1. Overview ConvNeXt
1.1. CNN Overview
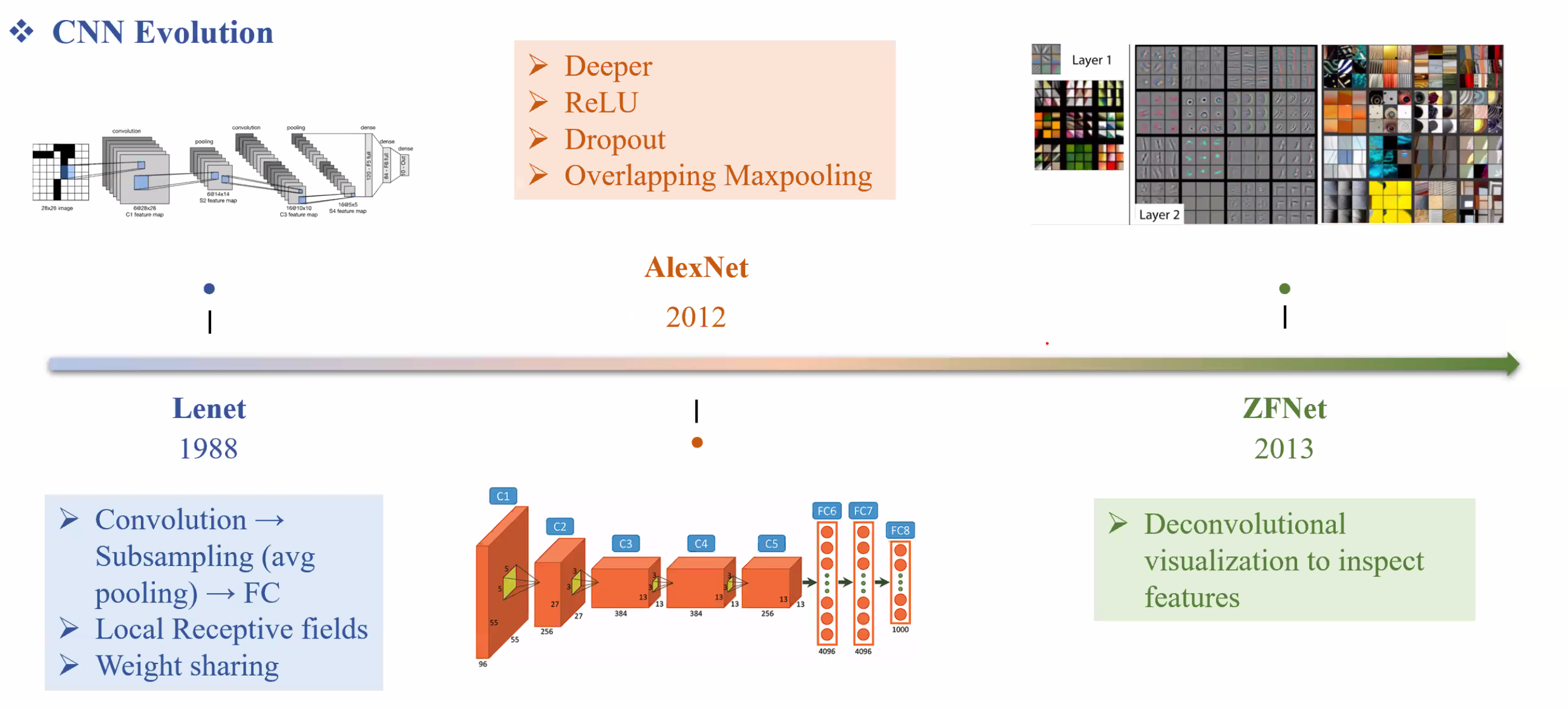
Lenet là mô hình CNN đầu tiên: Chuẩn của Convolution.
- Local Receptive fields: Xem như là Kenel nhỏ quét qua từng phần bức hình.
- Weight sharing: giúp cho kết nối các vùng ảnh với nhau. AlexNet là milestone đánh dấu sự phát triển bức phá hơn Lenet.
- Dropout giúp làm nhiễu feature, tránh overfitting
- Overlapping Maxpooling ZFNet tuy không mới nhưng là paper Explain được từng layer CNN.
- Những layer đầu chứa thông tin chi tiết hơn (local)
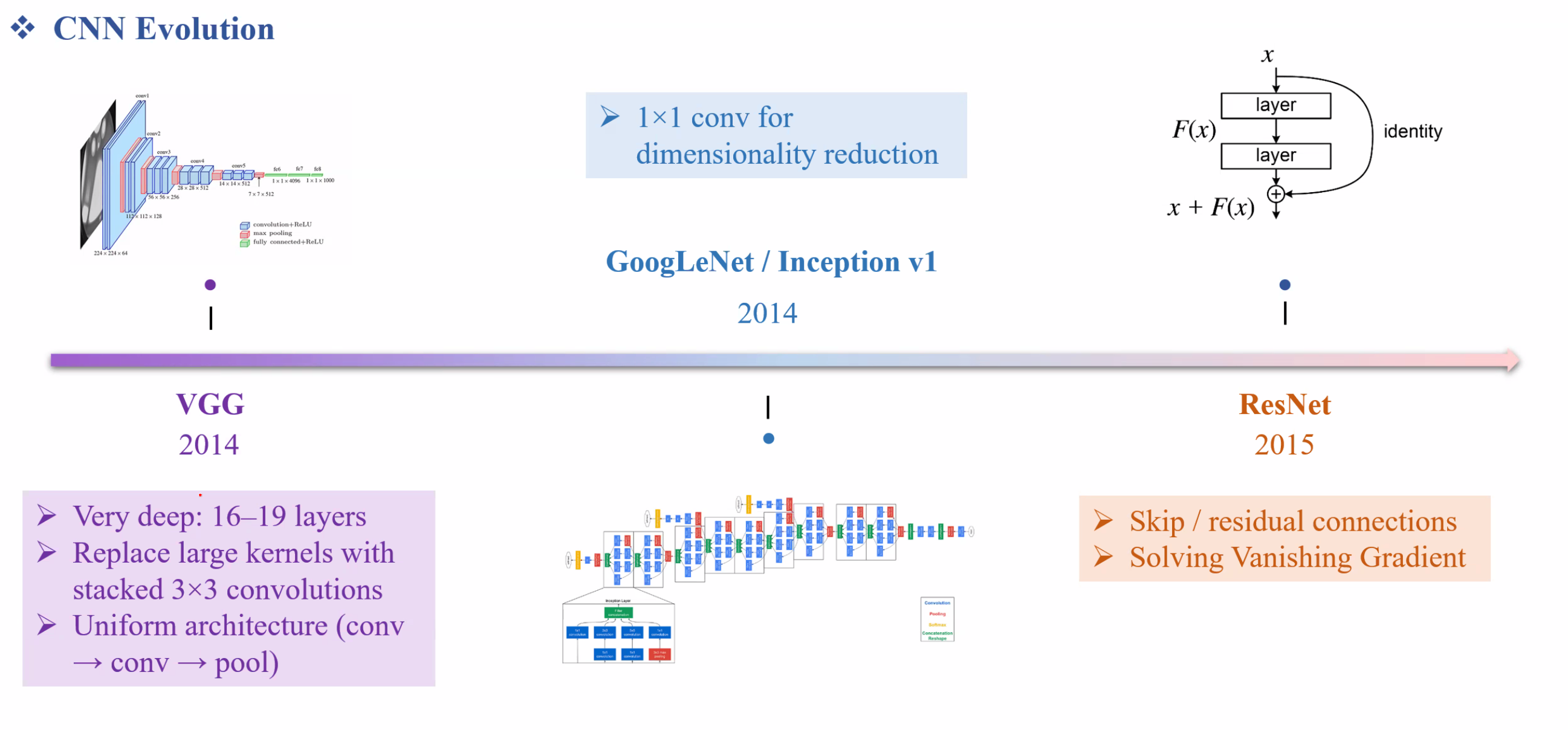
- Những layer sau chứa thông tin tổng thể của bức hình một cách trừu tượng (global) VGG là mô hình sâu hơn. Điểm đặt biệt là dùng các kernel 3 x 3 và cho ra hiệu quả tốt hơn nhiều.
