- I. Motivation
- II. Khả năng của PyTorch
- III. Thực hành làm quen
- IV. Mở rộng: Dynamic Computation Graph là gì?
Bài note tham khảo từ các nguồn: https://machinelearningcoban.com/, Slide AIO25, Chat GPT.
I. Motivation
Torch là một thư viện mã nguồn mở được thiết kế để xây dựng và huấn luyện các mô hình học sâu (deep learning). Phiên bản hiện đại và phổ biến nhất của nó là PyTorch, được phát triển bởi Facebook AI Research (FAIR) từ năm 2016. PyTorch cung cấp một hệ sinh thái linh hoạt và dễ sử dụng, hỗ trợ:
- Biểu diễn dữ liệu dưới dạng tensor (tương tự NumPy, nhưng có thể dùng GPU).
- Tự động tính gradient thông qua module
autograd. - Xây dựng mô hình bằng cách kế thừa từ
nn.Module, với các lớp mạng neural được định nghĩa rõ ràng. - Tối ưu hoá mô hình với
torch.optim.
1. Vì sao cần đến Torch?
Trong học sâu, mô hình thường có hàng triệu tham số và phải cập nhật liên tục qua quá trình lan truyền ngược (backpropagation). Việc tự cài đặt thủ công là không khả thi. PyTorch giúp:
- Tự động hóa quy trình tính toán đạo hàm và cập nhật tham số.
- Tận dụng GPU để tăng tốc tính toán.
- Viết mô hình theo phong cách lập trình động (dynamic computation graph), dễ kiểm tra và linh hoạt hơn nhiều framework khác. → Nghe khó hiểu đúng không. Hãy đọc phần mở rộng ở cuối bài viết.
2. Lý do sử dụng PyTorch
a. Cú pháp gần gũi với Python, dễ học PyTorch sử dụng eager execution – nghĩa là mô hình chạy ngay khi bạn viết code, giống hệt như Python thông thường. Điều này giúp bạn dễ dàng:
- In trung gian, debug từng bước.
- Viết code linh hoạt, không cần định nghĩa trước toàn bộ “graph” như TensorFlow 1.x.
- Dễ tiếp cận cho người mới học. Ví dụ:
x = torch.tensor([1.0, 2.0])
y = x ** 2 + 3
print(y)Code chạy ngay lập tức – không cần .session() hay .run().
b. Dễ debug nhờ chế độ eager execution.
c. Hỗ trợ mạnh mẽ cho GPU (qua CUDA).
d. Có cộng đồng lớn, tài liệu đầy đủ.
- PyTorch có một hệ sinh thái mở rộng:
torchvision,torchaudio,torchtext… - Tài liệu chính thức được viết rõ ràng, nhiều ví dụ thực tiễn.
- Nhiều khóa học, notebook, và dự án nguồn mở sử dụng PyTorch.
3. So sánh Torch với NumPy và TensorFlow
So với NumPy
Mặc dù NumPy rất mạnh trong xử lý mảng và đại số tuyến tính, nhưng không phù hợp để xây dựng mô hình deep learning, vì:
| Yếu tố | NumPy | PyTorch |
| Tự động tính gradient | ❌ Không có | ✅ Có autograd |
| Chạy trên GPU | ❌ Chỉ CPU | ✅ Dùng CUDA GPU dễ dàng |
| Xây dựng mô hình học sâu | ❌ Không hỗ trợ | ✅ Có nn.Module, torch.optim |
| Hệ sinh thái cho AI | ❌ Gần như không | ✅ Rất phát triển (torchvision, torchtext…) |
| Kết luận: NumPy rất tốt cho tiền xử lý hoặc các bài toán thuật toán cơ bản, nhưng không thể dùng trực tiếp cho huấn luyện mô hình học sâu. |
So với TensorFlow
TensorFlow là một framework học sâu đầy đủ tính năng, cạnh tranh trực tiếp với PyTorch. Tuy nhiên:
| Tiêu chí | PyTorch | TensorFlow (TF 2.x) |
| Cú pháp | Pythonic, dễ hiểu | Khá verbose |
| Debug | Eager execution theo từng dòng | Tương đương (TF 2.x đã cải thiện) |
| Tùy biến mô hình | Rất linh hoạt | Cần nhiều boilerplate code |
| Phù hợp với nghiên cứu | ✅ Rất phổ biến trong học thuật | ✅ Dùng nhiều trong production |
| Tài liệu & cộng đồng | Mạnh, thân thiện | Mạnh, thiên về production |
| Điểm mạnh của TensorFlow: hỗ trợ deployment tốt hơn (TensorFlow Serving, TFLite, TensorFlow.js), phù hợp cho các hệ thống lớn. | ||
| Nhưng PyTorch vẫn được ưa chuộng hơn trong cộng đồng học thuật và sinh viên vì: |
- Viết và chạy mô hình nhanh chóng (dynamic computation graph).
