Table of Content
Important
Tham khảo
I. Series in Pandas
Nhắc lại: Series là một cấu trúc dữ liệu 1 chiều, có thể lưu trữ bất kỳ kiểu dữ liệu nào (số, chuỗi, đối tượng Python…). Mỗi phần tử trong Series có một index (chỉ mục) và một value (giá trị). Ngoài ra, Series còn có thể có tên để mô tả nội dung dữ liệu.
1. Simple functions
Create a series
Tạo danh sách số nguyên:
Ví dụ dưới đây tạo một Series tên là num_dropped từ danh sách [5, 7, 5, 1, 6]:
import pandas as pd
data = pd.Series([5, 7, 5, 1, 6], name='num_dropped')Kết quả:
| Index | Value |
|---|---|
| 0 | 5 |
| 1 | 7 |
| 2 | 5 |
| 3 | 1 |
| 4 | 6 |
- data.name:
'num_dropped' - data.index:
RangeIndex(start=0, stop=5, step=1) - data.values:
array([5, 7, 5, 1, 6])Khi không truyềnindex, Pandas sẽ tự tạo chỉ mục mặc định từ0đếnn-1.
Tạo Series với index tùy chỉnh: Ví dụ tạo một Series chứa tên các ngôn ngữ lập trình, gắn index theo ký tự viết tắt:
import pandas as pd
data = pd.Series(
['C++', 'Golang', 'Java', 'Python', 'Swift'],
index=list('CGJPS'),
name='Programming Language'
)Kết quả:
| Index | Value |
|---|---|
| C | C++ |
| G | Golang |
| J | Java |
| P | Python |
| S | Swift |
- data.name:
'Programming Language' - data.index:
Index(['C', 'G', 'J', 'P', 'S']) - data.values:
array(['C++', 'Golang', 'Java', 'Python', 'Swift'], dtype=object)Index tùy chỉnh giúp dữ liệu dễ đọc hơn và phù hợp với ngữ cảnh sử dụng.
Lấy giá trị trong Series (Get Rows)
Có nhiều cách để truy cập giá trị: 1. Truy cập bằng chỉ số (index vị trí)
print(data[0]) # 5
print(data[1]) # 7| Lệnh | Giá trị |
|---|---|
| data[0] | 5 |
| data[1] | 7 |
| data[2] | 5 |
| data[3] | 1 |
| data[4] | 6 |
2. Truy cập bằng **.loc[]** (theo nhãn index) |
print(data.loc[0]) # 5
print(data.loc[1]) # 7Cú pháp này dùng cho label-based indexing (theo tên index).
3. Lấy nhiều hàng liên tiếp
result = data.loc[2:3]Output:
| Index | Value |
|---|---|
| 2 | 5 |
| 3 | 1 |
| 4. Lấy nhiều hàng theo vị trí (slicing) |
result = data[2:3]Output:
| Index | Value |
|---|---|
| 2 | 5 |
| 5. Lọc theo điều kiện giá trị |
result = data[data.between(3, 6)]Output
| Index | Value |
|---|---|
| 0 | 5 |
| 2 | 5 |
| 4 | 6 |
result = data[data > 5]Output
| Index | Value |
|---|---|
| 1 | 7 |
| 4 | 6 |
- Câu hỏi gợi mở
-
Khi nào nên dùng
.loc[]và khi nào dùng slicing[start:end]?-
Dùng
**.loc[]**khi bạn muốn truy cập theo nhãn index (label-based indexing).Ví dụ: nếu index là
'A', 'B', 'C', thìdata.loc['A']sẽ lấy đúng giá trị có nhãn'A'..loc[start:end]bao gồm cảendkhi slicing. -
Dùng slicing
**[start:end]**khi bạn muốn truy cập theo vị trí (position-based indexing) hoặc khi index là số mặc định từ 0.Ví dụ:
data[0:3]sẽ lấy phần tử ở vị trí 0, 1, 2 (không bao gồm vị trí 3).