GoogleLeNet/Inception v1
- 1 x 1 conv giúp tổng hợp thông tin theo chiều chanel từ đó giảm được số chiều.
ResNet nhờ skip connection nên giảm được gradient vanish.
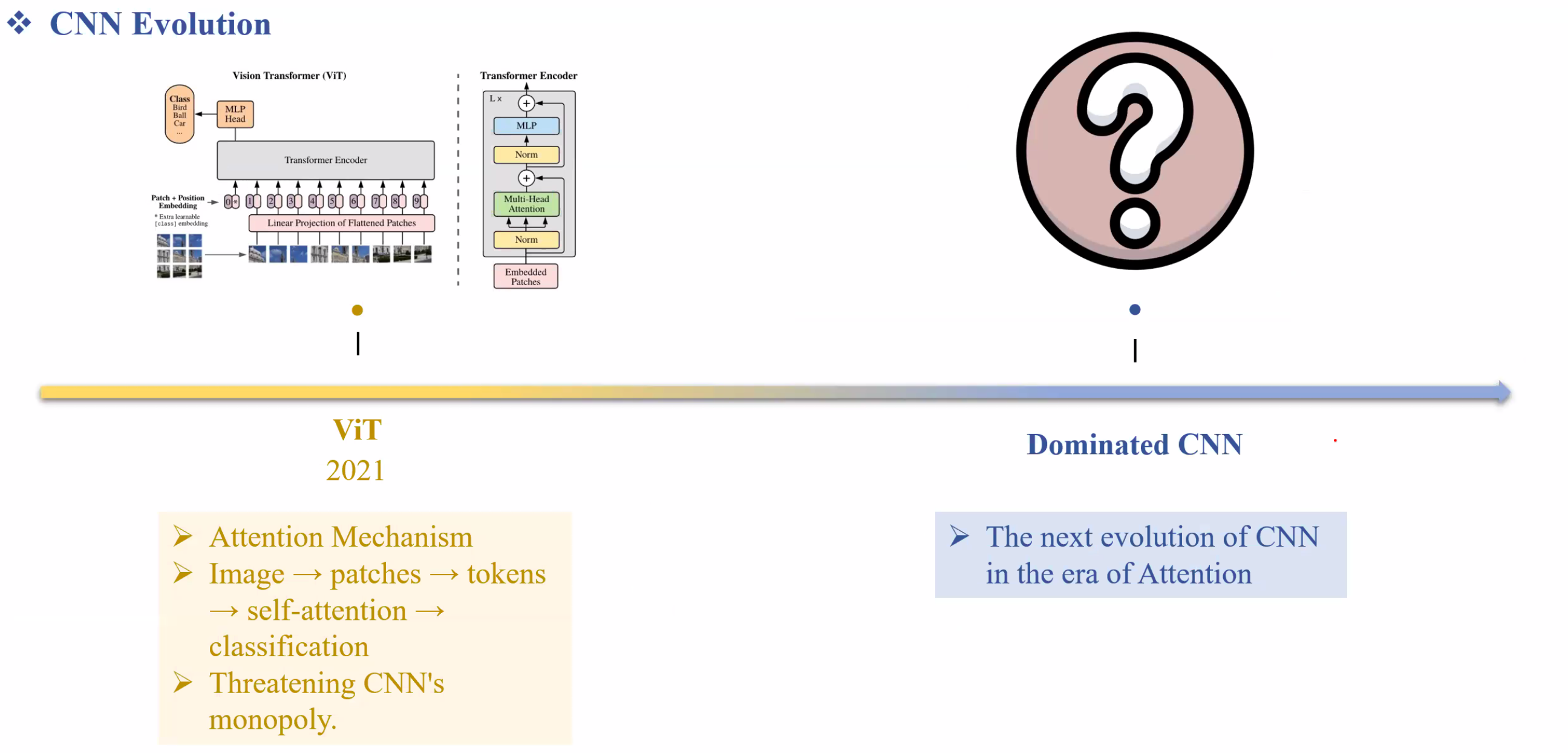
ViT nhờ sử dụng attention của transformer giúp tăng hiệu quả rất nhiều từ đó đánh bại được ResNet. Từ đó transformer đã đánh bại được CNN
1.2. Review Transformer-based: ViT
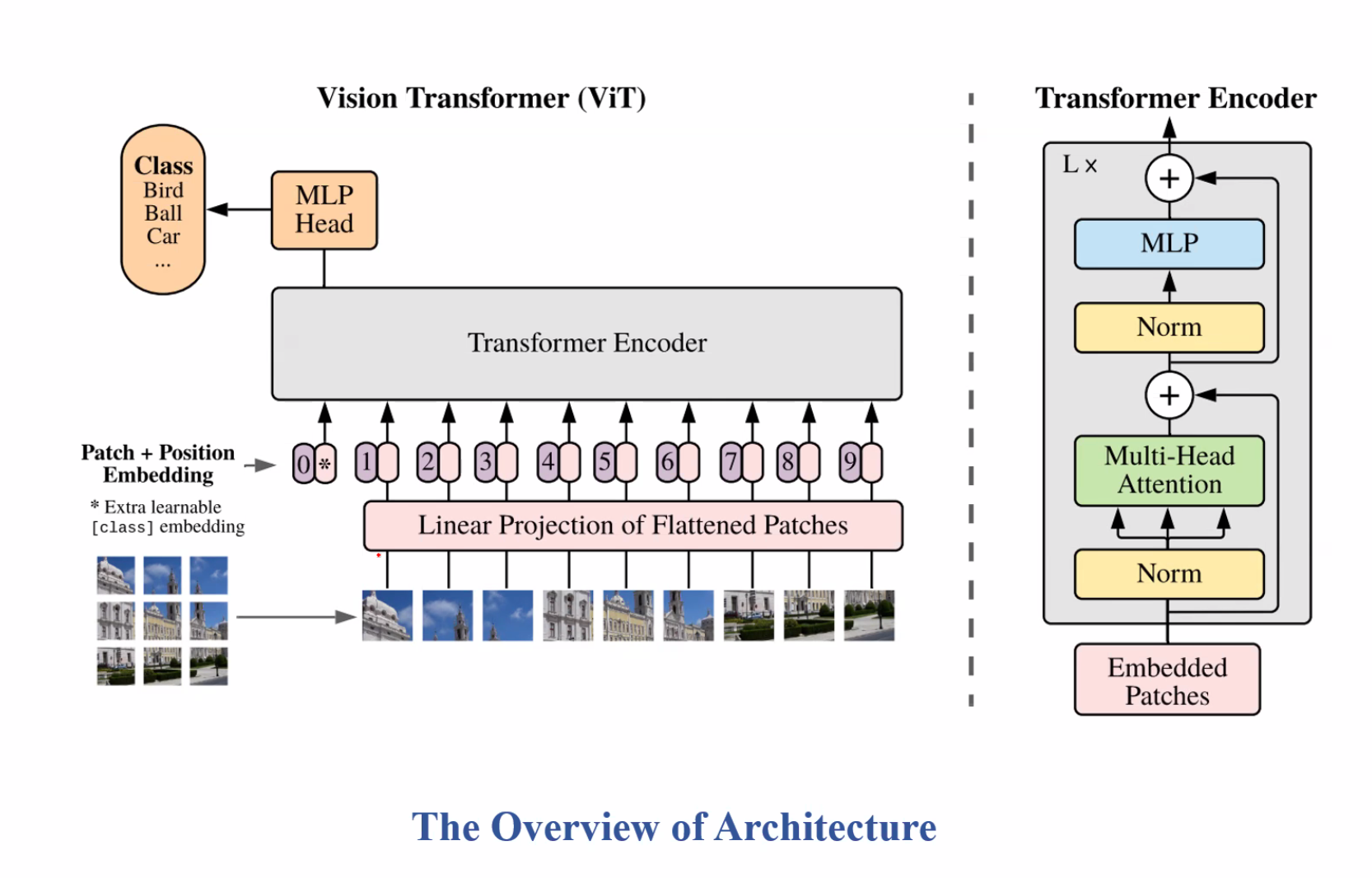
Linear Projection:
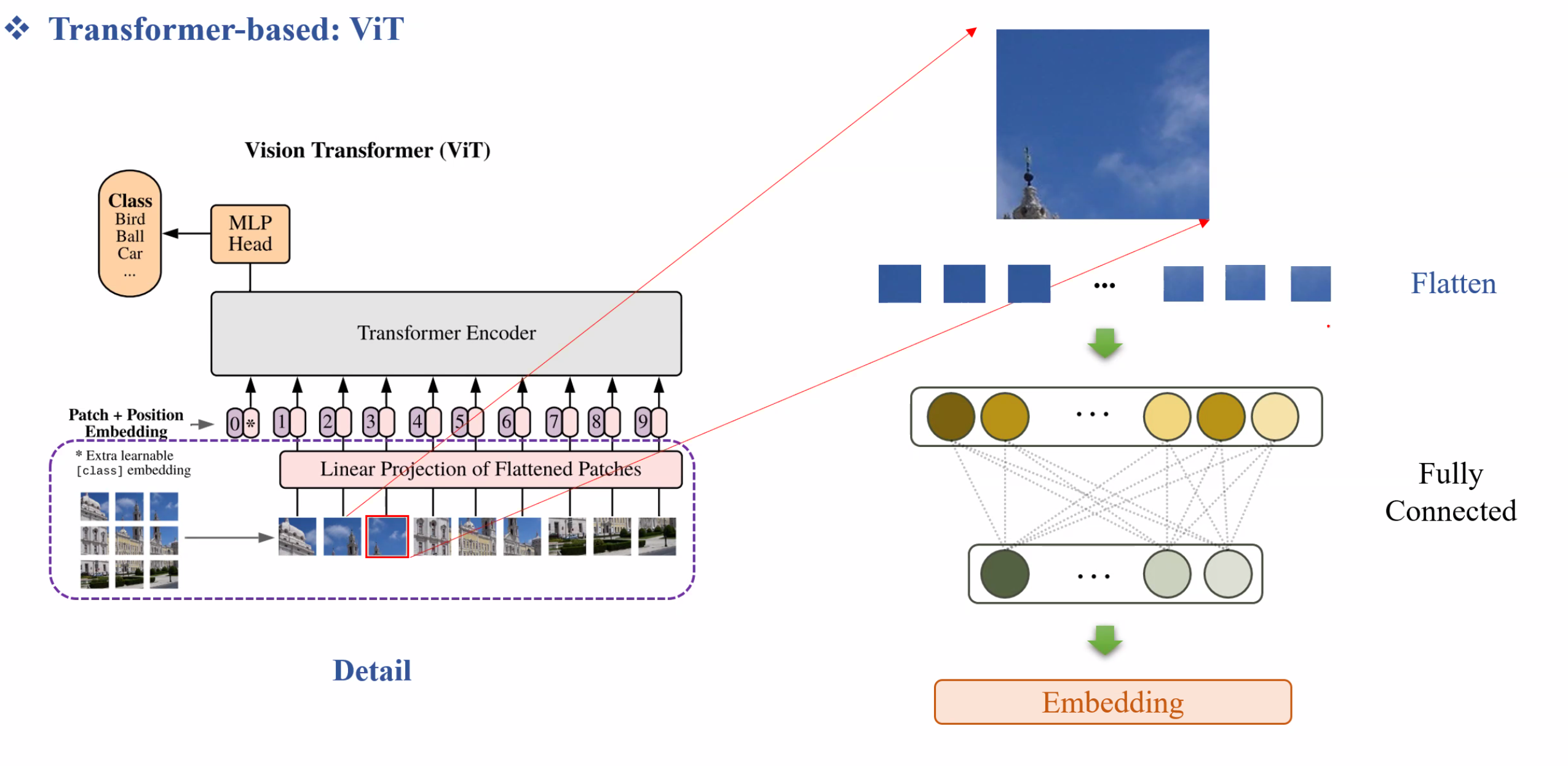 Ta cắt ảnh ra và flatten xong đánh index, sau đó tiếp tục Flatten Pixel → Đưa vào Fully Connected và sau đó Embedding. Từ đây xem một patch ảnh như một token trong NLP.
