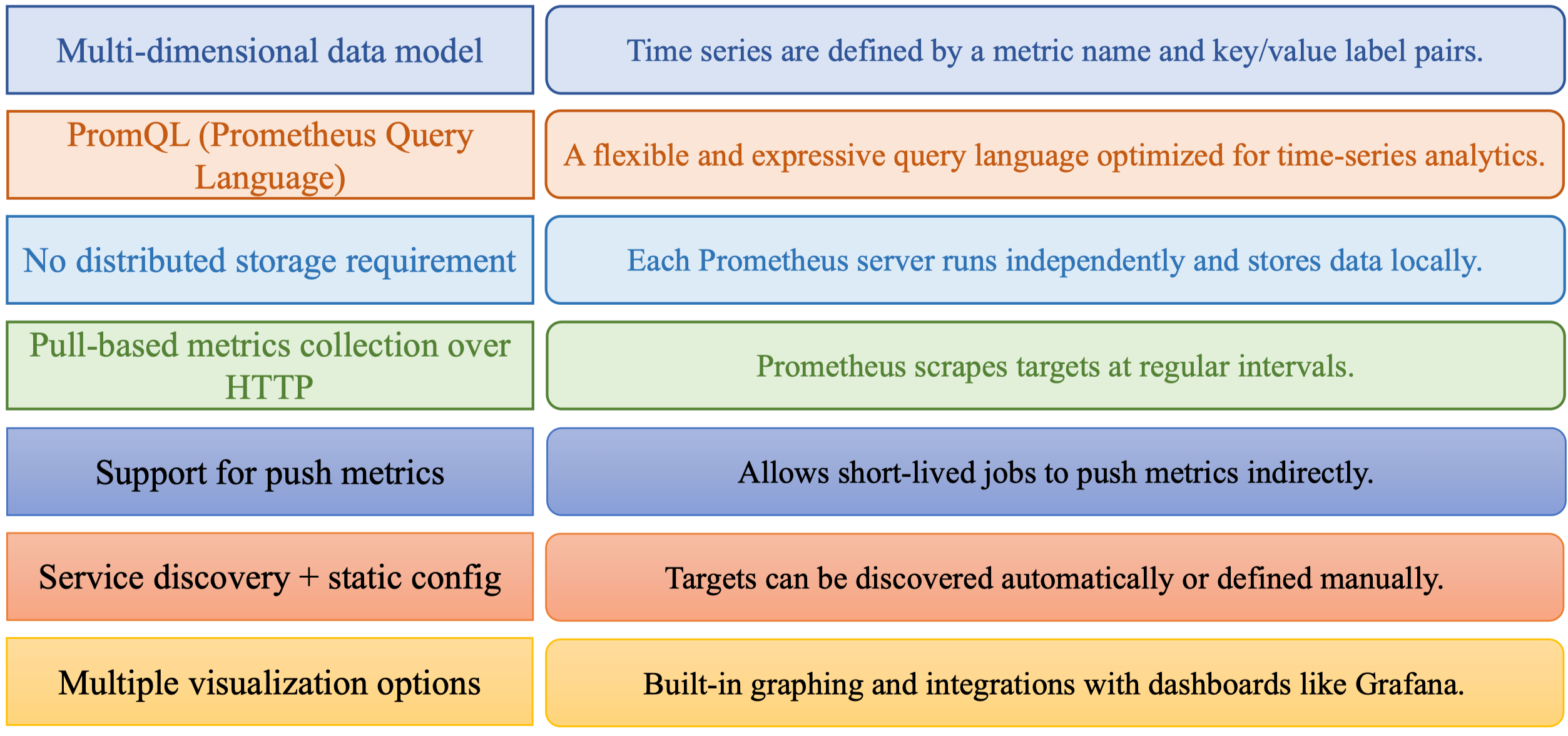
Khi nhìn dưới góc ML engineer, chúng ta có thể cảm nhận rõ ý nghĩa của từng tính năng:
Prometheus có mô hình dữ liệu đa chiều, tức là mỗi metric có nhiều label. Ví dụ: inference_latency_seconds{model="yolo11", status="success"}. Việc có thể gắn label như vậy rất phù hợp với MLOps, vì có thể theo dõi latency theo model, theo endpoint, hoặc theo thiết bị người dùng.
PromQL là ngôn ngữ cực kỳ mạnh, giúp truy vấn những câu hỏi như “độ sáng ảnh input có tăng dần theo thời gian không?” hoặc “số lượng request lỗi 500 có tăng bất thường từ 8h đến 9h sáng hay không?”.
Prometheus cũng không yêu cầu distributed storage, giúp hệ thống gọn nhẹ hơn khi chưa cần mức scale doanh nghiệp. Khi cần lưu trữ dài hạn, mình có thể đẩy ra remote storage sau.
Components
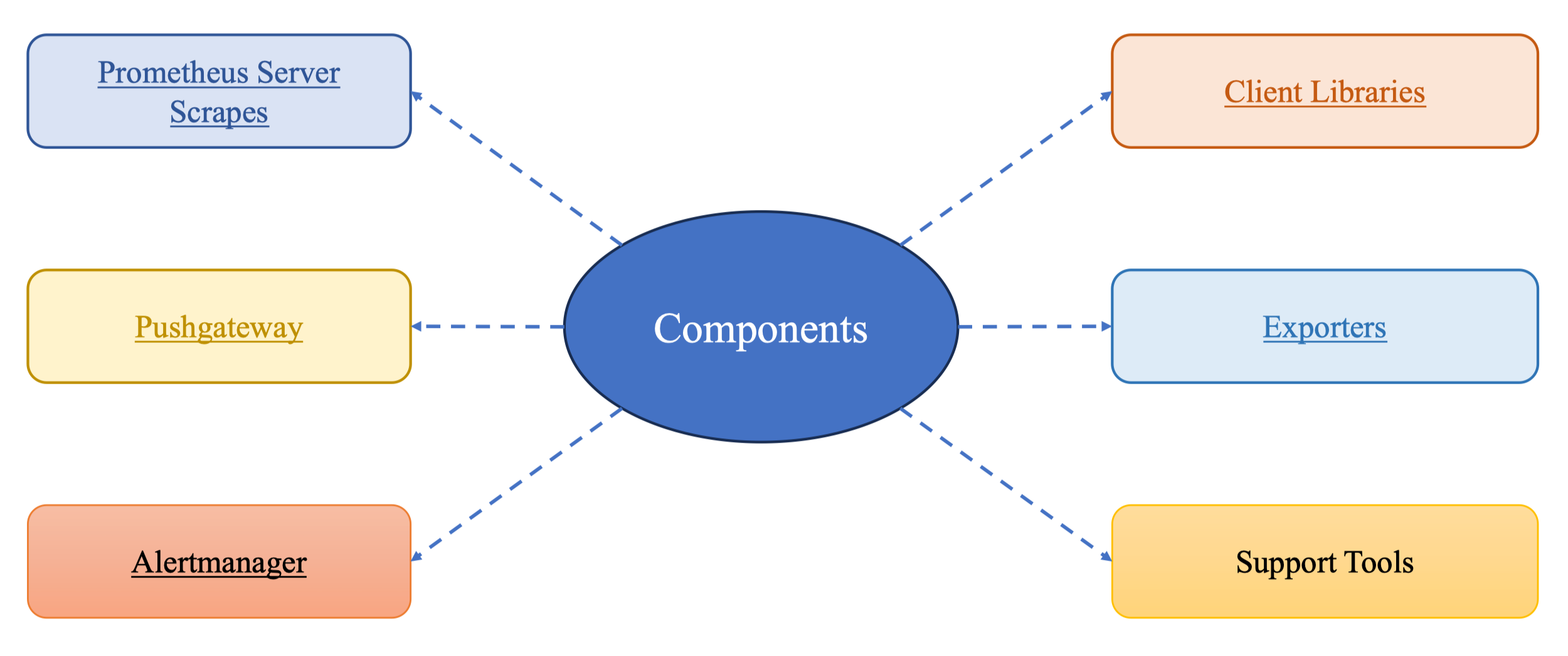
Bốn thành phần chính của Prometheus là: Prometheus server, Client Libraries, Exporters, Pushgateway và Alertmanager. Nhưng trong bối cảnh MLOps, thành phần quan trọng nhất là:
-
Prometheus server, nơi lưu time-series và thực thi PromQL.