-
-
Làm thế nào để lấy đồng thời các giá trị có index cụ thể (ví dụ
[0, 2, 4])?Cách 1: Dùng
.loc[](theo nhãn index). Ví dụ:result = data.loc[[0, 2, 4]]Cách 2: Dùng
.iloc[](theo vị trí). Ví dụ:result = data.iloc[[0, 2, 4]]
-
Drop a row
Trong Pandas Series, có thể dùng phương thức .drop() để xóa một hoặc nhiều phần tử dựa trên index.
 Xóa 1 phần tử:
Xóa 1 phần tử:
data.drop('C')Xóa nhiều phần tử:
data.drop(['C', 'P'])Xóa phần tử theo chỉ số (position)
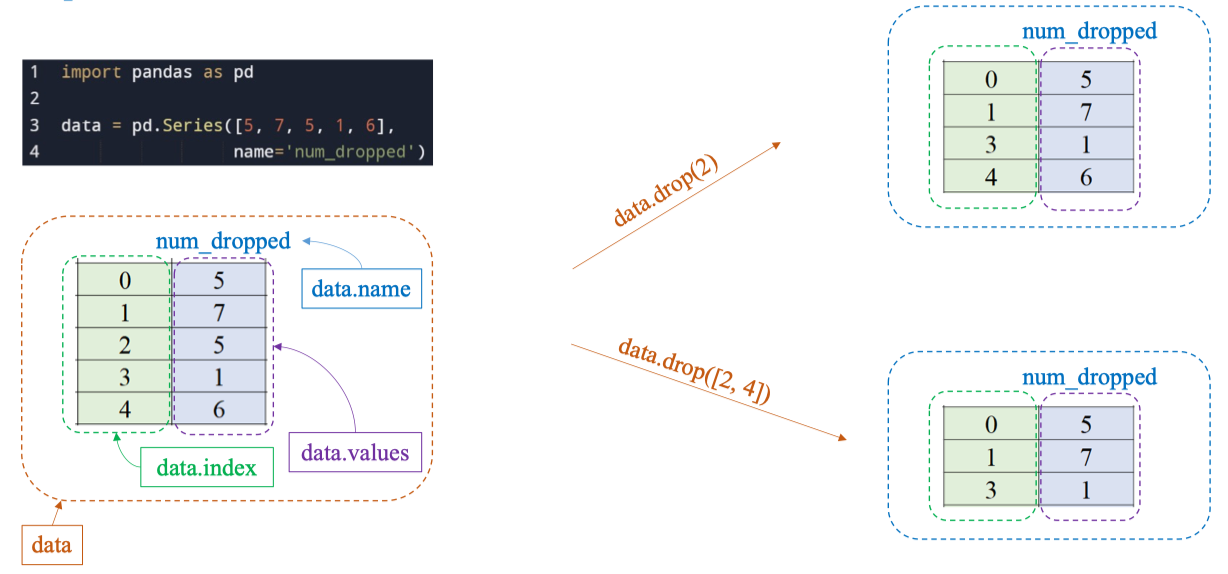 Xóa một phần tử:
Xóa một phần tử:
data.drop(2)Xóa nhiều phần tử:
data.drop([2, 4])Insert a row
Trong Pandas Series, có thể chèn một phần tử mới bằng cách gán giá trị cho một index mới.