- Ít “cồng kềnh” hơn, dễ thử nghiệm.
II. Khả năng của PyTorch
1. Kiểu dữ liệu torch.Tensor
Giải thích:
torch.Tensor là kiểu dữ liệu cơ bản nhất trong PyTorch – nó giống như ndarray của NumPy nhưng mạnh hơn vì:
- Có thể chạy trên cả CPU và GPU.
- Hỗ trợ tính toán đạo hàm (
autograd). - Là đầu vào – đầu ra của mọi mô hình học sâu trong PyTorch. Ví dụ:
import torch
# Tạo một tensor 1 chiều
a = torch.tensor([1.0, 2.0, 3.0])
# Tạo tensor ngẫu nhiên 2x3 trên GPU (nếu có)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
b = torch.randn(2, 3).to(device)
print("Tensor a:", a)
print("Tensor b:", b)2. Hỗ trợ GPU
PyTorch tích hợp sẵn CUDA, giúp chuyển tensor sang GPU bằng .to(device) hoặc .cuda(). Điều này giúp:
- Tăng tốc huấn luyện mô hình đáng kể.
- Dễ viết mô hình chạy song song trên nhiều GPU (multi-GPU).
import torch
# Kiểm tra xem GPU có sẵn không
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Đang sử dụng thiết bị: {device}")
# Tạo tensor và chuyển nó lên GPU nếu có
x = torch.randn(1000, 1000)
y = torch.randn(1000, 1000)
x = x.to(device)
y = y.to(device)
# Thực hiện phép toán trên GPU
z = x @ y # Nhân ma trận
print(z.shape)Cài đặt Torch cho chip ARM apple
🔹 Bước 1: Cài Python ARM64 bản Homebrew
brew install pythonKiểm tra:
arch # Phải trả về arm64
python3 --version🔹 Bước 2: Tạo virtualenv
python3 -m venv .venv
source .venv/bin/activatepython -m pip install --upgrade pip setuptools wheel🔹 Bước 3: Cài **torch** bản ARM64 (CPU)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu✅ Đây là bản dành riêng cho macOS M1/M2 dùng CPU – tránh bug với CUDA hoặc Rosetta. 🧪 Kiểm tra Chạy test sau:
from transformers import pipeline
qa = pipeline("question-answering", model="distilbert-base-uncased-distilled-squad")
res = qa({
"question": "What is LangChain?",
"context": "LangChain is a framework to build LLM-based applications."
})
print(res)3. Tự động tính đạo hàm (**autograd**)
torch.autograd giúp bạn không cần viết lại thuật toán backpropagation bằng tay. PyTorch theo dõi toàn bộ lịch sử tính toán và tự động tính đạo hàm khi cần.
Điều này rất quan trọng vì:
- Huấn luyện mô hình deep learning phụ thuộc vào việc tính đạo hàm chính xác và nhanh.
- Giảm thiểu lỗi lập trình, tiết kiệm thời gian triển khai. Ví dụ:
import torch
# Tạo một tensor có yêu cầu tính gradient
x = torch.tensor([2.0], requires_grad=True)
# Một hàm số đơn giản: y = x^2 + 3x + 1
y = x**2 + 3*x + 1
# Tính đạo hàm của y theo x
y.backward() # Tự động lan truyền ngược (backpropagation)
# In kết quả đạo hàm tại x = 2.0
print(f"Giá trị đạo hàm tại x = 2.0 là: {x.grad.item()}")requires_grad=Trueyêu cầu PyTorch theo dõi mọi phép tính liên quan đếnx.- Hàm số ở đây là
y = x² + 3x + 1. y.backward()sẽ tự động áp dụng đạo hàm và tínhdy/dx. Ứng dụng trong học sâu: Khi huấn luyện một mô hình, PyTorch sẽ:
- Tự động theo dõi các phép toán (như trên).