-
Client libraries (Python) để mình nhúng metrics trực tiếp vào code model inference.
-
Alertmanager để kích hoạt cảnh báo khi drift vượt ngưỡng.
Pushgateway chỉ dùng khi có job ngắn như batch training, còn exporters dùng cho hệ thống OS như CPU/GPU.
Architecture
Sơ đồ kiến trúc đầy đủ:
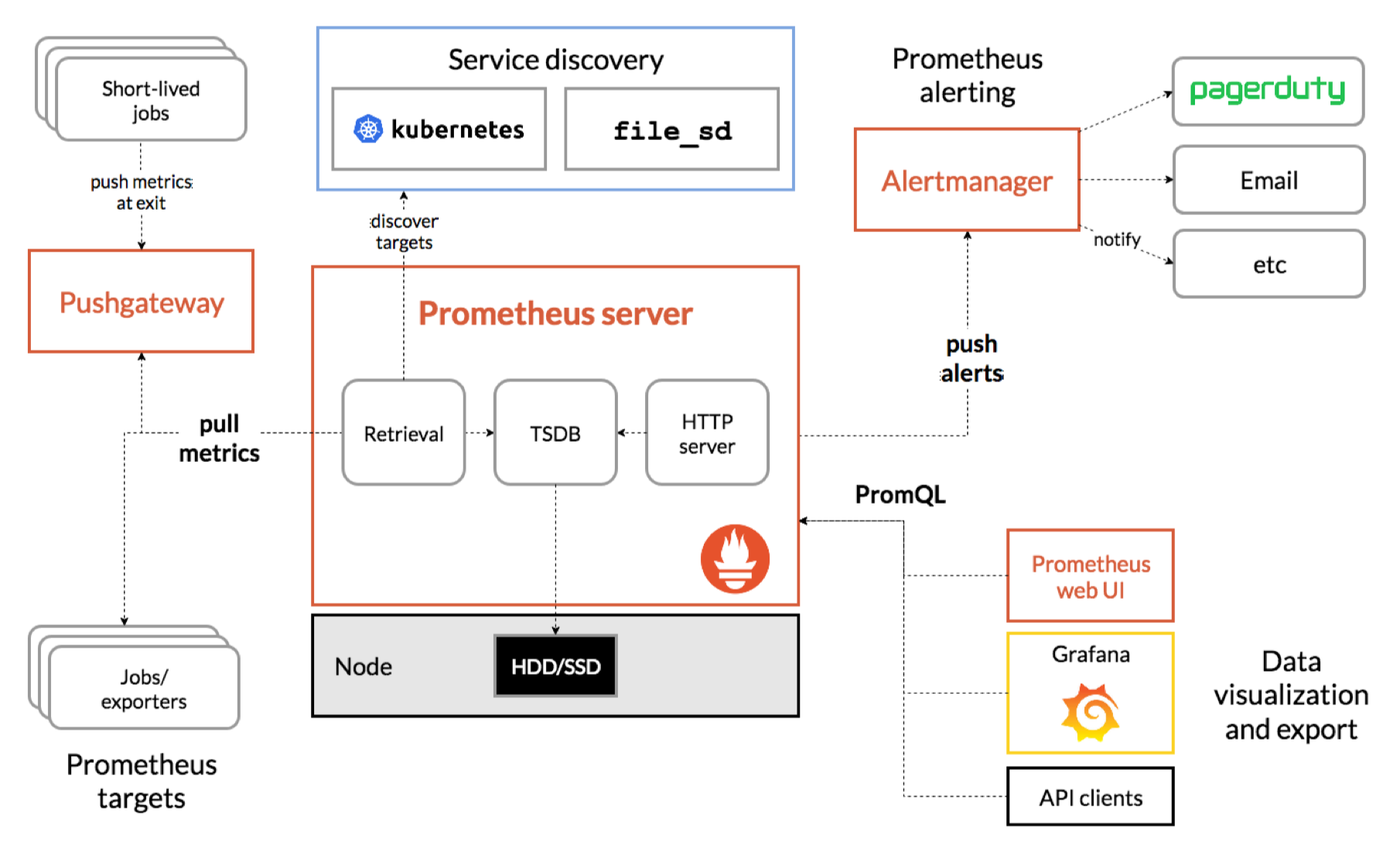
Nếu diễn giải theo dòng chảy:
-
Prometheus sử dụng Service Discovery để tìm các instance backend ML.
-
Server gửi yêu cầu “pull” đến các target.
-
Target trả về metrics theo định dạng text.
-
Prometheus lưu trữ vào TSDB.
-
PromQL cung cấp giao diện truy vấn dữ liệu.
-
Alertmanager nhận các cảnh báo khi điều kiện được thỏa.
-
Các dashboard như Grafana đọc dữ liệu từ Prometheus.
Prometheus không can thiệp vào ứng dụng ML, mà chỉ đọc dữ liệu từ endpoint. Chúng ta toàn quyền định nghĩa metrics theo mô hình và nhu cầu thực tế.
2.2. Data model
Prometheus lưu mọi dữ liệu dưới dạng time series, bao gồm metric name và một nhóm label. Nhờ có label, mình có thể phân tích drift theo nhiều chiều.
Ví dụ khi theo dõi độ sáng ảnh input:
input_brightness_avg{camera="cam01"} 0.82
input_brightness_avg{camera="cam02"} 0.45Nhìn vào chuỗi này, mình có thể dễ dàng phát hiện camera nào đang gặp vấn đề ánh sáng dẫn đến sai lệch dữ liệu. Trong MLOps, đây là bước quan trọng để xác định data drift theo nguồn dữ liệu.
Prometheus phía server không quan tâm đến metric type, mà chỉ lưu giá trị theo thời gian. Điều này giúp toàn bộ hệ thống trở nên đơn giản nhưng cực kỳ linh hoạt.
2.3. Metric Types
Prometheus định nghĩa bốn loại metrics: Counter, Gauge, Histogram và Summary. Mỗi loại mang một ý nghĩa trực giác quan trọng trong MLOps.