Lấy lại data Programming Language
Gán giá trị 'Kotlin' vào index 'K':
data['K'] = 'Kotlin'Để sắp xếp các index theo thứ tự chữ cái:
data.sort_index(inplace=True)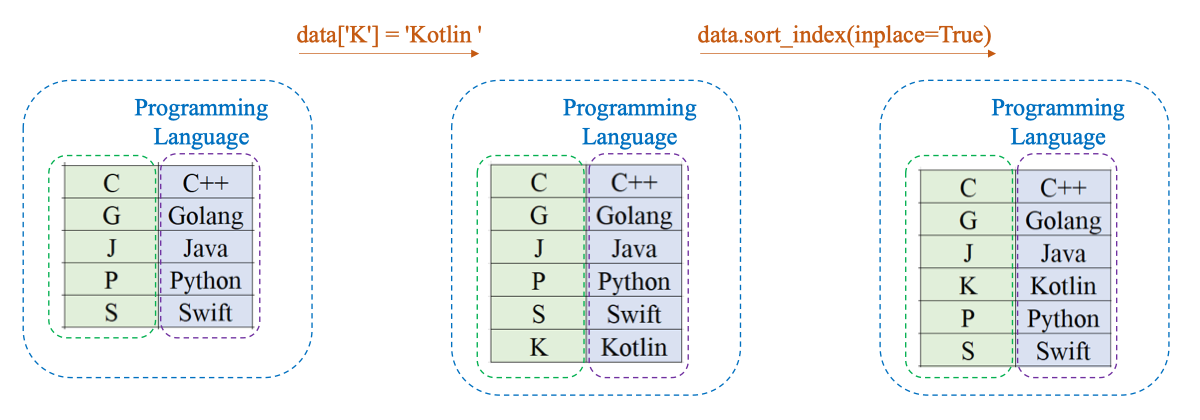
Hoặc đối với Series số nguyên ta có thể thực hiện như sau:
Giả sử muốn chèn giá trị 9 giữa index 2 và 3:
data[2.5] = 9Sau đó sắp xếp lại index
data.sort_index(inplace=True)Reset lại index để index liên tục từ 0
data.reset_index(drop=True, inplace=True)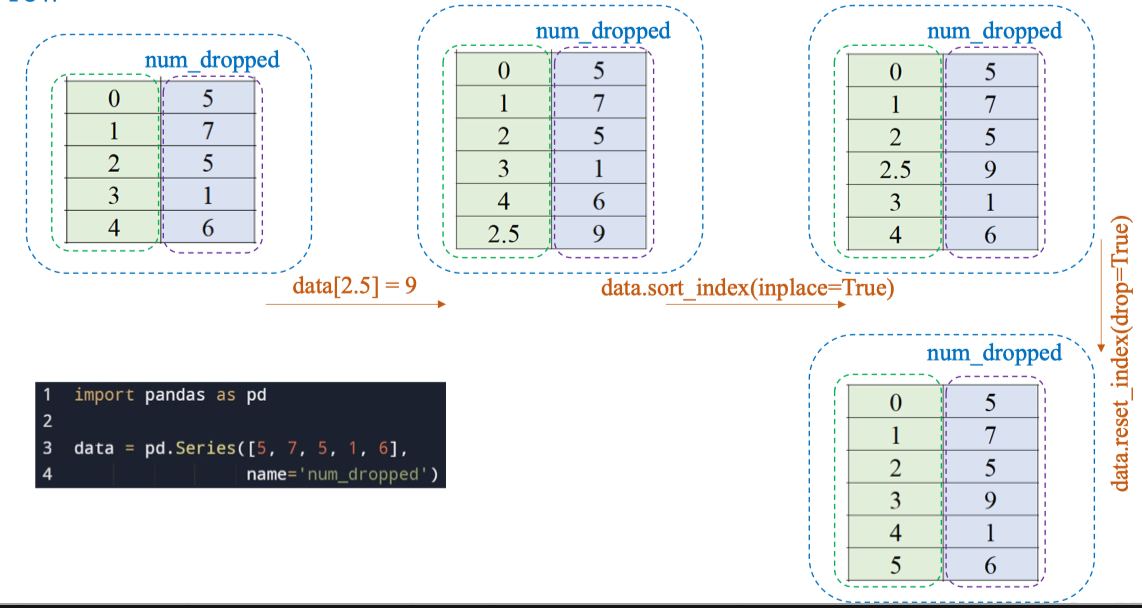
Common Pandas functions
Pandas cung cấp nhiều hàm tích hợp sẵn để tính toán nhanh trên Series.