Nhờ việc chia bức hình ra đủ nhỏ nên ViT học được global information rất tốt.
Ta cắt ảnh ra và flatten xong đánh index, sau đó tiếp tục Flatten Pixel → Đưa vào Fully Connected và sau đó Embedding. Từ đây xem một patch ảnh như một token trong NLP.
Nhờ việc chia bức hình ra đủ nhỏ nên ViT học được global information rất tốt.
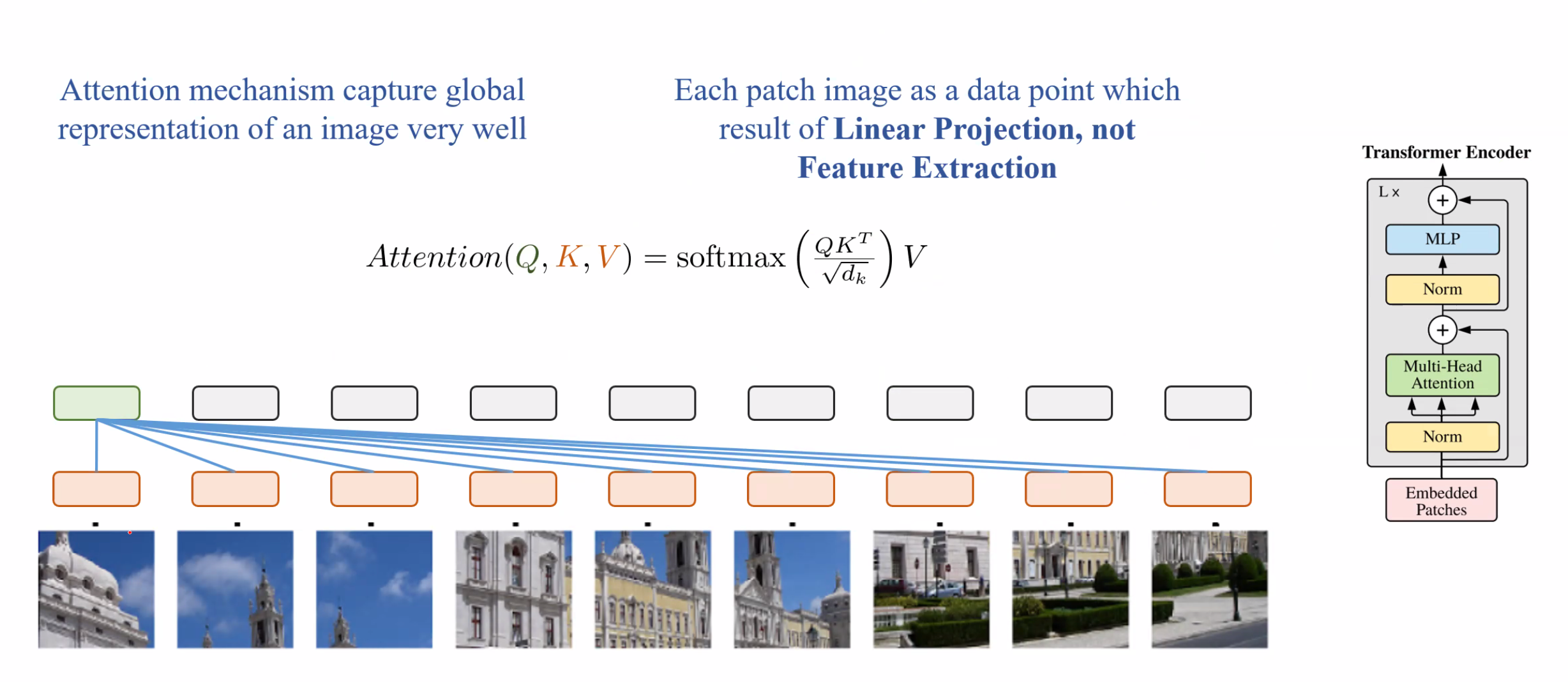 Những ô màu cam đại diện cho vector embedding của từng patch ảnh, sau đó thực hiện dot production để đánh giá được % tương đồng
Vì không phải thuật toán CNN nên ViT không phân tích được mối quan hệ giữa các pixel kề nhau dẫn đến việc không học tốt các chi tiết local.