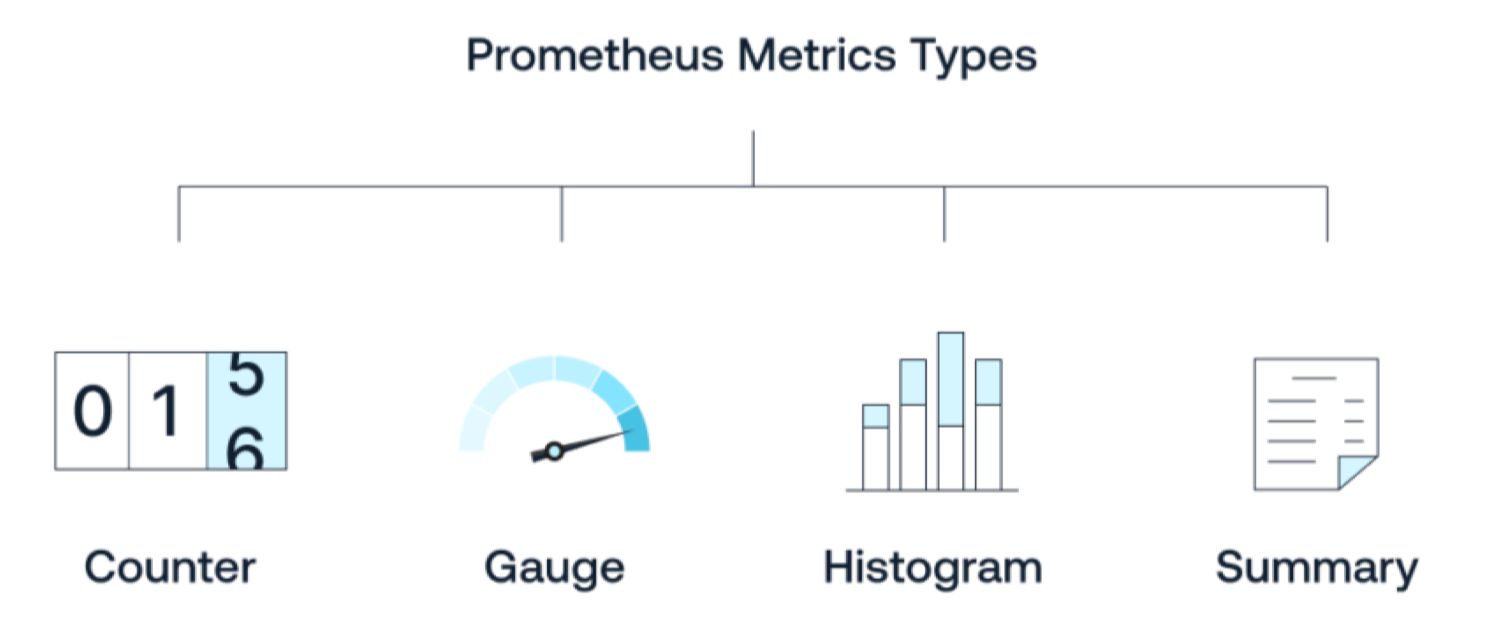
Counter
Counter chỉ tăng lên theo thời gian, thích hợp để đếm số request inference, số lỗi, số lần người dùng phải infer lại, hoặc số lần output là NULL (slide trang 30–31).
Ví dụ mình muốn theo dõi concept drift bằng số lần người dùng chuyển sang model khác:
concept_drift_switch_count.inc()
Khi nhìn biểu đồ theo thời gian, nếu số lần chuyển model tăng cao, có thể mô hình chính đang bị vấn đề.
Gauge
Gauge có thể tăng hoặc giảm, phù hợp để đo giá trị tức thời như độ sáng ảnh input, độ dài văn bản, CPU usage, hoặc số request active.
Trong ML, chúng ta có thể dùng Gauge để theo dõi độ sáng ảnh trung bình mỗi request để phát hiện data drift:
input_brightness_gauge.set(brightness_value)
Histogram
Histogram dùng để lưu phân phối, tức là không chỉ giá trị trung bình, mà cả cấu trúc phân bố (slide trang 34–35). Đây là loại metric hữu ích nhất cho ML vì drift thường xảy ra ở dạng thay đổi phân phối.
Ví dụ mình muốn theo dõi phân phối độ trễ model:
inference_latency.observe(duration)
Nếu đường cong latency dần lệch sang phải, có thể backend bị chậm.
Summary
Summary cũng theo dõi phân phối nhưng tập trung vào quantile (p 90, p 95, p 99), và tính toán ở phía client (slide trang 36). Trong ML, mình dùng Summary để theo dõi latency của mỗi endpoint khi muốn biết p 99 có tăng hay không.
2.4. Prometheus Server
Prometheus server là trái tim của hệ thống. Slide trang 38 cho thấy cách cài đặt bằng Docker. Việc sử dụng Docker rất phù hợp với mô hình ML triển khai dạng container.
Một file docker-compose đơn giản:
services:
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"Prometheus đọc file cấu hình prometheus.yml để biết các target cần scrape.
Configuration
Slide trang 39 minh họa cấu hình bao gồm global scrape interval và danh sách job cần thu thập metrics. Trong ML, mình chỉ cần thêm:
- job_name: "ml_backend"
static_configs:
- targets: ["backend:8000"]
Cứ mỗi 15 giây, Prometheus gửi yêu cầu đến backend ML để thu metrics. Đây là cơ chế quan trọng vì nó không tạo áp lực lên ứng dụng.
Querying (PromQL)
PromQL là công cụ phân tích rất mạnh (slide trang 40). Mình có thể đặt những câu hỏi trực tiếp về drift như:
-
Input sáng trung bình có thay đổi theo thời gian?
-
Tỉ lệ NULL output có tăng trong 24 giờ gần nhất?
-
Độ trễ inference tăng đột ngột từ 3 h sáng?
Một truy vấn ví dụ:
rate(null_output_count[5m])
Điều này giúp mình phát hiện concept drift theo logic ứng dụng.
Storage
Prometheus lưu dữ liệu dưới dạng TSDB trên máy local (slide trang 41). Với hệ thống ML nhỏ hoặc trung bình, đây là lựa chọn hợp lý. Khi cần lưu dài hạn, mình có thể tích hợp remote storage như Thanos hoặc Cortex.
Visualization
Slide trang 42 cho thấy Prometheus có giao diện frontier để chạy query và xem biểu đồ. Tuy nhiên, khi muốn xây dashboard MLOps, mình thường dùng Grafana vì khả năng trực quan hóa tốt hơn. Prometheus UI phù hợp để debug nhanh, xem metric raw hoặc xác minh kết quả truy vấn PromQL.
3. Alertmanager
Khi hệ thống ML bắt đầu vận hành ổn định, điều mình quan tâm không chỉ là theo dõi dashboard mà còn là nhận cảnh báo khi có sự cố. Một mô hình chịu tải lớn trong môi trường thực tế không thể trông chờ vào việc DevOps hay ML engineer mở dashboard liên tục. Vì vậy, cần có một cơ chế tự phát hiện bất thường và gửi cảnh báo ngay lập tức. Đó là vai trò của Alertmanager, một thành phần được thiết kế để quản lý toàn bộ vòng đời cảnh báo mà Prometheus tạo ra. Trong MLOps, đây là mảnh ghép cần thiết giúp mô hình không âm thầm sai lệch mà không ai biết.
