PHẦN 1 — N-GRAM LANGUAGE MODEL
1. Giới thiệu
Một trong những trải nghiệm quen thuộc nhất khi sử dụng điện thoại là hệ thống tự gợi ý từ tiếp theo ngay khi chúng ta đang gõ dở câu. Mình muốn bắt đầu chương này từ ví dụ đời thực như vậy vì nó giúp chúng ta cảm được trực giác về Language Model trước khi đi vào công thức toán học. Khi hệ thống dự đoán được từ tiếp theo, thật ra nó đang đánh giá khả năng xuất hiện của từ đó trong bối cảnh đã cho. Hành vi này không chỉ xuất hiện trong bàn phím mà còn nằm ở lõi của dịch máy, sinh văn bản, tổng hợp tiếng nói và rất nhiều ứng dụng NLP khác. Vì vậy câu hỏi mà chúng ta cần trả lời là: làm sao để mô hình hiểu và định lượng được mức độ “tự nhiên” của một câu?
Mình tiếp cận câu hỏi này bằng cách nhìn ngôn ngữ như một chuỗi các sự kiện có quan hệ phụ thuộc. Khi nghe “Tôi đi…”, hầu như ai cũng đoán được những từ tiếp theo hợp lý hơn những từ khác, và điều này có nghĩa là xác suất ngôn ngữ không hề ngẫu nhiên. Để mô hình hóa được sự phụ thuộc này, chúng ta cần một cách biểu diễn xác suất của cả câu theo cách có thể tính toán được. Đây cũng là lý do vì sao mô hình n-gram được ra đời để cân bằng giữa độ chính xác và khả năng ước lượng từ dữ liệu có hạn.
2. Trực giác về mô hình ngôn ngữ
Ngôn ngữ không xuất hiện rời rạc mà luôn có mối quan hệ giữa những từ đứng kề nhau. Giả sử bạn có câu “I want to drink…”, não bộ sẽ tự động đưa ra những khả năng như “water”, “coffee”, “milk” thay vì những từ như “engine” hay “mountain”. Điều này xảy ra vì ngôn ngữ có tính thống kê và chúng ta đã học được các mẫu phụ thuộc qua trải nghiệm. Nếu một mô hình máy tính muốn dự đoán được như con người, nó cũng phải học những mẫu phụ thuộc này.
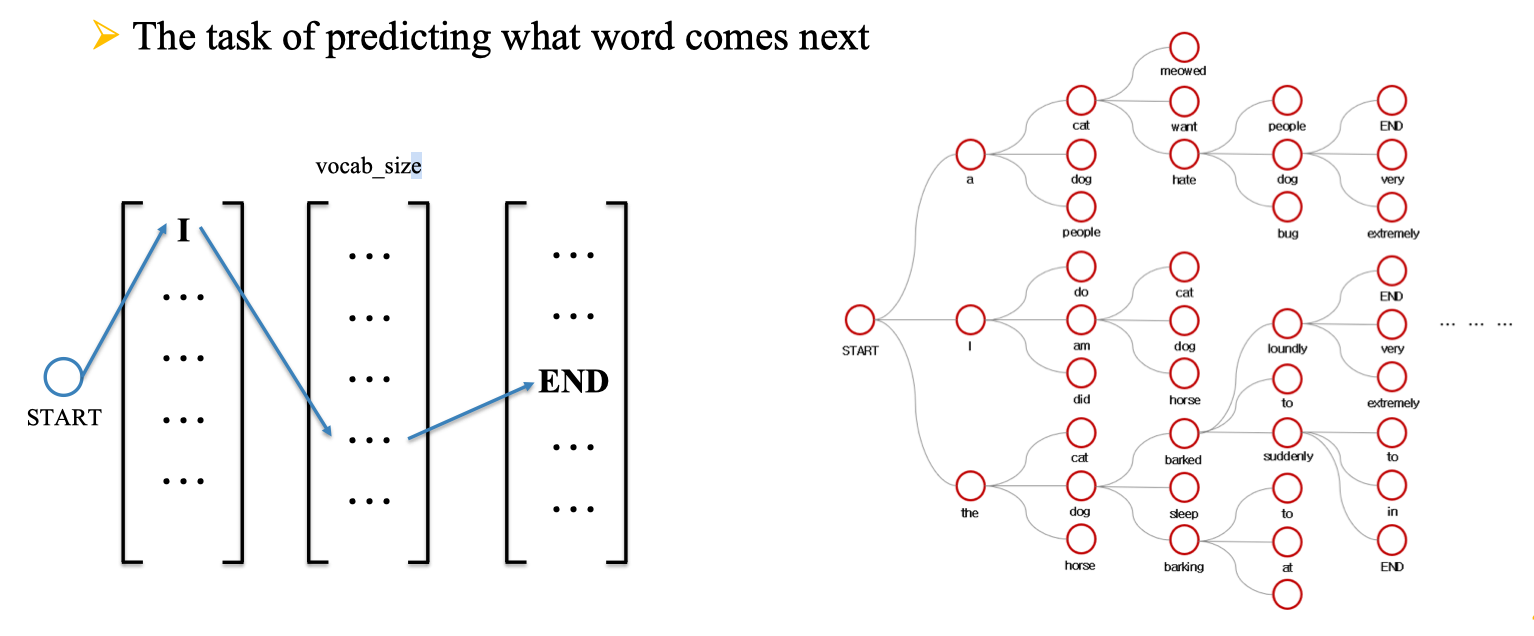
Nhưng một câu có thể dài hàng chục từ và số lượng khả năng kết hợp là rất lớn. Nếu mô hình phải nhớ toàn bộ lịch sử để dự đoán từ tiếp theo, lượng dữ liệu cần thiết để thống kê là không thể đáp ứng. Do đó ta cần một giả định đơn giản hơn: chỉ một phần nhỏ của lịch sử là đủ để dự đoán từ hiện tại. Đây chính là động lực của ý tưởng mô hình Markov và mô hình n-gram được xây dựng từ đó.
3. Từ xác suất câu đến xác suất điều kiện
Để mô hình hóa xác suất của một câu, chúng ta bắt đầu từ định nghĩa cơ bản của xác suất chuỗi. Nếu câu gồm n từ w₁ đến wₙ thì xác suất của cả câu bằng xác suất xảy ra đồng thời của toàn bộ các từ. Theo quy tắc chuỗi trong xác suất, ta có thể tách biểu thức này thành tích của các xác suất điều kiện, mỗi điều kiện dựa trên toàn bộ các từ phía trước. Cách biểu diễn này đảm bảo chính xác về mặt lý thuyết và mô tả đầy đủ mọi phụ thuộc có thể giữa các từ.
undefinedP(w_1, w_2, \dots, w_n) = \prod_{i=1}^{n} P(w_i)
undefined