Những ô màu cam đại diện cho vector embedding của từng patch ảnh, sau đó thực hiện dot production để đánh giá được % tương đồng
Vì không phải thuật toán CNN nên ViT không phân tích được mối quan hệ giữa các pixel kề nhau dẫn đến việc không học tốt các chi tiết local.
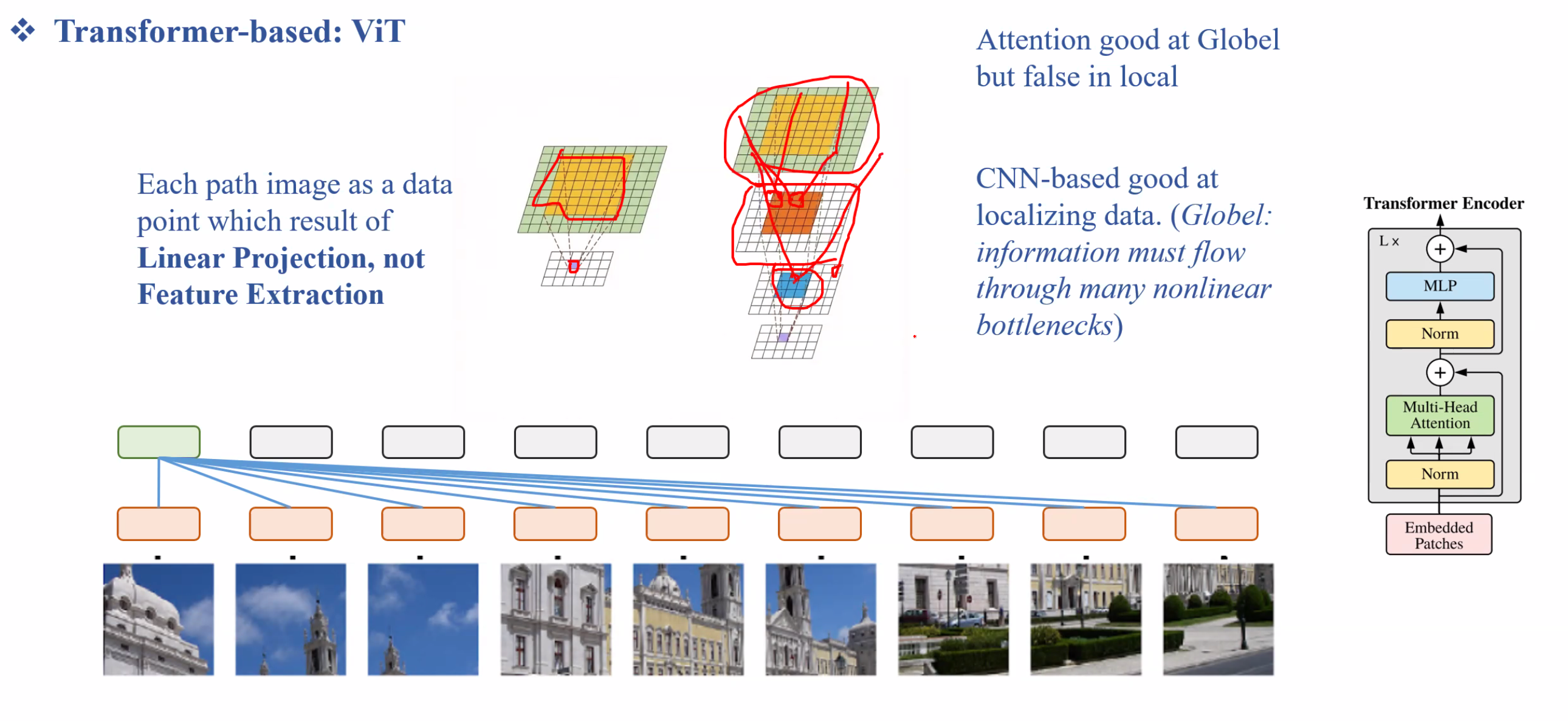 Nhược điểm nữa là ViT cần một dataset lớn hơn nhiều so với CNN để học tốt. Tuy nhiên hiện tại đã có rất nhiều PreTrain ViT để chúng ta sử dụng.
Từ những vấn đề này, chúng ta có thể nghĩ đến việc phát triển một model cân bằng được việc học thông tin Global dựa vào Transformer và học thông tin Local dựa vào CNN.
Nhược điểm nữa là ViT cần một dataset lớn hơn nhiều so với CNN để học tốt. Tuy nhiên hiện tại đã có rất nhiều PreTrain ViT để chúng ta sử dụng.
Từ những vấn đề này, chúng ta có thể nghĩ đến việc phát triển một model cân bằng được việc học thông tin Global dựa vào Transformer và học thông tin Local dựa vào CNN.
1.3. Overview ConvNeXt
Đây là model trung hòa được cả hai dạng CNN và Transformer.
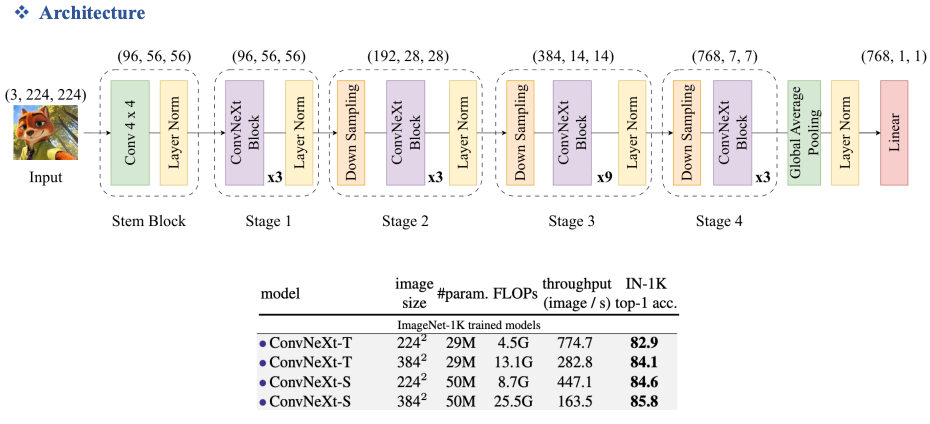
Nhược điểm: Khi tăng image size thì FLOPs () sẽ tăng rất cao và rất nặng.