Hệ thống cảnh báo được chia làm hai phần: Prometheus server chịu trách nhiệm đánh giá các điều kiện alert dựa trên metric, còn Alertmanager chịu trách nhiệm nhận những cảnh báo đó và quyết định cách gửi đi. Nhờ cơ cấu tách rời này, mình có thể định nghĩa logic cảnh báo trong Prometheus dưới dạng PromQL, đồng thời cấu hình quy tắc gửi thông báo trong Alertmanager thông qua tệp cấu hình. Điều này mang đến sự linh hoạt lớn khi xây dựng một hệ thống ML cần nhiều ngưỡng và loại cảnh báo khác nhau.
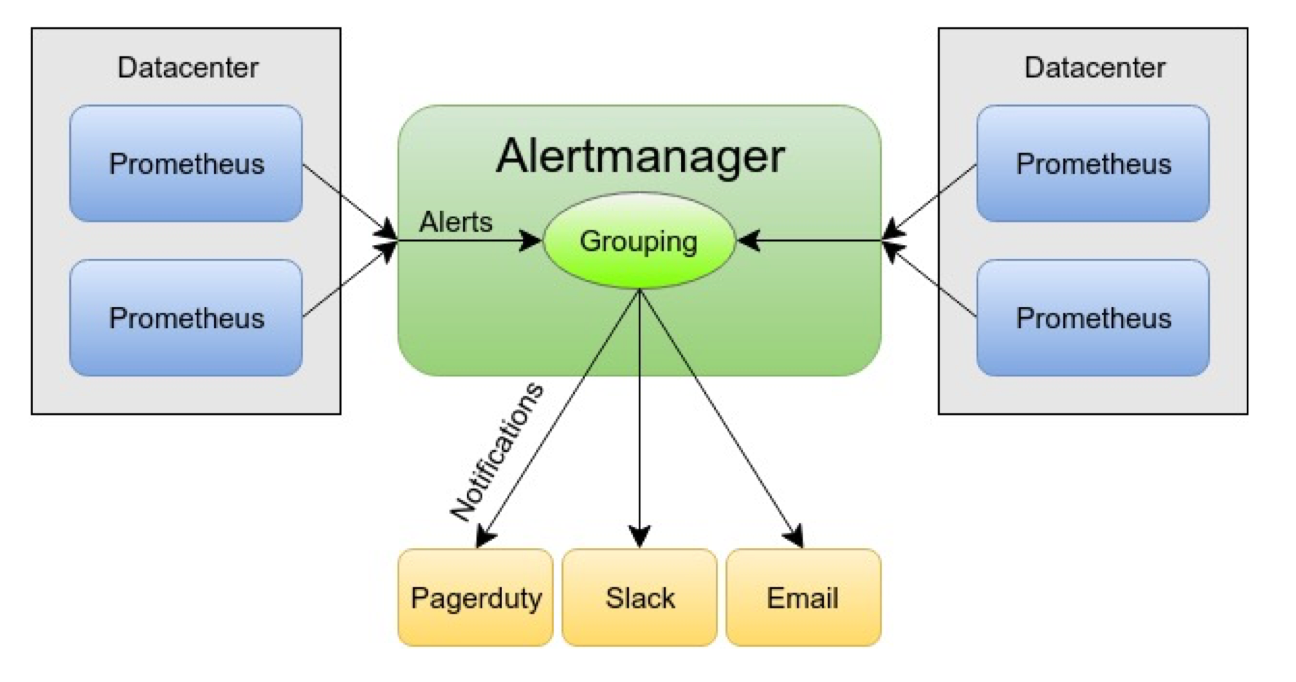
Nếu nhìn từ góc ML engineer, mình có thể xem Prometheus như người “phát hiện vấn đề”, còn Alertmanager như người “xử lý và truyền đạt vấn đề”. Trong thực tế, mình thường đặt các quy tắc cảnh báo cho drift, nhưng mức độ quan trọng lại khác nhau. Data drift nhẹ có thể chỉ cần email nhắc nhở, còn drift nặng làm tỷ lệ NULL tăng mạnh thì cần gửi thông báo khẩn cấp qua Slack hoặc PagerDuty. Cách tách rời hai vai trò giúp mình xây dựng pipeline giám sát ML rõ ràng và có tính mở rộng.
3.1. Grouping
Hãy tưởng tượng hệ thống ML deploy nhiều instance trên các node khác nhau. Khi một sự cố xảy ra như database bị lỗi kết nối, mỗi instance backend có thể gửi hàng chục cảnh báo giống hệt nhau. Nếu không có grouping, số lượng cảnh báo gửi đến Slack hoặc email có thể lên hàng trăm chỉ trong vài giây. Khi đó, đội vận hành sẽ khó phân biệt đâu là sự cố chính và đâu là hậu quả lan truyền.
 Alertmanager xử lý vấn đề này bằng cách gom những cảnh báo giống nhau thành một thông báo duy nhất. Nhờ grouping, mình chỉ nhận đúng thông tin quan trọng thay vì bị “ngập” trong tín hiệu nhiễu. Trong hệ thống mô hình ML, grouping đặc biệt hữu ích khi nhiều endpoint inference cùng gặp lỗi, ví dụ như latency tăng đột biến trong giờ cao điểm. Thay vì nhận 50 cảnh báo từ 50 instance, mình chỉ nhận một thông báo duy nhất nói về “inference latency tăng bất thường”.
Alertmanager xử lý vấn đề này bằng cách gom những cảnh báo giống nhau thành một thông báo duy nhất. Nhờ grouping, mình chỉ nhận đúng thông tin quan trọng thay vì bị “ngập” trong tín hiệu nhiễu. Trong hệ thống mô hình ML, grouping đặc biệt hữu ích khi nhiều endpoint inference cùng gặp lỗi, ví dụ như latency tăng đột biến trong giờ cao điểm. Thay vì nhận 50 cảnh báo từ 50 instance, mình chỉ nhận một thông báo duy nhất nói về “inference latency tăng bất thường”.
Bên cạnh việc giảm nhiễu, grouping còn giúp đội ML tập trung vào nguyên nhân chính của sự cố. Khi chỉ có một thông báo gọn gàng, mình có thể phân tích ngay dữ liệu drift hoặc hệ thống backend thay vì mất thời gian lọc các cảnh báo trùng lặp. Đây là yếu tố quan trọng giúp hệ thống monitoring trong MLOps trở nên tinh gọn và dễ quản lý.
3.2. Inhibition
Inhibition trong Alertmanager là cơ chế ngăn không cho gửi những cảnh báo kém quan trọng trong khi đã có một cảnh báo nghiêm trọng hơn đang hoạt động. Slide trang 46 đưa ra một ví dụ rất trực quan: khi cả cụm cluster không thể kết nối, thì tất cả cảnh báo con như “service down”, “database down”, hoặc “node down” đều không nên được gửi nữa. Lý do rất rõ ràng: root cause chỉ là một, và các cảnh báo còn lại chỉ là hệ quả.