| Hàm | Ý nghĩa | Kết quả |
|---|---|---|
data.min() | Giá trị nhỏ nhất | 1 |
data.max() | Giá trị lớn nhất | 7 |
data.sum() | Tổng các phần tử | 24 |
data.mean() | Giá trị trung bình | 4.8 |
data.std() | Độ lệch chuẩn | 2.28 |
data.var() | Phương sai | 5.2 |
data.idxmax() | Index của giá trị lớn nhất | 1 |
data.argmax() | Index của giá trị lớn nhất (giống idxmax) | 1 |
Đếm từ khóa 'Java' |
data.str.count('Java')| Index | Count |
|---|---|
| C | 0 |
| G | 0 |
| J | 1 |
| P | 0 |
| S | 0 |
Đếm ký tự 'a' |
data.str.count('a').str.count(pattern)trả về số lầnpatternxuất hiện trong mỗi phần tử.patterncó thể là chuỗi thông thường hoặc regex (biểu thức chính quy).- Có thể kết hợp với các hàm
.str.contains(),.str.replace(),.str.lower()để xử lý chuỗi linh hoạt hơn. |Index|Count| |---|---| |C|0| |G|1| |J|2| |P|0| |S|0|
Sử dụng .str.upper() để chuyển toàn bộ ký tự sang chữ hoa:
data.str.upper()| Index | Value |
|---|---|
| C | C++ |
| G | GOLANG |
| J | JAVA |
| P | PYTHON |
| S | SWIFT |
Sử dụng .replace() để thay "Java" bằng "C#": |
data.replace('Java', 'C#')| Index | Value |
|---|---|
| C | C++ |
| G | Golang |
| J | C# |
| P | Python |
| S | Swift |
- Câu hỏi gợi mở
- Sự khác nhau giữa
idxmax()vàargmax()trong Pandas là gì?idxmax(): Trả về Nhãn index (label) của phần tử có giá trị lớn nhất. Hoạt động theo index của Pandas, không phụ thuộc vị trí.argmax(): Trả về: Vị trí số nguyên (integer position) của phần tử lớn nhất. Dựa trên dữ liệu.valuescủa Series, không quan tâm label index.
- Sự khác nhau giữa
Addition Between Two Series
Tạo 2 Series ban đầu
import pandas as pd
center1 = pd.Series(
[12, 23, 31, 11, 9],
index=['C++', 'Golang', 'Java', 'Python', 'Swift'],
name='num_registered'
)
center2 = pd.Series(
[42, 18, 44, 49, 27],
index=['C++', 'Golang', 'Java', 'Python', 'Swift'],
name='num_registered'
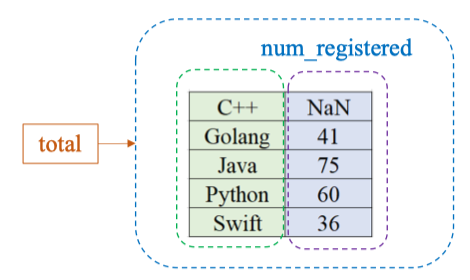
)Cộng hai Series
total = center1 + center2center1
| Index | Value |
|---|---|
| C++ | 12 |
| Golang | 23 |
| Java | 31 |
| Python | 11 |
| Swift | 9 |
| center2 | |
| Index | Value |
| --- | --- |
| C++ | 42 |
| Golang | 18 |
| Java | 44 |
| Python | 49 |
| Swift | 27 |
| total | |
| Index | Value |
| --- | --- |
| C++ | 54 |
| Golang | 41 |
| Java | 75 |
| Python | 60 |
| Swift | 36 |
-
Khi cộng hai Series, Pandas sẽ ghép theo index. Nếu một index có trong Series này nhưng không có trong Series kia → kết quả sẽ là
NaN.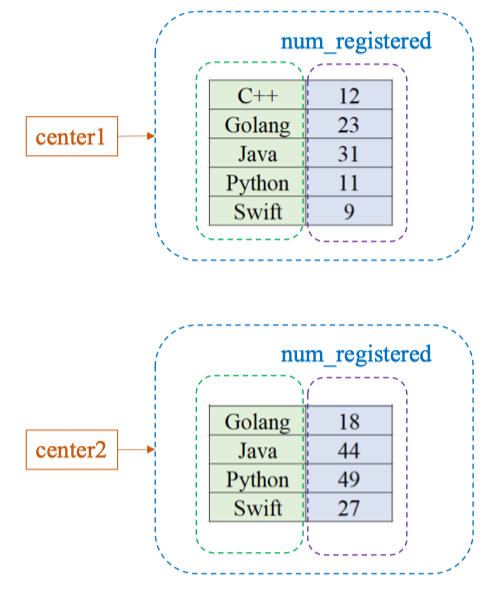
-
Có thể dùng
.add()với tham sốfill_valueđể thayNaNbằng giá trị mặc định:
Group Values
Dùng .groupby(level=0) để nhóm theo nhãn index:
data.groupby(level=0).sum()groupby(level=0) thường dùng khi Series có index trùng nhau và muốn tính toán theo từng nhóm index.