2. ConvNeXt V1
2.1. Stem Block
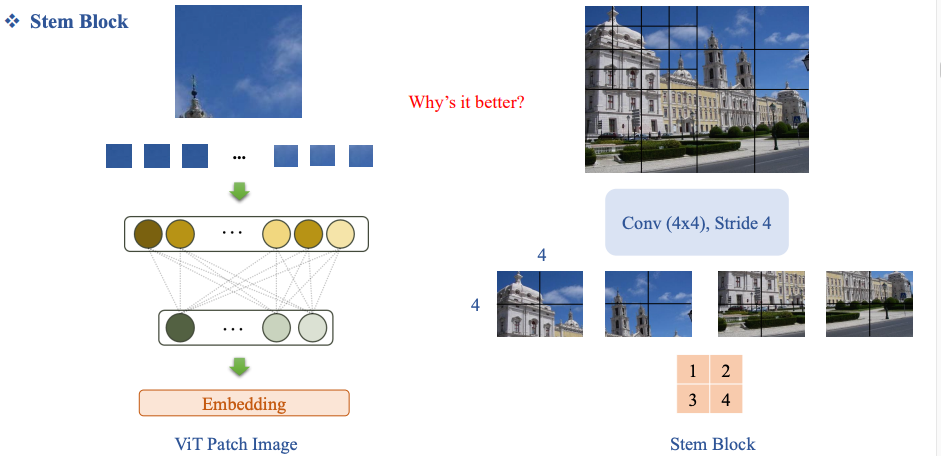 Stem Block bằng Convolution
Quy trình
Stem Block bằng Convolution
Quy trình
- Dùng Conv (4×4), stride = 4:
- Mỗi kernel 4×4 tương ứng với 1 patch.
- Stride 4 đảm bảo không overlap (tương đương patching).
- Output feature map được reshape thành sequence token. Điểm quan trọng
- Đây không chỉ là cắt patch, mà là:
- Vừa chia patch
- Vừa trích xuất đặc trưng cục bộ ngay từ đầu
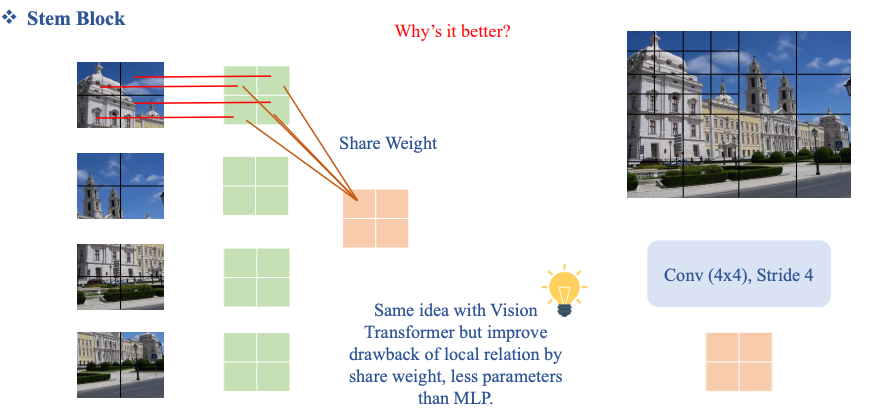

Không dùng Patch Norm mà dùng LayerNorm:
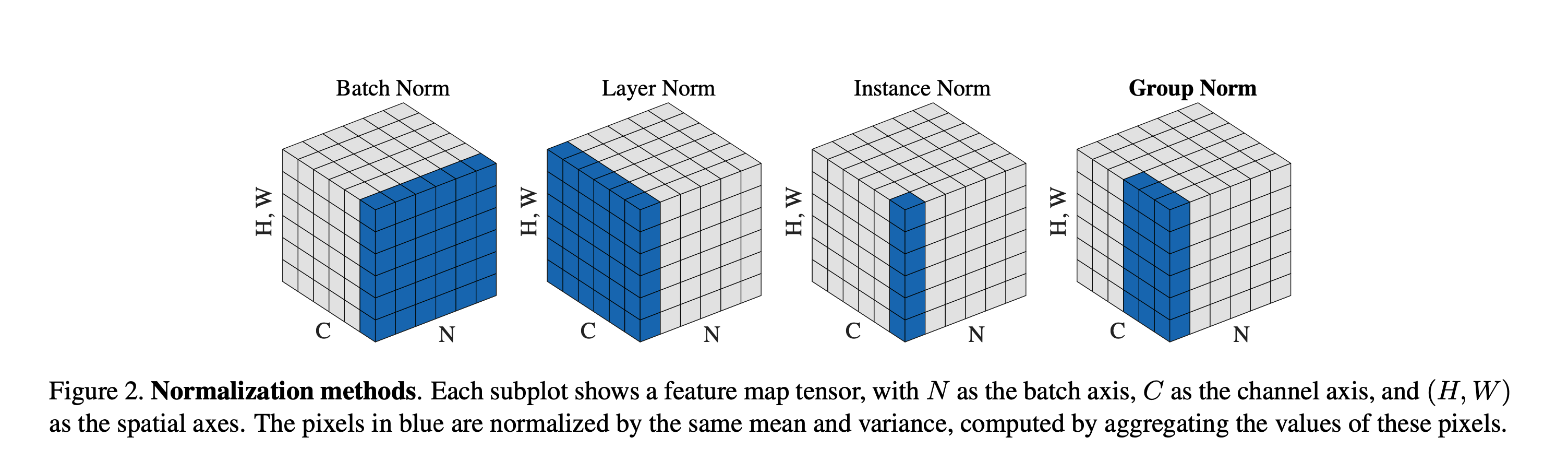 Review PatchNorm:
Review PatchNorm:
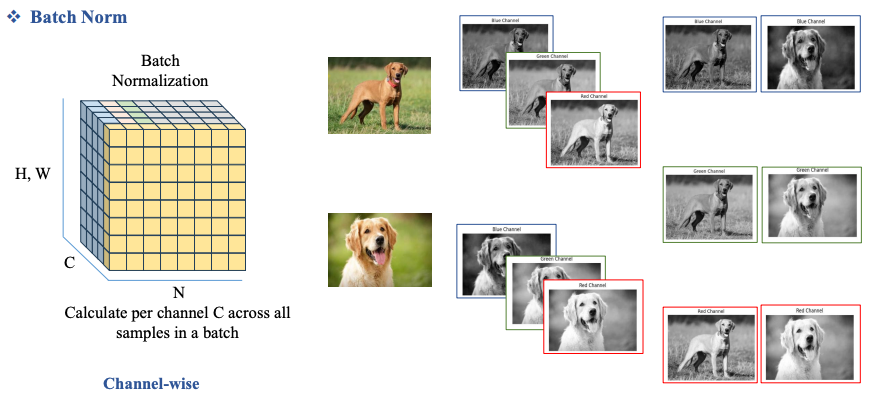 Hình khối này biểu diễn 4 chiều trên một khối 3 D nên cần diễn giải ra như sau. Ta xem chiều H, W đại diện cho bức ảnh.
Hình khối này biểu diễn 4 chiều trên một khối 3 D nên cần diễn giải ra như sau. Ta xem chiều H, W đại diện cho bức ảnh.
- Chiều N là patch size (mỗi lần đưa vào train một patch để optimize), mỗi lớp chiều N là một patch.
- Chiều C là channel, như ở đây ta thấy có 5 channel.
Vậy BatchNorm là ta sẽ Normalize trên từng Channel của ảnh, theo ví dụ trên ảnh là với từng Channel Blue, Green, Red thực hiện Normalize thu được kết quả nằm ở bên phải.