Khi áp dụng vào bối cảnh MLOps, inhibition giúp tránh được tình huống hệ thống gửi quá nhiều cảnh báo chỉ vì drift xuất hiện. Ví dụ: nếu concept drift nặng khiến mô hình trả về NULL liên tục, có thể kéo theo nhiều cảnh báo khác như “user redo inference tăng”, “switch model tăng”, hay “latency bất thường”. Nhưng vì tất cả đều là hậu quả từ một nguồn drift chung, mình chỉ cần nhận cảnh báo gốc về “concept drift nghiêm trọng”. Điều này giúp đội vận hành tập trung vào việc xử lý đúng vấn đề, thay vì bị nhiễu bởi những hậu quả thứ cấp.
Cơ chế inhibition giúp hệ thống cảnh báo ML trở nên thông minh hơn. Thay vì chỉ phát hiện và gửi tín hiệu, hệ thống có khả năng sắp xếp mức độ ưu tiên và giảm thiểu tiếng ồn. Đây là một yêu cầu quan trọng khi mô hình chạy trong môi trường sản xuất với hàng ngàn request mỗi giờ.
3.3. Silences
Silences là tính năng cho phép tạm thời tắt một nhóm cảnh báo, thường dùng khi bảo trì hệ thống hoặc cập nhật mô hình. Ví dụ: nếu có lịch nâng cấp hệ thống vào 2–3 giờ chiều, đội vận hành có thể tạo một “silence window” để ngăn các cảnh báo phát sinh trong giai đoạn này. Điều này giúp tránh tình trạng hệ thống hiểu nhầm bảo trì là sự cố và gửi cảnh báo liên tục.
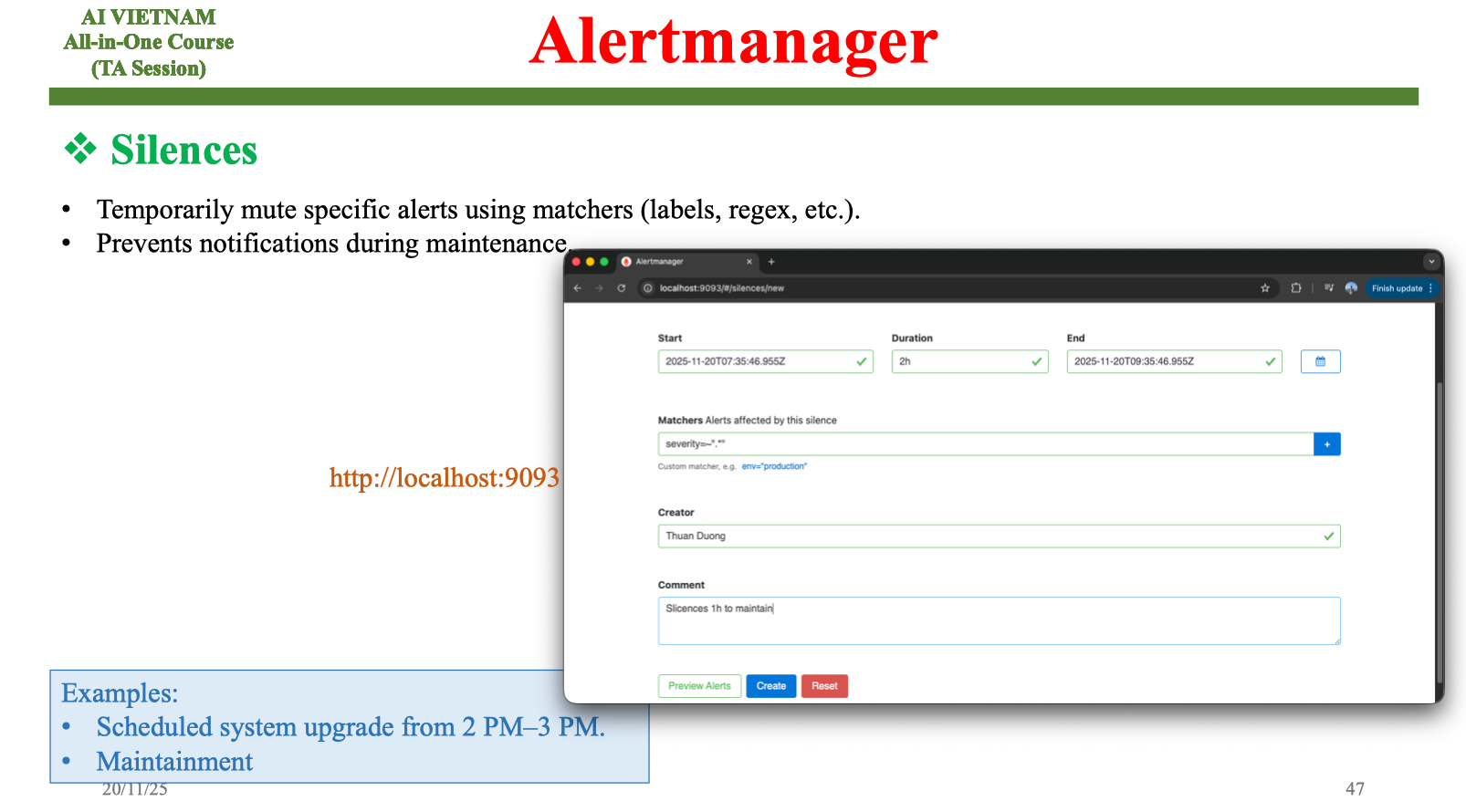 Trong ML, silence rất quan trọng khi mình cập nhật mô hình hoặc thay đổi pipeline dữ liệu. Những thay đổi này thường tạo ra drift tạm thời, ví dụ phân phối ảnh input thay đổi khi tăng cường dữ liệu ngoại cảnh, hoặc latency tăng khi cập nhật phiên bản model mới. Nếu không dùng silence, quá trình deploy có thể bị gián đoạn bởi những cảnh báo không cần thiết. Khi hệ thống quay lại ổn định, silence tự động hết hiệu lực và cảnh báo hoạt động như bình thường.
Trong ML, silence rất quan trọng khi mình cập nhật mô hình hoặc thay đổi pipeline dữ liệu. Những thay đổi này thường tạo ra drift tạm thời, ví dụ phân phối ảnh input thay đổi khi tăng cường dữ liệu ngoại cảnh, hoặc latency tăng khi cập nhật phiên bản model mới. Nếu không dùng silence, quá trình deploy có thể bị gián đoạn bởi những cảnh báo không cần thiết. Khi hệ thống quay lại ổn định, silence tự động hết hiệu lực và cảnh báo hoạt động như bình thường.
Điều thú vị là silence không xóa cảnh báo, mà chỉ ngăn hệ thống gửi thông báo. Nhờ vậy, mình vẫn có thể xem lại lịch sử cảnh báo phục vụ phân tích sau này. Đây là yếu tố quan trọng giúp đội ML hiểu rõ tác động của mỗi lần cập nhật model.
3.4. Alert rules
Cú pháp tạo alert rules trong Prometheus được định nghĩa trong phần này. Mỗi rule là một điều kiện được PromQL đánh giá theo chu kỳ. Khi điều kiện thỏa mãn trong một khoảng thời gian nhất định, Prometheus gửi cảnh báo sang Alertmanager. Trong hệ thống ML, mình thường định nghĩa các rule liên quan đến drift, latency, và lỗi inference.
