Table of Content
Important
Mục tiêu
Bài note này tổng hợp kiến thức từ slide “Basic Pandas” – bài học về thư viện Pandas cho phân tích dữ liệu. Nội dung tập trung vào ba mảng chính:
- Series và DataFrame: hai cấu trúc dữ liệu chủ lực của Pandas.
- Phân tích dữ liệu dạng bảng với bộ dữ liệu Pokémon: đọc/ghi file, miêu tả dữ liệu, truy xuất cột và hàng, sắp xếp, lọc, nhóm.
- Phân tích dữ liệu chuỗi thời gian (time series) với bộ dữ liệu Daily Minimum Temperatures: thiết lập chỉ số thời gian, tạo thuộc tính ngày tháng, chuyển đổi kiểu dữ liệu, trực quan hóa và resampling.
1. Giới thiệu Pandas
Pandas là thư viện xây dựng trên NumPy, cung cấp cấu trúc dữ liệu dễ sử dụng và các công cụ phân tích dữ liệu cho Python. Bạn có thể cài đặt qua pip:
!pip install pandas
import pandas as pd
pd.__version__ # phiên bản hiện tạiData Analysis là quá trình kiểm tra, làm sạch, chuyển đổi và mô hình hóa dữ liệu nhằm rút ra thông tin hữu ích, đưa ra kết luận và hỗ trợ ra quyết định.
1.1 Cấu trúc dữ liệu
-
DataFrame: bảng hai chiều có nhãn ở cột và chỉ số ở hàng. Các cột có thể chứa nhiều kiểu dữ liệu khác nhau. Ví dụ:
Index Name Gender 0 A M 1 B F 2 C F 3 D M -
Series: mảng một chiều có nhãn, dùng làm cột hoặc giữ dữ liệu độc lập. Mỗi giá trị có một index. Có thể xem Series là cột đơn của DataFrame.
-
Nếu không định nghĩa thì index sẽ là từ 0 → n
-
Các index tự định nghĩa
import pandas as pd s = pd.Series([10, 20, 30], index=['a', 'b', 'c']) print(s) # Kết quả: # a 10 # b 20 # c 30 # dtype: int64‼ Ở đây index có thể trùng nhau. Điều này là không thể đối với cấu trúc dữ liệu Dict.
-
-
Panel: cấu trúc dữ liệu 3 chiều (3D), được dùng để xử lý dữ liệu kiểu bảng nhiều lớp (giống như một tập hợp các DataFrame xếp chồng lên nhau). Tuy nhiên, Panel đã bị deprecated (ngừng phát triển và loại bỏ khỏi Pandas từ phiên bản 1.0 trở đi).
2. Phân tích dữ liệu
Bộ dữ liệu Pokémon.csv chứa thông tin về các Pokémon. Dưới đây là các thao tác cơ bản với Pandas sử dụng dataset này.
2.1 Đọc và ghi file
-
Đọc CSV:
import pandas as pd df = pd.read_csv("path/to/Pokemon.csv") -
Ghi ra CSV hoặc Excel:
df.to_csv("pokemon_out.csv", index=False) # lưu CSV, không kèm cột index df.to_excel("pokemon_out.xlsx", index=False) # lưu Excel df.to_csv("pokemon_tab.tsv", sep="\t") # dùng ký tự tab
2.2 Khám phá dữ liệu
df.describe()– trả về thống kê tổng quát cho các cột số.df.head(n)/df.tail(n)– xem n dòng đầu hoặc cuối.
2.3 Truy xuất và thay đổi cột
-
Lấy cột cụ thể:
df[["Name", "Type 1"]]trả về DataFrame chứa hai cột. -
Xóa cột:
df.drop(columns=["Type 2"]). -
Thêm cột:
df["Total"] = df["HP"] + df["Attack"] + df["Defense"] + df["Sp. Atk"] + df["Sp. Def"] + df["Speed"] -
Sắp xếp lại thứ tự cột: tạo danh sách cột theo thứ tự mong muốn rồi chọn
df = df[columns_order].