| Index | num_dropped |
|---|---|
| C++ | 5 |
| Golang | 3 |
| Java | 2 |
Nhóm dữ liệu dựa trên điều kiện data > 3:
data.groupby(data > 3).sum()Khi nhóm theo điều kiện, kết quả index sẽ là True/False hoặc giá trị phân loại.
Điều kiện (data > 3) | num_dropped |
|---|---|
| False | 6 |
| True | 4 |
Lấy nhóm cụ thể và tính tổng
data['C++'].sum() # 5
data['Golang'].sum() # 3
data['Java'].sum() # 2Ngoài .sum(), có thể dùng .mean(), .count(), .max(), v.v.
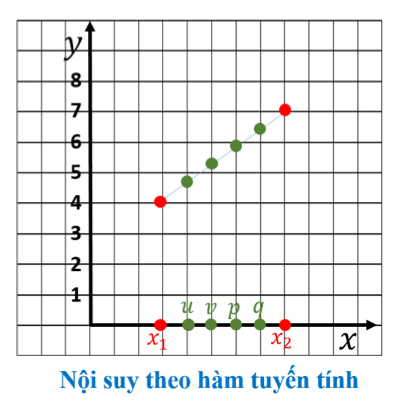
2. 1D interpolation
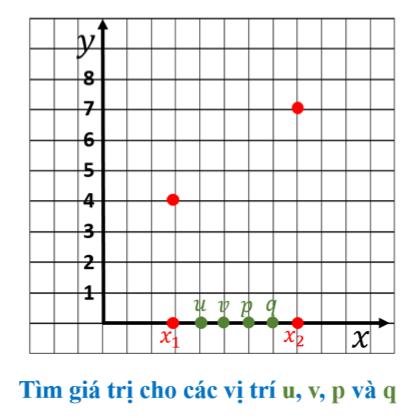
Giới thiệu bài toán nội suy: Cho hai điểm dữ liệu đã biết (x₁, y₁) và (x₂, y₂), cần tìm giá trị y tại các vị trí trung gian u, v, p, q trên trục x.
Phương pháp 1 – Nearest Neighbor (Láng giềng gần nhất)
Ý tưởng:
- Với mỗi điểm cần tìm (u, v, p, q), tính khoảng cách đến x₁ và x₂.
- Chọn giá trị y của điểm dữ liệu gần hơn. Đặc điểm:
- Dễ tính toán.
- Tạo ra đường nội suy bậc thang (step-like), không trơn tru.
- Không phù hợp khi yêu cầu độ mượt cao.
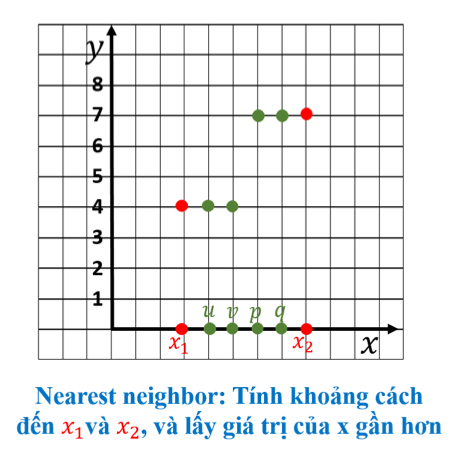 Công thức:
Công thức:
y(u) = y₁ nếu |u - x₁| < |u - x₂|, ngược lại y₂Phương pháp 2 – Linear Interpolation (Nội suy tuyến tính)
Ý tưởng:
- Nối thẳng hai điểm (x₁, y₁) và (x₂, y₂).
- Giá trị y tại các vị trí trung gian được xác định theo tỷ lệ khoảng cách. Đặc điểm:
- Kết quả mượt và liên tục.
- Dễ áp dụng cho dữ liệu biến đổi tuyến tính giữa các điểm.