Một ví dụ quen thuộc là cảnh báo khi tỉ lệ NULL vượt quá ngưỡng. Nếu tỉ lệ này tăng đột ngột, có thể mô hình đang gặp concept drift hoặc input bị thay đổi. Một rule PromQL có thể như sau:
increase(null_output_count[5m]) > 10
Nếu điều kiện duy trì trong 5 phút, Prometheus sẽ tạo một cảnh báo. Khi cảnh báo được xử lý bởi Alertmanager, nó sẽ tuân theo logic grouping, inhibition và routing đã được cấu hình. Đây là cách tạo nên một pipeline cảnh báo ổn định, giúp đội ML phát hiện sớm và phản ứng nhanh với sự cố mô hình.
4. Instrumenting
Khi xây dựng hệ thống MLOps, việc hiểu Prometheus và Grafana ở mức khái niệm mới chỉ là bước đầu. Để hệ thống thật sự hoạt động, mình phải “đưa” được các metrics và logs từ ứng dụng ra ngoài, để Prometheus có thể thu thập và Grafana có thể trực quan hóa. Quá trình này được gọi là instrumenting, tức là gắn các thiết bị quan sát vào ứng dụng. Trong bối cảnh ML, điều này trở nên quan trọng vì mô hình chỉ có ý nghĩa khi được quan sát liên tục và có thể suy luận về sức khỏe của chính nó dựa trên dữ liệu thật.
Instrumenting không chỉ đơn thuần là thêm vài dòng code. Đây là quá trình thiết kế lại cách ứng dụng ML phơi bày metrics, cách backend cung cấp thông tin về drift, và cách log được lưu lại để phân tích mẫu lỗi. Slide trang 50–51 cho thấy toàn bộ quy trình instrumenting gồm việc lựa chọn client library, cài đặt môi trường, tạo endpoint metrics và theo dõi mục tiêu được Prometheus trích xuất. Đây là phần “kỹ thuật thấp tầng” nhưng cực kỳ quan trọng trong triển khai MLOps.
4.1. Prometheus Instrumenting
4.1.1. Giới thiệu
Có hai hướng tiếp cận chính khi instrument API ML viết bằng Python: dùng Prometheus client library hoặc dùng FastAPI Instrumentator. Hai lựa chọn này có mức độ kiểm soát khác nhau. Khi cần theo dõi drift hoặc đặc trưng đầu vào như độ sáng ảnh hoặc độ dài văn bản, mình thường ưu tiên client library vì nó cho phép định nghĩa tùy biến theo logic mô hình. Instrumentator phù hợp với việc tự động thu latency, số request, response code nhưng không bao quát hết đặc thù của mô hình ML.
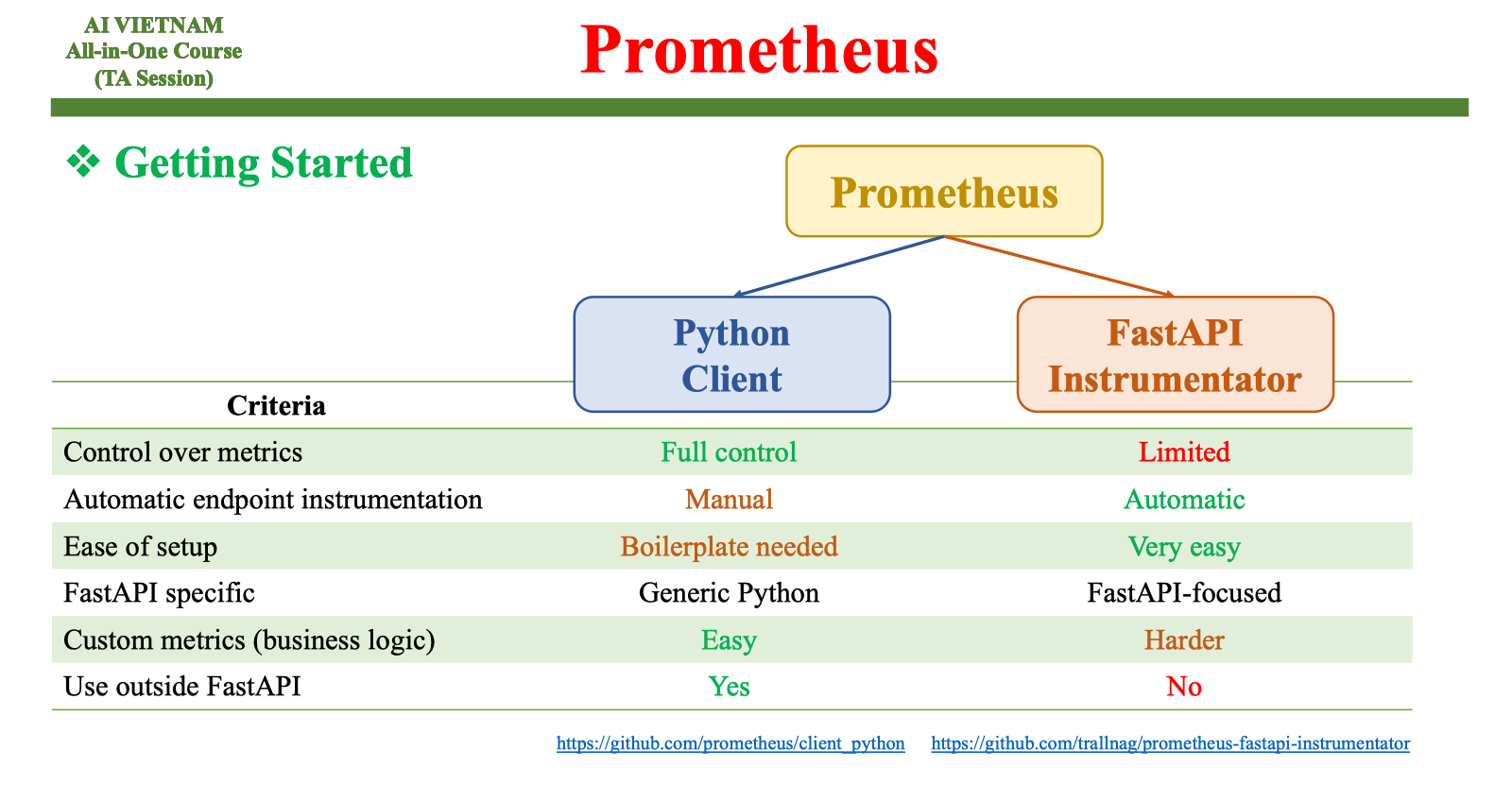
Trong MLOps, tính linh hoạt rất quan trọng. Mô hình có thể thay đổi theo thời gian, và mình cần khai báo thêm metrics mới nếu muốn theo dõi sát sao hành vi của dữ liệu. Việc dùng client library tạo điều kiện cho backend ML được tùy chỉnh sâu hơn. Với mỗi request inference, mình có thể cập nhật hàng loạt metrics liên quan đến drift, chất lượng đầu vào hoặc trạng thái mô hình.
4.1.2. Setup
Có thêm cách tạo endpoint /metrics bằng Python client library. Thông thường, mình bắt đầu bằng việc tạo file riêng để định nghĩa các metric quan trọng, sau đó import vào ứng dụng FastAPI. Endpoint /metrics do make_asgi_app() xử lý, Prometheus sẽ truy cập và lấy dữ liệu định kỳ.