- Khi gọi
loss.backward(), nó tự động tính toán đạo hàm của hàm mất mát theo các tham số của mô hình. - Sau đó, dùng các đạo hàm đó để cập nhật trọng số thông qua
optimizer.step(). → Nhờautograd, bạn không cần viết lại thuật toán lan truyền ngược bằng tay, giúp tránh sai sót và tiết kiệm công sức lập trình.
4. Mô hình hóa rõ ràng với **nn.Module**
Mỗi mạng neural được xây dựng như một lớp Python kế thừa từ nn.Module, giúp:
- Mô hình hoá rõ ràng các tầng (layers) và tham số.
- Dễ lưu, load, và chia sẻ mô hình (sử dụng
state_dict). - Linh hoạt để mở rộng hoặc thay đổi cấu trúc mô hình khi cần. Ví dụ:
import torch
import torch.nn as nn
import torch.optim as optim
# 1. Tạo dữ liệu huấn luyện (giả lập)
# y = 2x + 1
x_train = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y_train = torch.tensor([[3.0], [5.0], [7.0], [9.0]])
# 2. Định nghĩa mô hình với nn.Module
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # 1 input, 1 output
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()
# 3. Khai báo hàm mất mát (loss function) và bộ tối ưu (optimizer)
criterion = nn.MSELoss() # Mean Squared Error
optimizer = optim.SGD(model.parameters(), lr=0.01) # Stochastic Gradient Descent
# 4. Vòng lặp huấn luyện (training loop)
for epoch in range(200):
# Forward pass
outputs = model(x_train)
loss = criterion(outputs, y_train)
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
# In loss mỗi 20 vòng lặp
if (epoch+1) % 20 == 0:
print(f"Epoch [{epoch+1}/200], Loss: {loss.item():.4f}")
# 5. Dự đoán
x_test = torch.tensor([[5.0]])
predicted = model(x_test).item()
print(f"Dự đoán với x=5.0: y ≈ {predicted:.2f}")
>>
Epoch [20/200], Loss: 1.1234
...
Epoch [200/200], Loss: 0.0001
Dự đoán với x=5.0: y ≈ 11.01Ví dụ với nn.Linear
nn.Linear(in_features, out_features) là lớp biểu diễn một tầng (layer) tuyến tính, còn gọi là fully-connected layer hoặc dense layer.
Nó thực hiện phép biến đổi toán học sau:
Trong đó:
- : đầu vào (input vector),
- : ma trận trọng số (weights),
- : vector độ lệch (bias),
- : đầu ra (output vector).
linear = nn.Linear(in_features=3, out_features=2)in_features = 3: đầu vào có 3 phần tử (ví dụ:[x1, x2, x3])out_features = 2: đầu ra có 2 phần tử (ví dụ:[y1, y2])- Bạn có thể xâu chuỗi nhiều tầng
Linearđể xây mô hình nhiều lớp. nn.Linearđi kèm vớirequires_grad=True, nên PyTorch sẽ tự động học các tham sốWvàbtrong quá trình huấn luyện.
5. Các thuật toán tối ưu torch.optim
Để giải bài toán tìm điểm global optimal của hàm mất mát thì ta sẽ dùng các thuật toán tối ưu và torch.optim là module chứa các thuật toán tối ưu như:
- SGD (Stochastic Gradient Descent) – đơn giản, dễ hiểu.
- Adam (Adaptive Moment Estimation) – hiệu quả và phổ biến hơn.