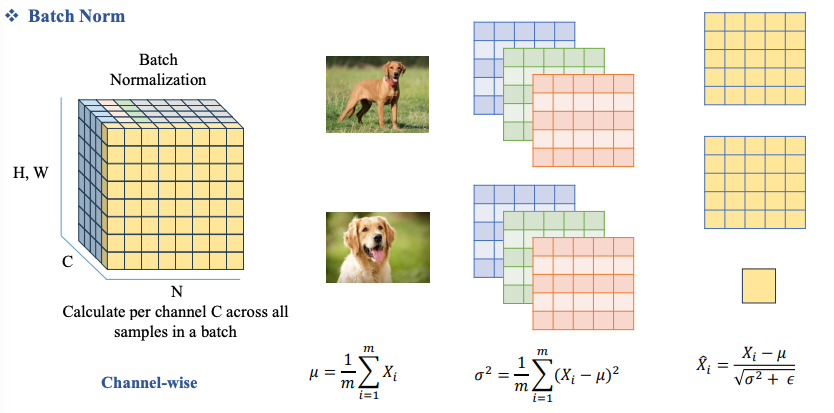 Ở đây epsilon được khai báo gần với zero để tránh lỗi chia cho 0.
Ở đây epsilon được khai báo gần với zero để tránh lỗi chia cho 0.
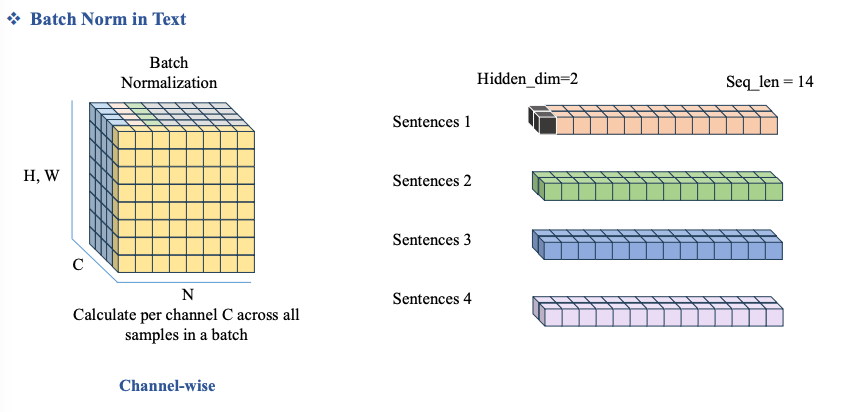 Đối với bài toán NLP, câu:
Đối với bài toán NLP, câu:
“I am student”
Giả sử:
-
Tokenization đơn giản theo từ
-
Embedding dimension = 2 (để dễ tính)
-
Batch size = 2 (BatchNorm bắt buộc phải có batch)
Câu 1: ["I", "am", "student"]
Câu 2: ["I", "am", "teacher"]
Embedding table
| Token | Embedding |
|---|---|
| I | [1.0, 2.0] |
| am | [2.0, 1.0] |
| student | [3.0, 4.0] |
| teacher | [4.0, 3.0] |
| Sau đó tạo thành câu |
Sentence 1:
I → [1.0, 2.0]
am → [2.0, 1.0]
student → [3.0, 4.0]
Sentence 2:
I → [1.0, 2.0]
am → [2.0, 1.0]
teacher → [4.0, 3.0]
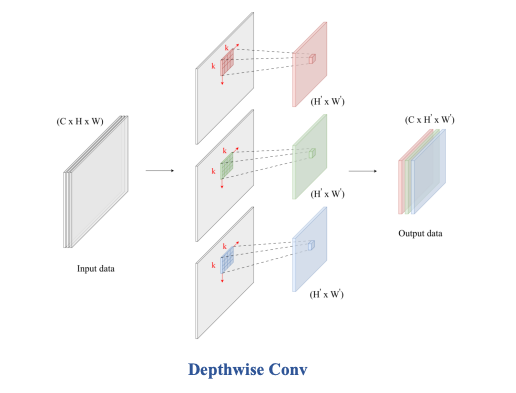
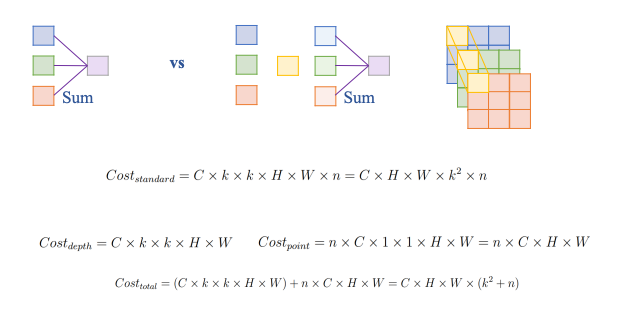
ConvNeXt Block – Depthwise Conv 7x7
Review Feature map
đầu ra (output) của một tầng trích xuất đặc trưng (thường là Convolution layer), dùng để biểu diễn đặc trưng đã được học từ dữ liệu đầu vào.
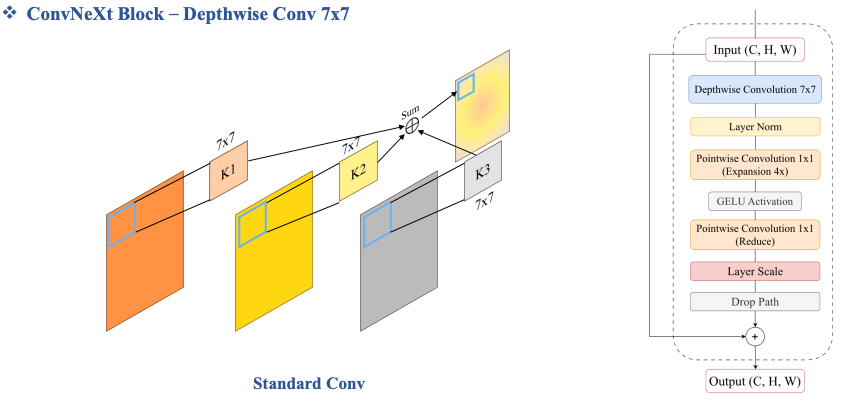
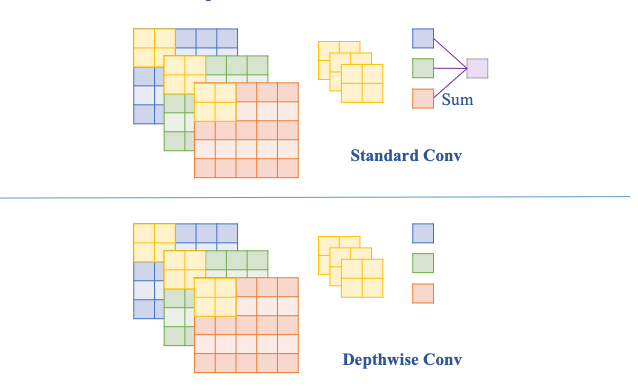
Depthwise Conv chỉ đơn giản là
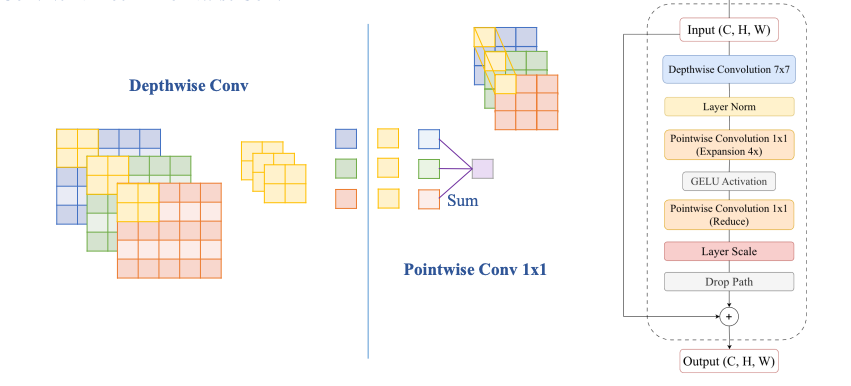
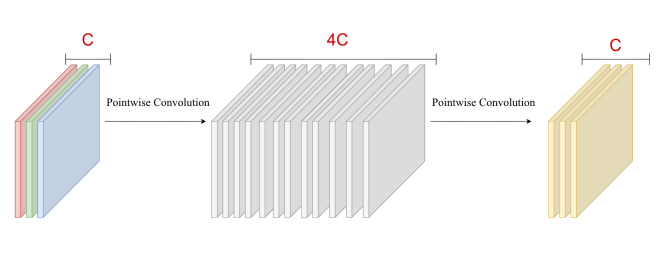
ConvNeXt Block – Pointwise Conv 1x1
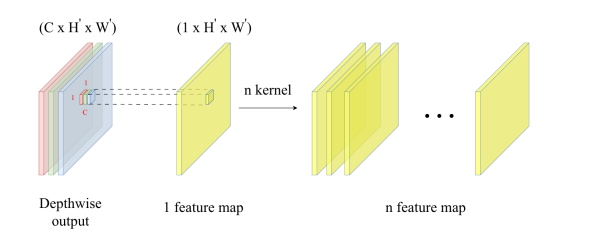 Từ 3 channel màu ta train H x W (Ví dụ 8 x 8=64) kernel để tạo ra được 64 feature map
Từ 3 channel màu ta train H x W (Ví dụ 8 x 8=64) kernel để tạo ra được 64 feature map
Model này không chỉ Convolution ở chiều H, W mà còn là Convolution ở chiều C nên rõ ràng model sẽ học được global rất hiệu quả.