Ví dụ tối giản:
from prometheus_client import Counter, Gauge, Histogram from fastapi import FastAPI from prometheus_client import make_asgi_app app = FastAPI() metrics_app = make_asgi_app() REQUEST_COUNT = Counter("inference_count", "Number of inference requests") LATENCY = Histogram("inference_latency_seconds", "Inference latency") app.mount("/metrics", metrics_app)
Khi người dùng gửi request, mình tăng counter hoặc cập nhật histogram. Đây là cách mà mô hình “nói chuyện” với Prometheus.
4.1.3. Docker
Trong môi trường triển khai thực tế, backend ML và Prometheus thường chạy bằng Docker. Việc container hóa giúp đảm bảo mọi thành phần hoạt động nhất quán và Prometheus có thể truy cập endpoint /metrics của backend thông qua tên dịch vụ. Điều này giảm rủi ro lỗi kết nối và phù hợp với các hệ thống ML phân tán hoặc nhiều phiên bản dịch vụ chạy song song.
 Khi khởi chạy bằng Docker, backend chỉ cần mở cổng cho Prometheus. Mình không phải lo về địa chỉ IP thay đổi, vì Docker networking tự xử lý. Nhờ vậy, việc kết nối các thành phần trong hệ thống ML trở nên dễ dàng và minh bạch hơn.
Khi khởi chạy bằng Docker, backend chỉ cần mở cổng cho Prometheus. Mình không phải lo về địa chỉ IP thay đổi, vì Docker networking tự xử lý. Nhờ vậy, việc kết nối các thành phần trong hệ thống ML trở nên dễ dàng và minh bạch hơn.
4.1.4. Prometheus UI
Prometheus cung cấp giao diện web để truy vấn trực tiếp metrics và quan sát dữ liệu thô. Đây là nơi tiện lợi để kiểm tra xem ứng dụng ML có phơi đúng metrics hay không, giá trị có đúng kỳ vọng không và logic đếm hoặc đo lường đã hoạt động chính xác chưa. Khi viết code instrumenting, đây thường là giao diện được truy cập nhiều nhất để kiểm chứng nhanh.
Khi phát triển mô hình ML, mình thường dùng Prometheus UI để xác nhận raw metrics trước khi xây dashboard Grafana. Điều này giúp giảm đáng kể thời gian debug. Mỗi metric được hiển thị theo dạng text chuẩn, và mình có thể chạy thử các truy vấn PromQL ngay tại giao diện.
4.1.5. Target Metrics
Danh sách target giúp biết Prometheus có đang thu thập dữ liệu từ backend ML hay không. Khi một target ở trạng thái “UP”, việc scrape diễn ra bình thường; khi chuyển sang “DOWN”, có thể endpoint /metrics bị lỗi, container gặp sự cố hoặc backend ngừng phản hồi. Đây là bước giám sát cơ bản nhưng quan trọng để đảm bảo pipeline quan sát luôn liền mạch.
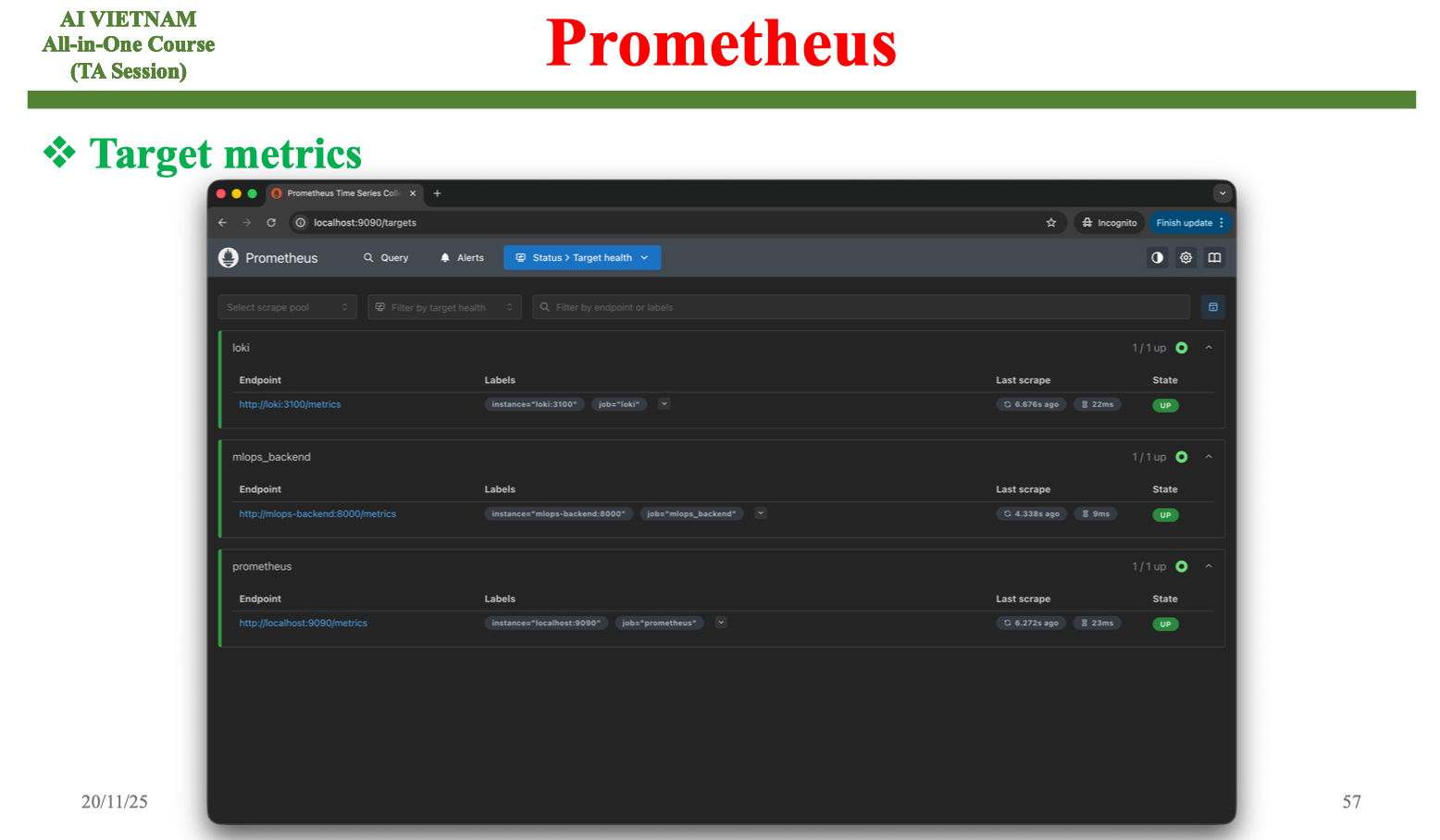
Khi instrumenting mô hình, việc theo dõi trạng thái target giúp phát hiện nhanh các vấn đề liên quan đến triển khai. Điều này đặc biệt quan trọng khi mô hình ML chạy trên nhiều instance hoặc trong môi trường autoscaling.
