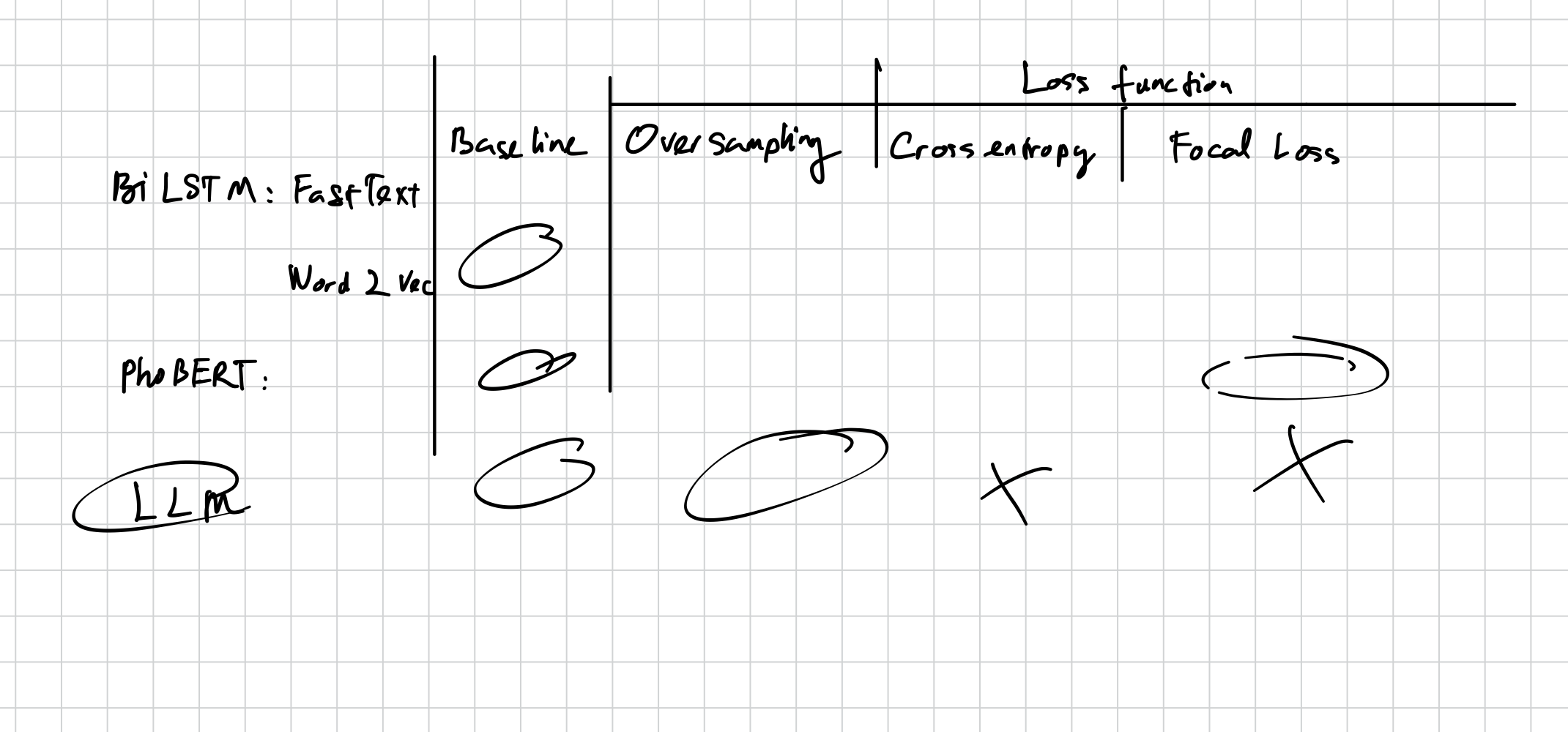
Các phương pháp xử lý imbalance
1. Xử lý data
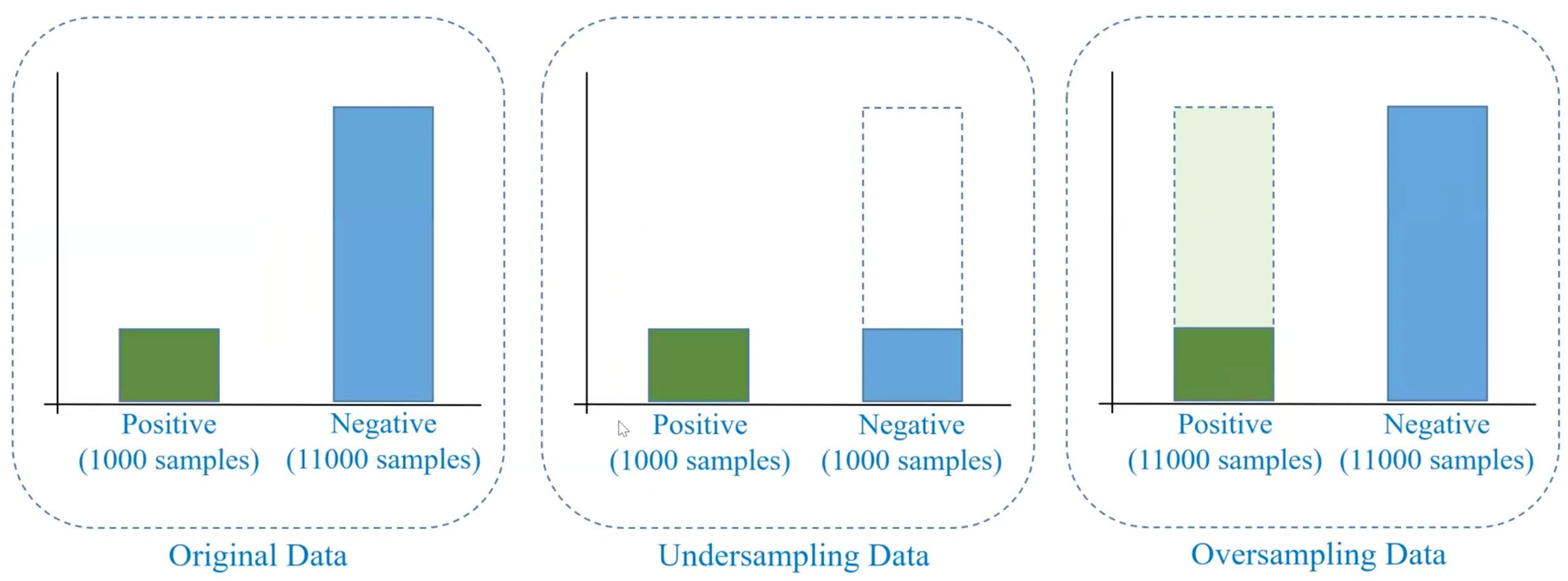
Undersampling
→ Xóa bớt dữ liệu
Oversampling
SMOTE (Synthetic Minority Over-sampling Technique)
- Tạo mẫu tổng hợp: SMOTE tạo các mẫu tổng hợp cho lớp thiểu số bằng cách lấy mẫu ngẫu nhiên các điểm dữ liệu từ lớp thiểu số, và sau đó tạo ra các điểm dữ liệu mới bằng cách nội suy (interpolation) giữa các điểm gần nhất trong không gian feature.
- Chọn điểm gần nhất: Đối với mỗi mẫu trong lớp thiểu số, SMOTE chọn điểm gần nhất (neighbors) của nó (thường ) trong không gian feature.
- Tạo điểm tổng hợp: Một điểm tổng hợp mới sẽ được tạo ra bằng cách nội suy giữa và một trong các điểm gần nhất . Công thức nội suy cho điểm tổng hợp là:
Trong đó:
- là điểm dữ liệu trong lớp thiểu số.
- là một trong các điểm gần nhất của .