- RMSprop, Adagrad,…
Chúng dùng để cập nhật trọng số mô hình trong quá trình huấn luyện, dựa trên gradient tính bởi
autograd. 📌 Ví dụ:
import torch
import torch.nn as nn
import torch.optim as optim
# Mô hình tuyến tính: y = wx + b
model = nn.Linear(1, 1)
# Tối ưu bằng Adam
optimizer = optim.Adam(model.parameters(), lr=0.01)
# Tính loss và cập nhật
x = torch.tensor([[1.0]])
y = torch.tensor([[2.0]])
criterion = nn.MSELoss()
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()Giới thiệu về Adam (Adaptive Moment Estimation)
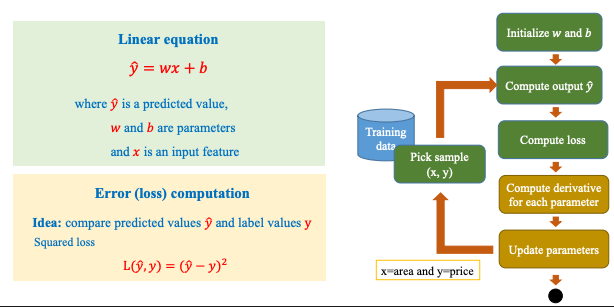 Xem bài:
Gradient Descent
Là một thuật toán tối ưu kết hợp ưu điểm của Momentum và RMSprop. Adam được thiết kế để tự động điều chỉnh tốc độ học (learning rate) cho từng tham số trong quá trình huấn luyện.
So sánh với các thuật toán đi tìm cực trị khác:
Hãy tưởng tượng bạn đang đạp xe xuống một ngọn đồi để tìm điểm thấp nhất (giống như tìm giá trị loss nhỏ nhất):
Xem bài:
Gradient Descent
Là một thuật toán tối ưu kết hợp ưu điểm của Momentum và RMSprop. Adam được thiết kế để tự động điều chỉnh tốc độ học (learning rate) cho từng tham số trong quá trình huấn luyện.
So sánh với các thuật toán đi tìm cực trị khác:
Hãy tưởng tượng bạn đang đạp xe xuống một ngọn đồi để tìm điểm thấp nhất (giống như tìm giá trị loss nhỏ nhất):
- SGD thường: mỗi lần đạp đều cùng lực, không quan tâm địa hình.
- Momentum: giống như thả xe đạp xuống núi, khi lao dốc sẽ vẫn còn moment và chạy luôn lên dốc bên kia → chậm hội tụ
- Adam: tự điều chỉnh lực đạp cho từng bánh xe dựa trên độ dốc (gradient) hiện tại. Ưu điểm của Adam
- Tự động điều chỉnh learning rate theo từng tham số.
- Ổn định hơn SGD khi dữ liệu có nhiễu.
- Không cần tuning quá nhiều tham số. Nhược điểm
- Đôi khi hội tụ chậm hơn SGD trong một số bài toán đơn giản.
- Có thể “dừng sớm” ở cực tiểu cục bộ.
6. Thư viện torchvision
torchvision là thư viện phụ trợ của PyTorch dành riêng cho xử lý ảnh. Nó cung cấp:
- Các dataset phổ biến: MNIST, CIFAR-10, ImageNet,…
- Các transform: resize, normalize, crop, to tensor,…
- Các mô hình tiền huấn luyện: ResNet, VGG, MobileNet,… 📌 Ví dụ:
from torchvision import datasets, transforms
# Tải dataset MNIST (ảnh số viết tay)
mnist_data = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transforms.ToTensor() # Biến ảnh thành tensor
)
# Lấy 1 ảnh và nhãn
image, label = mnist_data[0]
print("Kích thước ảnh:", image.shape) # (1, 28, 28)
print("Nhãn:", label)
So sánh torchvision vs OpenCV
| Tiêu chí | torchvision | OpenCV (cv2) |
| Mục tiêu | Hỗ trợ xử lý ảnh trong học sâu PyTorch | Xử lý ảnh tổng quát & real-time |
| Định dạng ảnh | Tensor (CHW, chuẩn hóa) | NumPy array (HWC, BGR) |
| Hỗ trợ mô hình học sâu | ✅ Có (model pre-trained) | ❌ Không tích hợp (nhưng dùng được TensorFlow) |
| Làm việc với PyTorch | ✅ Tích hợp trực tiếp | Cần chuyển đổi dữ liệu (ndarray ↔ tensor) |
| Ứng dụng video/webcam | ❌ Không | ✅ Có sẵn công cụ mạnh mẽ |
III. Thực hành làm quen
Bài 1.