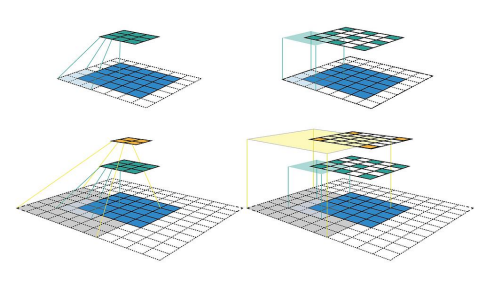
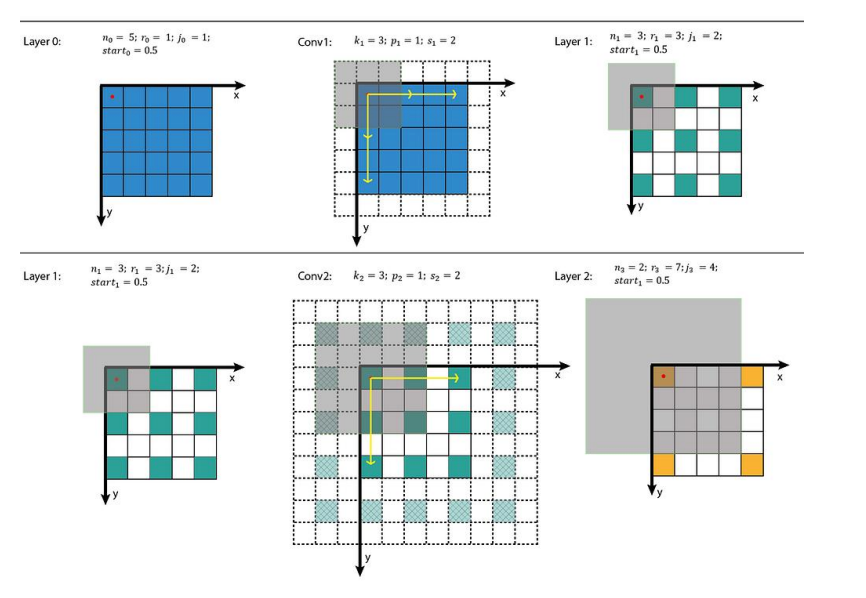 Tại sao lại là 7 x 7 conv?
Theo hình trên ta thấy các feature càng ngày càng bị thưa ra khiến local information bị thưa ra dẫn đến tổng hợp global information không tốt.
Tại sao lại là 7 x 7 conv?
Theo hình trên ta thấy các feature càng ngày càng bị thưa ra khiến local information bị thưa ra dẫn đến tổng hợp global information không tốt.
Vậy khi dùng 7 x 7 conv ta sẽ thu được nhiều thông tin hơn. Pointwise và Depthwise giúp cải thiện feature bị thưa.
Inverted Bottleneck
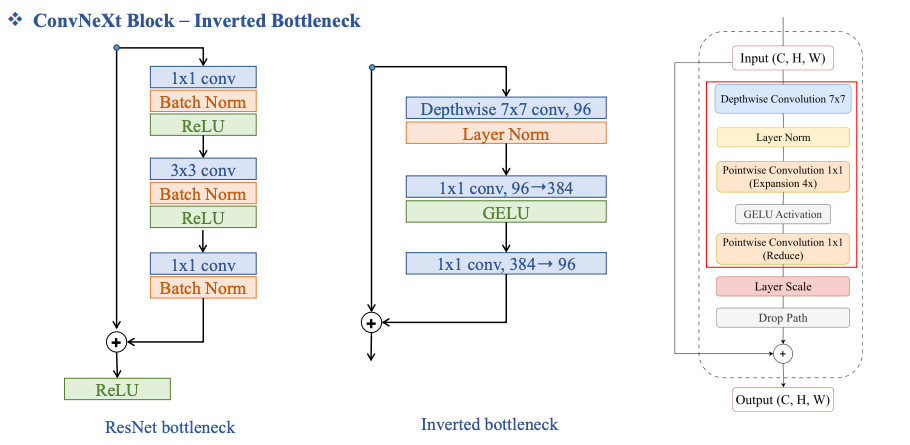
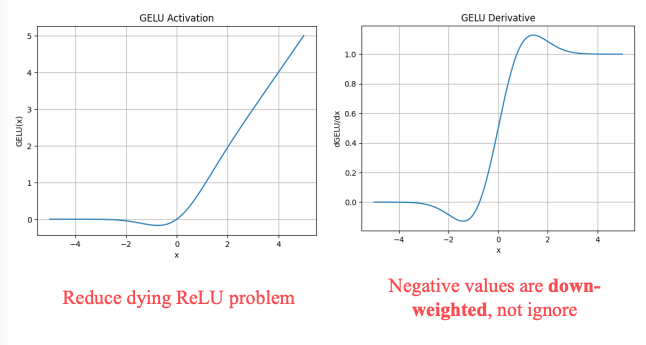
GELU
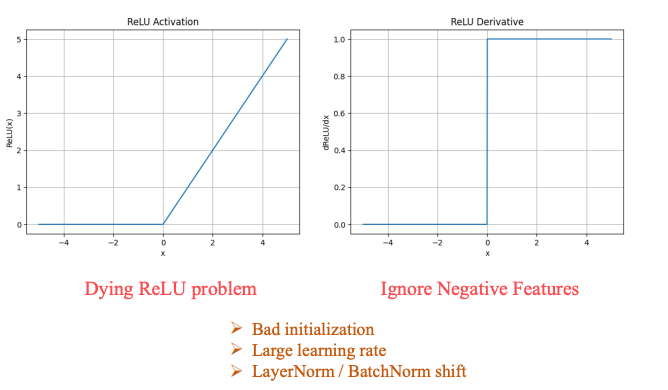
Review lại ReLU Ta thấy rằng đạo hàm của ReLU không liên tục ở x=0, từ đây dẫn đến những lỗi thường hay gặp trong việc Train model như:
- Lỗi
- Lỗi
Hàm GELU giúp giải quyết một phần vấn đề này.