2.4 Truy xuất và lọc hàng
Truy xuất hàng theo chỉ số (index)
a) Lấy một dòng theo vị trí (integer)
df.iloc[3] # Lấy dòng thứ 4 (đếm từ 0)b) Lấy nhiều dòng liên tục
df.iloc[2:5] # Lấy dòng thứ 3 đến 5 (2,3,4)c) Lấy dòng theo vị trí cụ thể
df.iloc[[0, 2, 4]] # Lấy dòng 1, 3, 5Truy xuất hàng theo nhãn (label)
a) Lấy dòng theo index label
df.loc['2024-06-30'] # Khi index là ngày/thời gian hoặc chuỗib) Lấy nhiều dòng theo label
df.loc[['2024-06-30', '2024-07-01']]Lấy dòng theo dải label
df.loc['2024-06-30':'2024-07-05'] # Lấy tất cả các dòng từ 30/6 đến 5/7Lọc hàng theo điều kiện
a) Lọc với điều kiện một cột
df[df['Close'] > 25]
# hoặc
df[df.Close > 25]b) Lọc với nhiều điều kiện
df[(df['Close'] > 25) & (df['Volume'] > 1000000)]
# hoặc dùng | cho điều kiện "hoặc"
df[(df['Close'] > 25) | (df['Volume'] > 1000000)]c) Lọc với .loc (chuẩn, an toàn cho mọi trường hợp)
df.loc[df['Close'] > 25]-
Lọc bằng regex:
df[ df["Name"].str.contains("^A[a-z]*", regex=True) ]– chọn tên Pokémon bắt đầu bằng chữ A. -
Sắp xếp:
df.sort_values(by="HP", ascending=False). -
Reset index:
df.reset_index(drop=True, inplace=True). -
Nhóm (groupby): tổng hợp theo một thuộc tính, ví dụ tính trung bình HP theo hệ:
df.groupby("Type 1")["HP"].mean()
2.5 Xử lý dữ liệu NaN (Not a Number, giá trị thiếu)
Kiểm tra giá trị NaN
Kiểm tra toàn bộ bảng (DataFrame) có giá trị NaN
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, np.nan],
'B': [np.nan, 5, 6]
})
# Kiểm tra ô nào là NaN
print(df.isnull())- Trả về một DataFrame boolean, True tại vị trí có NaN.
Đếm tổng số giá trị NaN theo từng cột
# Số lượng giá trị NaN trong mỗi cột
print(df.isnull().sum())- Thường dùng để nhanh chóng biết cột nào có thiếu dữ liệu.
Đếm tổng số giá trị NaN toàn bảng
# Tổng số giá trị NaN trong toàn bảng
print(df.isnull().sum().sum())Kiểm tra từng dòng có chứa NaN không
# Kiểm tra dòng nào có ít nhất 1 giá trị NaN
print(df.isnull().any(axis=1))Lọc ra tất cả dòng có ít nhất 1 NaN
# Chỉ hiện các dòng có giá trị NaN
print(df[df.isnull().any(axis=1)])Kiểm tra 1 cột có giá trị NaN không
print(df['A'].isnull())Ghi chú
isnull()vàisna()giống nhau, đều dùng để kiểm tra NaN.- Tìm giá trị không phải NaN thì dùng
notnull()hoặcnotna().
Drop giá trị NaN
1. Bỏ tất cả các hàng có ít nhất 1 giá trị NaN
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, np.nan],
'B': [np.nan, 5, 6]
})
df_no_null = df.dropna()
print(df_no_null)Giải thích:
- Chỉ giữ lại các dòng mà không có giá trị NaN nào.
- Dòng nào có ít nhất một giá trị NaN sẽ bị loại bỏ.
2. Bỏ hàng chỉ khi tất cả giá trị đều là NaN
df_no_null = df.dropna(how='all')- Dòng chỉ bị bỏ nếu toàn bộ giá trị đều là NaN.