Huấn luyện một mô hình dự đoán đầu ra từ đầu vào , biết rằng dữ liệu tuân theo hàm: Bước 1: Tạo dữ liệu Yêu cầu:
-
Tạo một tập dữ liệu gồm các cặp giá trị (x,y)(x, y)(x,y) theo công thức y=3x+2y = 3x + 2y=3x+2.
-
Thêm nhiễu nhẹ (dùng
torch.randn) để mô phỏng dữ liệu thực tế. -
Gợi ý code:
import torch # Tạo dữ liệu đầu vào x_train = torch.unsqueeze(torch.linspace(-10, 10, 100), dim=1) # shape: (100, 1) y_train = 3 * x_train + 2 + torch.randn(x_train.size()) * 2 # thêm nhiễu
Bước 2: Khởi tạo model, loss, optimizer Yêu cầu:
-
Xây dựng một mô hình hồi quy tuyến tính đơn giản y=wx+by = wx + by=wx+b bằng
nn.Linear. -
Sử dụng
MSELossvà tối ưu bằngAdam. -
Gợi ý code:
import torch.nn as nn import torch.optim as optim # Định nghĩa mô hình model = nn.Linear(in_features=1, out_features=1) # Hàm mất mát (loss function) loss_fn = nn.MSELoss() # Optimizer optimizer = optim.Adam(model.parameters(), lr=0.01)
Bước 3: Lặp qua các epoch để cập nhật trọng số Yêu cầu:
-
Lặp trong 500 epoch.
-
Mỗi epoch gồm: forward → tính loss → backward → cập nhật optimizer.
-
In loss mỗi 50 epoch.
-
Gợi ý code:
for epoch in range(500): # Forward pass predictions = model(x_train) loss = loss_fn(predictions, y_train) # Backward pass và cập nhật trọng số optimizer.zero_grad() loss.backward() optimizer.step() # In loss định kỳ if (epoch + 1) % 50 == 0: print(f"Epoch {epoch+1}: Loss = {loss.item():.4f}")
Thử nghiệm mô hình:
- Dự đoán giá trị khi
- In ra trọng số và bias mô hình sau huấn luyện
x_test = torch.tensor([[4.0]])
y_pred = model(x_test).item()
print(f"Dự đoán với x = 4.0: y ≈ {y_pred:.2f}")
# In trọng số và bias
print("Trọng số w:", model.weight.item())
print("Bias b:", model.bias.item())Kết quả mong đợi:
- Trọng số xấp xỉ 3, bias xấp xỉ 2
- Loss tiến dần về gần 0
- Dự đoán với
x=4.0ra gần 14.0
IV. Mở rộng: Dynamic Computation Graph là gì?
Torch hỗ trợ viết mô hình theo phong cách lập trình động (dynamic computation graph), dễ kiểm tra và linh hoạt hơn nhiều framework khác.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleDynamicNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 10)
def forward(self, x):
# Tùy vào tổng các phần tử trong x, chọn nhánh khác nhau
if x.sum() > 0:
x = self.fc1(x)
else:
x = self.fc2(x)
return F.relu(x)
# Khởi tạo mô hình
model = SimpleDynamicNet()
# Tạo dữ liệu ngẫu nhiên
x = torch.randn(5, 10)
# Chạy forward pass
output = model(x)
print(output)- Trong hàm
forward, ta kiểm tra điều kiệnx.sum() > 0.- Nếu đúng → chạy qua tầng
fc1. - Nếu sai → chạy qua tầng
fc2.
- Nếu đúng → chạy qua tầng
- Điều này nghĩa là: mỗi lần chạy, mô hình có thể chọn đường khác nhau để xử lý dữ liệu.
- PyTorch cho phép bạn dùng bất kỳ câu lệnh Python nào như
if,for,while… trongforward()— vì nó tạo đồ thị tính toán ngay lúc chạy.