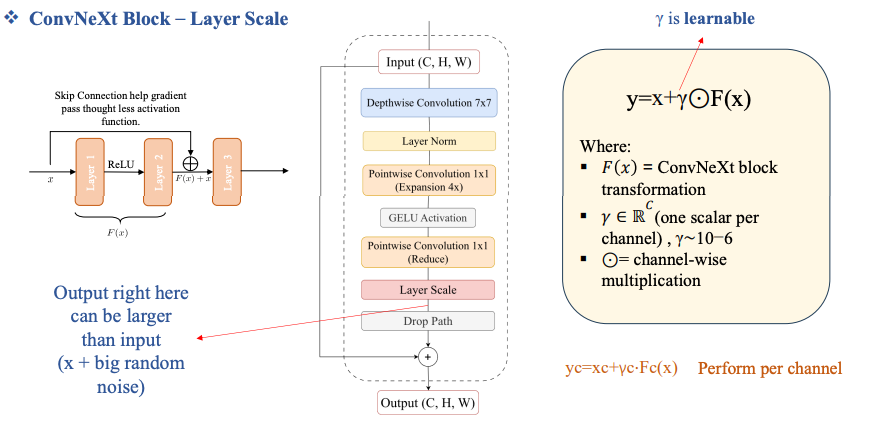
Layer Scale
Skip connection sau khi đi qua nhiều layer, chúng ta dùng skip connection để cố gắng giữ lại được những thông tin cũ bị mất đi.
Đọc thêm ConvMAE: Masked Convolution Meets Masked Autoencoders
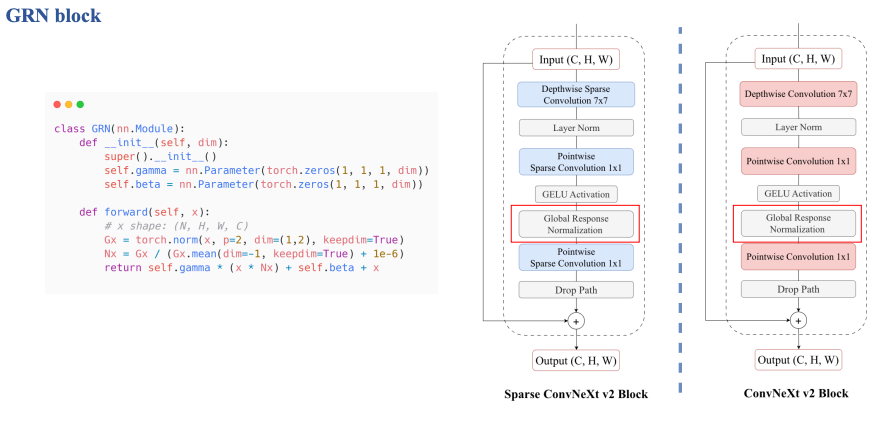
3. ConvNeXt V2
Comparison
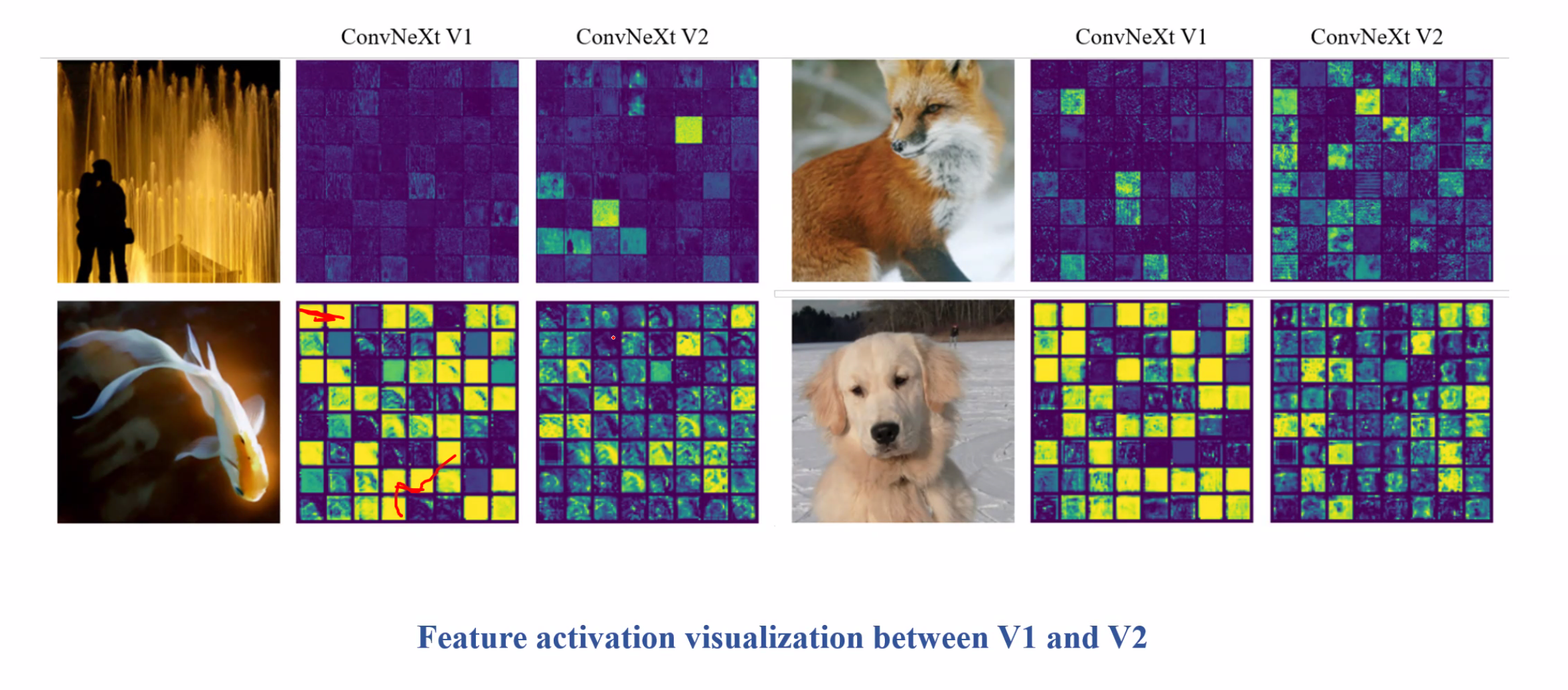
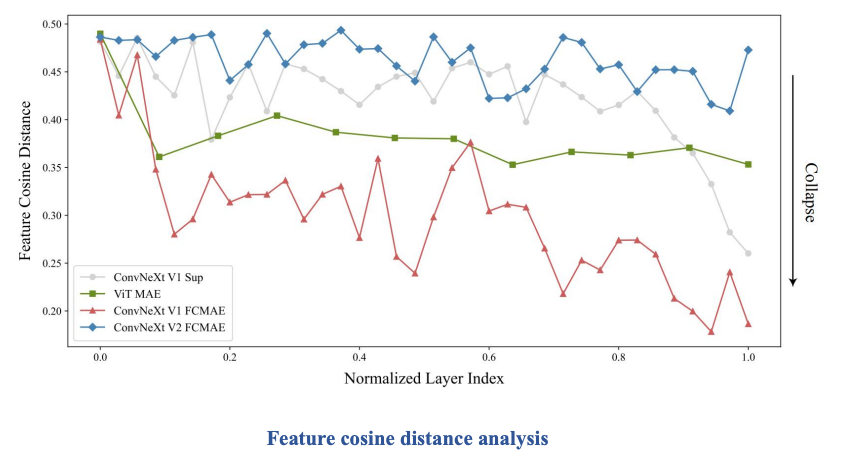
GRN block