3. Bỏ hàng có NaN ở một số cột nhất định
df_no_null = df.dropna(subset=['A'])- Chỉ loại bỏ dòng nếu cột A có NaN (các cột khác vẫn giữ nếu A có giá trị).
4. Xoá giá trị NaN trên cột (không phải dòng)
df_no_null_col = df.dropna(axis=1)- Xoá toàn bộ cột có ít nhất một giá trị NaN.
5. Thay đổi trực tiếp trên DataFrame gốc
df.dropna(inplace=True)- Không tạo DataFrame mới, mà cập nhật trực tiếp bảng gốc. Tóm tắt:
df.dropna()→ Bỏ tất cả dòng có NaN.df.dropna(axis=1)→ Bỏ tất cả cột có NaN.df.dropna(subset=['col1', 'col2'])→ Bỏ dòng có NaN ở các cột chỉ định.inplace=True→ Cập nhật trực tiếp trên DataFrame.
Các phương pháp fill dữ liệu bị mất (missing value)
- Điền bằng một giá trị cố định (hằng số)
df_filled = df.fillna(0) # Điền tất cả NaN thành 0
df_filled = df.fillna("Chưa biết") # Chuỗi cho dữ liệu text- Ưu điểm: Nhanh, đơn giản.
- Nhược: Có thể không phản ánh đúng thực tế.
- Điền bằng giá trị trung bình, trung vị, mode (cho cột số)
df['A'] = df['A'].fillna(df['A'].mean()) # Trung bình
df['B'] = df['B'].fillna(df['B'].median()) # Trung vị
df['C'] = df['C'].fillna(df['C'].mode()[0]) # Mode (giá trị xuất hiện nhiều nhất)- Dùng cho: Số liệu liên tục, phân phối không lệch quá nhiều.
- Điền bằng giá trị gần kề (forward fill / backward fill)
df.fillna(method='ffill', inplace=True) # forward fill: lấy giá trị trước đó
df.fillna(method='bfill', inplace=True) # backward fill: lấy giá trị sau đó- Dùng cho: Dữ liệu chuỗi thời gian (time series), khi giá trị gần nhau có tính liên kết.
- Điền bằng giá trị ở cột hoặc dòng tương ứng (theo group)
df['A'] = df.groupby('Group')['A'].transform(lambda x: x.fillna(x.mean()))- Dùng cho: Khi muốn điền giá trị theo từng nhóm (ví dụ: trung bình lương theo phòng ban).
- Điền bằng giá trị nội suy (interpolate)
df['A'] = df['A'].interpolate(method='linear')- Dùng cho: Chuỗi số học, đặc biệt dữ liệu đo liên tục theo thời gian.
2.6. apply() functions
Apply functions được dùng khi ta muốn thực thi một hàm nào đó lên các hàng trong bảng dữ liệu. Sau khi thực thi, kết quả trả về từ hàm chính là giá trị mới của hàng tương ứng.
series.apply(func, convert_dtype=True, args=(), **kwargs)func: Hàm bạn muốn thực hiện trên mỗi phần tử (có thể là lambda, hàm tự định nghĩa, hoặc hàm có sẵn).args: Tham số bổ sung cho hàm.*kwargs: Các keyword arguments cho hàm. Ví dụ: ta muốn phân loại phim theo ba mức độ [“Good”, “Average”, “Bad”] dựa trên Rating, ta có thể định nghĩa một hàm để làm đều này và apply nó lên DataFrame.
# Apply function: Phân loại phim theo rating
def rating_group(rating):
if rating >= 7.5:
return 'Good'
elif rating >= 6.0:
return 'Average'
else:
return 'Bad'
data['Rating_category'] = data['Rating'].apply(rating_group)
data[['Title', 'Director', 'Rating', 'Rating_category']].head()3. Phân tích dữ liệu chuỗi thời gian
Sử dụng bộ dữ liệu Daily Minimum Temperatures để làm quen với thao tác trên chuỗi thời gian.