1. Computation graph
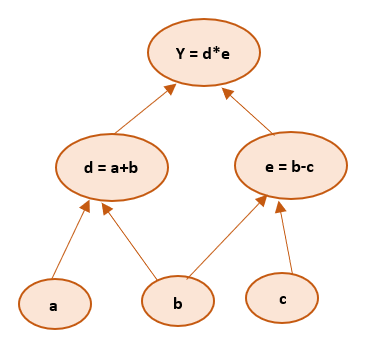 Trong học sâu, một đồ thị tính toán (computation graph) là sơ đồ biểu diễn các phép toán được thực hiện để tính ra giá trị đầu ra từ đầu vào — và đặc biệt quan trọng để tính đạo hàm (gradient) khi huấn luyện mô hình.
Ví dụ:
Giả sử ta có công thức:
Khi máy tính thực hiện phép tính này, ta có thể vẽ ra một đồ thị các bước tính toán như sau:
Trong học sâu, một đồ thị tính toán (computation graph) là sơ đồ biểu diễn các phép toán được thực hiện để tính ra giá trị đầu ra từ đầu vào — và đặc biệt quan trọng để tính đạo hàm (gradient) khi huấn luyện mô hình.
Ví dụ:
Giả sử ta có công thức:
Khi máy tính thực hiện phép tính này, ta có thể vẽ ra một đồ thị các bước tính toán như sau:
x ──▶ x²
│
x ──▶ 3x
▼
( + ) ──▶ + 1 ──▶ yTại sao cần đồ thị? Vì để huấn luyện mô hình, ta phải:
- Tính đầu ra (
forward pass) - Tính đạo hàm của loss với từng tham số (
backward pass) → cần biết mọi phép tính đã thực hiện. PyTorch dùng autograd để tự động xây dựng đồ thị tính toán trong lúc chạy, rồi dùng đồ thị này để tính đạo hàm bằng quy tắc chain rule.
Nói thêm về Chain Rule
Chain Rule là đạo hàm của hàm hợp — tức là khi một hàm được “gắn” bên trong một hàm khác:
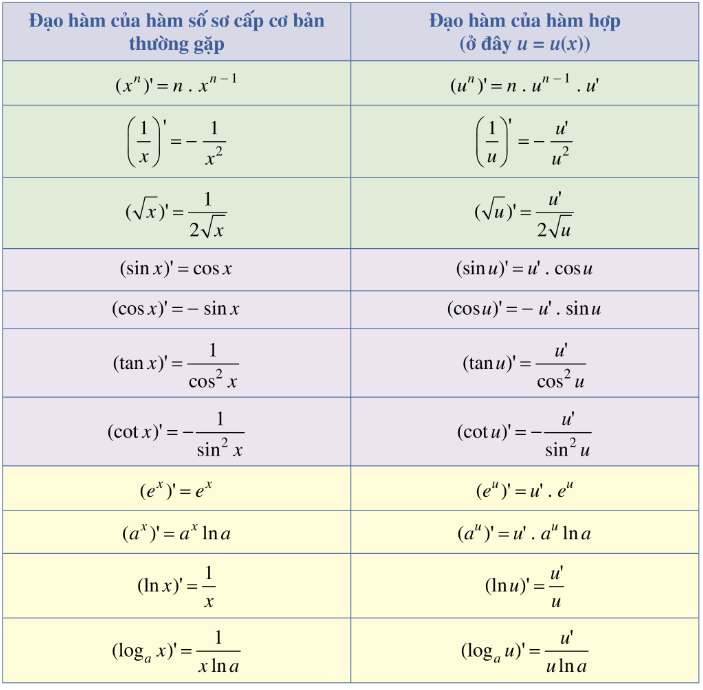 Nhớ cấp 3 học bảng đạo hàm của không → Đó là quy tắc Chain Rule: đọa hàm của hàm hợp.
Nhớ cấp 3 học bảng đạo hàm của không → Đó là quy tắc Chain Rule: đọa hàm của hàm hợp.
Thì đạo hàm của y theo x được tính theo công thức: Ví dụ: Giả sử:
undefined