4.2. Grafana
4.2.1. Giới thiệu
Grafana đóng vai trò là lớp trực quan hóa cho toàn bộ hệ thống metrics. Trong MLOps, dữ liệu theo thời gian như drift, latency hoặc phân phối đầu vào thường khó nhận ra nếu chỉ nhìn số liệu thô. Grafana giúp chuyển những tín hiệu đó thành biểu đồ, xu hướng và các chỉ điểm bất thường, giúp việc phân tích mô hình dễ dàng hơn rất nhiều.
Nhờ khả năng kết nối trực tiếp với Prometheus và hỗ trợ nhiều dạng biểu đồ, Grafana trở thành công cụ không thể thiếu để theo dõi “sức khỏe” của mô hình. Khi có dashboard tốt, việc nhận biết drift trở nên nhanh chóng và chính xác hơn.
4.2.2. Grafana Server và UI
Grafana thường chạy trên cổng 3000 và cho phép mình cấu hình nguồn dữ liệu ngay trên giao diện web. Việc liên kết Grafana với Prometheus rất đơn giản: chỉ cần thêm một data source và cung cấp URL của Prometheus server. Từ đây, cả hệ thống metrics sẽ được mở ra cho việc trực quan hóa.
Giao diện của Grafana cho phép tạo dashboard mới, thêm biểu đồ, chọn loại dữ liệu và viết truy vấn PromQL trực tiếp. Mỗi bảng trên dashboard là một câu truy vấn nhỏ, và mình có thể điều chỉnh phạm vi thời gian để xem diễn biến metrics trên nhiều thang thời gian khác nhau.
4.2.3. Dashboard
Việc tạo dashboard trong Grafana mang lại cách nhìn toàn diện cho cả mô hình và hệ thống. Khi làm MLOps, mình thường xây các nhóm bảng liên quan đến drift dữ liệu, trạng thái backend và chất lượng mô hình. Những bảng này kết hợp với nhau cho phép nhìn thấy sự thay đổi dữ liệu, tốc độ xử lý và mức độ chính xác thông qua cùng một giao diện.
Grafana hỗ trợ ngưỡng màu, cảnh báo, chú thích và nhiều kiểu biểu đồ. Những yếu tố này giúp việc nhận diện xu hướng bất thường trở nên trực quan hơn và giảm nguy cơ bỏ sót drift xảy ra từ từ.
4.3. Grafana Loki
4.3.1. Giới thiệu
Loki là hệ thống lưu trữ log tối ưu cho việc tích hợp với Prometheus và Grafana. Không giống các hệ thống log truyền thống, Loki chỉ index nhãn thay vì toàn bộ nội dung, giúp việc lưu trữ log trở nên gọn nhẹ nhưng vẫn giữ khả năng truy vấn nhanh. Đây là điểm mạnh đặc biệt quan trọng khi xử lý lượng log lớn từ mô hình ML.
Khi kết hợp cùng Grafana, Loki cho phép hiển thị log song song với metrics. Điều này làm quá trình phân tích lỗi thuận tiện hơn, vì có thể đối chiếu điểm bất thường trong biểu đồ với các log phát sinh trong cùng thời điểm.
4.3.2. Ứng dụng trong MLOps
Trong bối cảnh MLOps, Loki giúp ghi lại các sự kiện không thể lượng hóa trực tiếp bằng metrics, chẳng hạn như input quá tối, lỗi xử lý ảnh, ngoại lệ trong inference hoặc hành vi bất thường ở người dùng. Khi drift xảy ra, log thường là nơi cung cấp thông tin gốc rễ để hiểu tại sao mô hình hoạt động sai lệch.
Việc Loki hỗ trợ nhiều nguồn log từ Docker Driver đến Promtail cho phép hệ thống ML thu thập dữ liệu log từ bất kỳ môi trường nào. Khi kết hợp với metrics về drift và latency, mô hình ML trở nên minh bạch hơn và dễ chẩn đoán lỗi.
5. Kết luận
Sau khi đi qua toàn bộ hành trình từ trực giác đến cài đặt thực nghiệm, mình có thể thấy rõ rằng việc theo dõi và ghi nhận hoạt động của mô hình không phải là lựa chọn tùy ý, mà là thành phần cốt lõi của bất kỳ hệ thống MLOps nào trong thực tế. Mô hình ML chỉ thật sự tạo ra giá trị khi hoạt động ổn định trước những thay đổi liên tục của dữ liệu, người dùng và môi trường triển khai. Những thay đổi này thường diễn ra âm thầm, dẫn đến drift hoặc suy giảm hiệu năng mà không có tín hiệu rõ rệt, và chính tại điểm này, Prometheus và Grafana trở thành hai công cụ giúp mình “nhìn thấy” điều mà mô hình không tự nói ra.
Điểm quan trọng nhất mà mình muốn nhấn mạnh là monitoring không chỉ theo dõi tài nguyên hệ thống như CPU hay RAM, mà còn theo dõi chính đặc tính của dữ liệu và hành vi của mô hình. Khi một mô hình gặp vấn đề, câu trả lời không bao giờ chỉ nằm ở một chiều quan sát. Ví dụ, data drift có thể xuất hiện từ sự thay đổi ánh sáng trong ảnh, nhưng đồng thời latency tăng bất thường có thể đến từ backend, và tỉ lệ NULL tăng lại phản ánh concept drift. Chỉ khi đặt những chỉ số này cạnh nhau trong dashboard, mình mới thật sự hiểu được toàn bộ bức tranh hoạt động của mô hình.
Với Prometheus, mình có khả năng định nghĩa bất kỳ loại đo lường nào liên quan đến mô hình, từ độ sáng ảnh input đến số lần người dùng phải infer lại. Hệ thống lưu trữ dạng time series giúp mình quan sát xu hướng lâu dài, phát hiện bất thường và tạo nền tảng cho cảnh báo tự động. Trong khi đó, Grafana lại mang đến cách nhìn trực quan, giúp những tín hiệu khó nhận ra trong dữ liệu thô trở nên rõ ràng thông qua biểu đồ, phân phối và dashboard chuyên biệt cho ML.
Alertmanager đóng vai trò như một phần mở rộng tự nhiên của Prometheus, giúp ngăn các sự cố nhỏ trở thành thất bại lớn. Cơ chế grouping, inhibition và silences cho phép hệ thống cảnh báo thông minh hơn, tránh tạo ra nhiễu và chỉ tập trung vào những tín hiệu thật sự quan trọng. Đối với mô hình ML vận hành trong môi trường có lưu lượng lớn, những tính năng này giúp đội vận hành phản ứng nhanh hơn và duy trì tính ổn định của dịch vụ.
Cuối cùng, Loki bổ sung tầng quan sát quan trọng về log, giúp mình kết nối dữ liệu định lượng (metrics) với dữ liệu định tính (logs). Khi xảy ra drift hoặc lỗi, việc đối chiếu hai nguồn dữ liệu này cho phép mình hiểu vấn đề ở mức chi tiết hơn và tìm ra nguyên nhân gốc rễ một cách chính xác. Chính sự phối hợp giữa Prometheus, Grafana và Loki tạo ra một hệ sinh thái hoàn chỉnh, phù hợp với mọi hệ thống ML từ nhỏ đến lớn, giúp mô hình không chỉ chạy đúng mà còn chạy bền vững theo thời gian.