3.1 Đọc dữ liệu và thiết lập index thời gian
import pandas as pd
weather = pd.read_csv("daily-min-temp.csv")
weather["Date"] = pd.to_datetime(weather["Date"], format="%Y-%m-%d")
weather.set_index("Date", inplace=True)-
Khi cột Date là duy nhất, chuyển thành index giúp thao tác thuận tiện.
-
Có thể thêm các cột weekday, month, year:
weather["weekday"] = weather.index.weekday weather["month"] = weather.index.month weather["year"] = weather.index.year
3.2 Chuyển đổi kiểu dữ liệu
Một số cột có thể được đọc dưới dạng object (chuỗi). Dùng astype() để chuyển sang kiểu số, ví dụ:
weather["Temp"] = weather["Temp"].astype(float)3.3 Truy xuất theo thời gian và trực quan hóa
-
Indexing: chọn theo ngày tháng năm, ví dụ
weather.loc["1990-01"](toàn bộ tháng 01/1990). -
Visualize: dùng Matplotlib hoặc Pandas để vẽ:
python CopyEdit weather["Temp"].plot(figsize=(10,4), title="Daily Minimum Temperatures") -
Seasonality: phân tích tính mùa vụ bằng cách vẽ theo tháng hoặc năm.
3.4 Tần suất (Frequencies) và Resampling
- Tần suất cao/thấp: dữ liệu theo giờ, ngày, tuần, tháng,…
Resampling
Resample là kỹ thuật thay đổi tần số lấy mẫu dữ liệu (thường dùng cho dữ liệu chuỗi thời gian – time series). Các lý do cần resampling:
- Đồng bộ dữ liệu với mục tiêu phân tích
- Dữ liệu gốc có thể chi tiết theo ngày, nhưng báo cáo/thống kê lại cần tổng kết theo tuần, tháng, quý hoặc năm.
- Ví dụ: Dự báo doanh thu theo tháng, hoặc so sánh xu hướng mùa vụ.
- Làm mượt tín hiệu, giảm nhiễu
- Dữ liệu theo ngày có thể dao động mạnh (nhiễu), khó quan sát xu hướng dài hạn.
- Resample lên tuần/tháng giúp nhìn rõ hơn các pattern tổng thể, loại bỏ biến động nhỏ.
- Tối ưu tốc độ và tài nguyên tính toán
- Dữ liệu gốc quá dày, không cần thiết phải phân tích từng mốc nhỏ nhất.
- Downsampling giảm kích thước dữ liệu, tăng tốc độ xử lý.
- Chuẩn hóa tần suất để ghép nối, so sánh
- Khi ghép nối nhiều nguồn dữ liệu, các nguồn có thể có tần suất khác nhau.
- Cần resample để đồng bộ về cùng tần suất (ví dụ: cả hai đều về tuần/tháng).
- Xử lý dữ liệu thiếu (missing values)
- Khi upsampling (ví dụ từ tháng về ngày), xuất hiện nhiều giá trị thiếu, cần resample để điền (fill) hoặc nội suy (interpolate).
- Chuẩn bị dữ liệu cho mô hình dự báo/thống kê
- Một số mô hình yêu cầu dữ liệu có tần suất đều đặn, không thiếu giá trị.
- Resample giúp tạo ra time series đều đặn, phù hợp yêu cầu thuật toán
Có hai kiểu phổ biến:
- Downsampling: Giảm tần suất (ví dụ: từ ngày → tuần, từ tuần → tháng)
- Upsampling: Tăng tần suất (ví dụ: từ tháng → ngày) Ví dụ:
# Resampling: Downsample từ ngày sang tuần (mean)
data_columns = ['Consumption', 'Wind', 'Solar', 'Wind+Solar']
opsd_weekly_mean = opsd_daily[data_columns].resample('W').mean()
opsd_weekly_mean.head()resample('W'): Gom nhóm dữ liệu theo tuần (W = Week)..mean(): Lấy giá trị trung bình mỗi tuần cho từng cột.- Kết quả là một DataFrame mới, mỗi dòng là 1 tuần, cột là giá trị trung bình tuần đó.