- là một giá trị ngẫu nhiên từ [0, 1], xác định vị trí của điểm mới trong đoạn thẳng nối và .
- Lặp lại quá trình: Quá trình này được lặp lại cho tất cả các điểm trong lớp thiểu số để tạo ra đủ số lượng mẫu cho lớp thiểu số.
SMOTE trong Python với imbalanced-learn:
Thư viện imblearn trong Python cung cấp một cài đặt dễ sử dụng cho SMOTE. Dưới đây là một ví dụ về cách sử dụng SMOTE để xử lý mất cân bằng dữ liệu trong một bài toán phân loại.
- Cài đặt thư viện:
pip install imbalanced-learn- Sử dụng SMOTE:
import numpy as np
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
from collections import Counter
# Tạo một bộ dữ liệu phân loại với dữ liệu mất cân bằng
X, y = make_classification(n_samples=1000, n_features=20,
n_informative=2, n_redundant=10,
n_classes=2, weights=[0.1, 0.9],
flip_y=0, random_state=1)
# Kiểm tra phân bổ lớp ban đầu
print(f"Class distribution before SMOTE: {Counter(y)}")
# Áp dụng SMOTE
smote = SMOTE(sampling_strategy='auto', random_state=42)
X_res, y_res = smote.fit_resample(X, y)
# Kiểm tra phân bổ lớp sau khi áp dụng SMOTE
print(f"Class distribution after SMOTE: {Counter(y_res)}")Giải thích mã trên:
- make_classification: Tạo ra một bộ dữ liệu giả lập với 2 lớp (lớp 0 và lớp 1), trong đó lớp 0 có tỷ lệ rất ít (10% mẫu), còn lớp 1 chiếm phần lớn.
- SMOTE: Chúng ta sử dụng
SMOTEtừ imblearn để tạo các mẫu tổng hợp cho lớp thiểu số (lớp 0).sampling_strategy='auto'đảm bảo rằng số lượng mẫu trong lớp thiểu số sẽ được tăng lên bằng với lớp còn lại. - fit_resample: Áp dụng SMOTE để tạo ra các mẫu tổng hợp và trả về bộ dữ liệu mới với các mẫu được cân bằng giữa các lớp.
Kết quả phân bổ lớp:
- Trước khi áp dụng SMOTE: Chúng ta sẽ thấy rằng lớp thiểu số chiếm ít hơn 10% tổng số mẫu.
- Sau khi áp dụng SMOTE: Số lượng mẫu trong cả hai lớp sẽ được cân bằng (hoặc gần như cân bằng, tùy thuộc vào số lượng mẫu ban đầu của lớp thiểu số).
Ưu điểm và nhược điểm của SMOTE: Ưu điểm:
- Cải thiện độ chính xác: SMOTE giúp giảm thiểu vấn đề mất cân bằng dữ liệu, từ đó cải thiện hiệu quả của mô hình phân loại, đặc biệt là đối với các thuật toán như Decision Trees, SVM, và Logistic Regression.
- Tạo ra dữ liệu phong phú: SMOTE tạo ra các điểm dữ liệu tổng hợp, giúp mô hình học được đặc điểm của lớp thiểu số mà không cần phải sử dụng quá nhiều bộ dữ liệu.
Nhược điểm:
- Overfitting: Do tạo ra các mẫu tổng hợp, nếu không cẩn thận, SMOTE có thể dẫn đến overfitting (mô hình học quá kỹ các đặc điểm của lớp thiểu số).
- Không hợp lý với dữ liệu phân tán: SMOTE có thể tạo ra các mẫu tổng hợp không hợp lý nếu các điểm dữ liệu trong lớp thiểu số quá xa nhau trong không gian feature.
- Tăng chi phí tính toán: Việc tạo ra các mẫu tổng hợp làm tăng số lượng dữ liệu huấn luyện, từ đó có thể làm tăng chi phí tính toán.
2. Thay đổi hàm loss
Binary cross entropy
Focal loss
3. Sử dụng Pretrain Model
Ứng dụng trong bài