3.5. Rolling windows
Rolling window (cửa sổ trượt) là một kỹ thuật cực kỳ quan trọng khi phân tích chuỗi thời gian (time series) trong pandas. Nó giúp bạn tính các chỉ số thống kê (trung bình, tổng, min, max…) trong một cửa sổ liên tiếp gồm n phần tử, và “trượt” cửa sổ này qua từng mốc thời gian. Tác dụng của rolling windows
- Làm mượt dữ liệu, phát hiện trend ngắn hạn và loại bỏ nhiễu.
- Tính toán các chỉ số động như moving average, rolling sum, rolling std, rolling median…
- Phân tích biến động ngắn hạn, phát hiện bất thường trong chuỗi số liệu. Ví dụ:
# Rolling windows: 7 ngày, 365 ngày
opsd_7d = opsd_daily[data_columns].rolling(7, center=True).mean()
opsd_365d = opsd_daily[data_columns].rolling(window=365, center=True, min_periods=360).mean()
import matplotlib.dates as mdates
fig, ax = plt.subplots()
ax.plot(opsd_daily['Consumption'], marker='.', markersize=2, color='0.6', linestyle='None', label='Daily')
ax.plot(opsd_7d['Consumption'], linewidth=2, label='7-d Rolling Mean')
ax.plot(opsd_365d['Consumption'], color='0.2', linewidth=3, label='Trend (365-d Rolling Mean)')
ax.xaxis.set_major_locator(mdates.YearLocator())
ax.legend()
ax.set_xlabel('Year')
ax.set_ylabel('Consumption (GWh)')
ax.set_title('Trends in Electricity Consumption')
plt.show()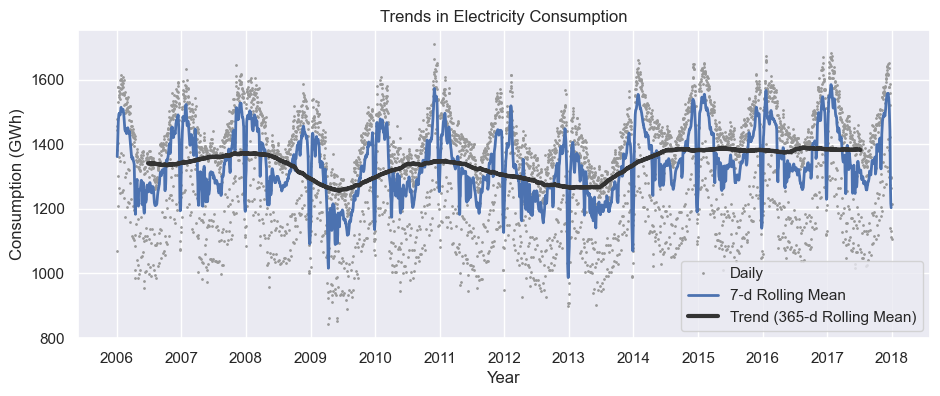 Một số rolling function hay dùng
Một số rolling function hay dùng
.rolling(window).mean()→ Trung bình động (moving average).rolling(window).sum()→ Tổng động.rolling(window).std()→ Độ lệch chuẩn động.rolling(window).min()→ Giá trị nhỏ nhất trong cửa sổ.rolling(window).max()→ Giá trị lớn nhất trong cửa sổ.rolling(window).median()→ Trung vị động
4. Kết luận
Bài học giới thiệu các thao tác cơ bản với Pandas trên dữ liệu dạng bảng và chuỗi thời gian:
- Nắm vững hai cấu trúc dữ liệu chính: Series và DataFrame.
- Thực hành đọc/ghi, miêu tả, sắp xếp, lọc và nhóm dữ liệu trên bộ dữ liệu Pokémon.
- Làm việc với dữ liệu Time Series: thiết lập chỉ số thời gian, thêm thuộc tính ngày tháng, chuyển đổi kiểu dữ liệu, trực quan hóa và resampling. Bạn có thể áp dụng các kiến thức này làm nền tảng cho các bài thực hành nâng cao với Pandas.