 Cách làm:
Giả sử ta có hai điểm:
Cách làm:
Giả sử ta có hai điểm: -
Phương trình đường thẳng:
y = a x + b \tag{1}
Xác định hệ số góc . Từ hai điểm A và B:
a = \frac{y_2 - y_1}{x_2 - x_1} \tag{2}
Xác định tung độ gốc . Thay điểm A vào (1):
b = y_1 - \frac{y_2 - y_1}{x_2 - x_1} x_1 \tag{3}
Thay (2) và (3) vào (1):
y = \frac{y_2 - y_1}{x_2 - x_1} x + \left( y_1 - \frac{y_2 - y_1}{x_2 - x_1} x_1 \right) \tag{4}
Biến đổi thu gọn:
Gọi:
Từ đó ta có Công thức nội suy tuyến tính:

- Nearest neighbor nhanh và dễ nhưng không mượt, phù hợp khi dữ liệu là giá trị rời rạc, không cần tính liên tục.
- Linear interpolation phù hợp hơn khi dữ liệu thay đổi dần đều.
Ví dụ bài toán
Cho bảng giá trị với , trong đó một số giá trị bị thiếu (
None). Cần tìm giá trị tại dựa trên 2 điểm lân cận: -
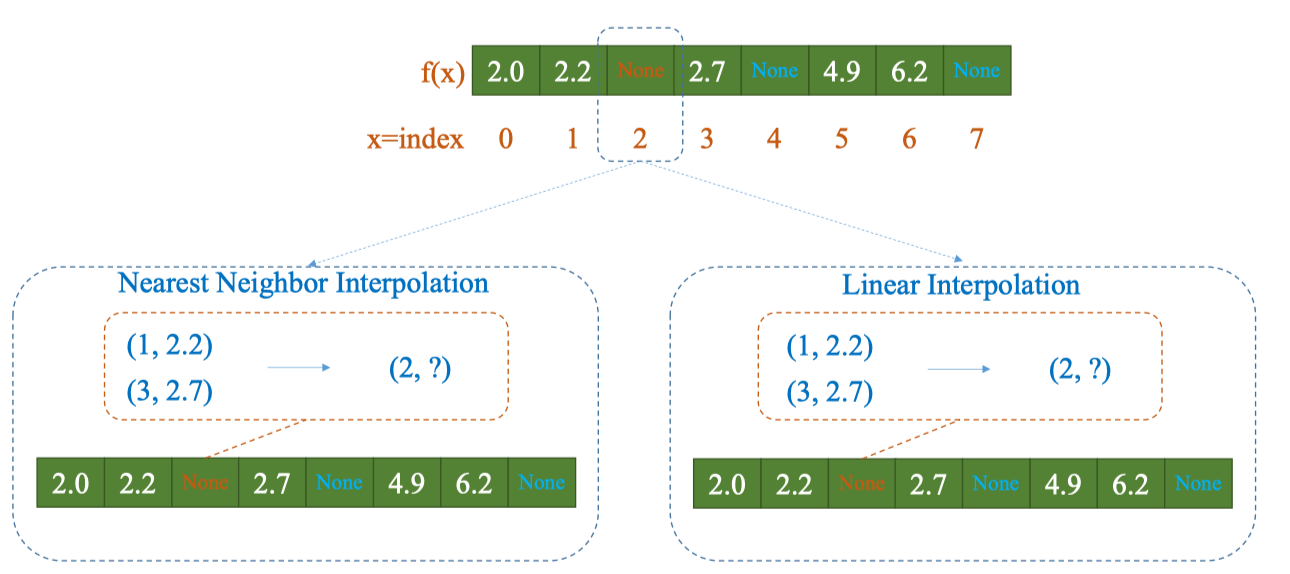 1. Nearest Neighbor Interpolation
Khoảng cách từ đến:
1. Nearest Neighbor Interpolation
Khoảng cách từ đến: - : khoảng cách = 1
- : khoảng cách = 1 Trường hợp bằng nhau, thường chọn giá trị bên trái (hoặc theo quy tắc định sẵn). Kết quả:
2. Linear Interpolation Công thức: Thay:x_1 = 1, \quad y_1 = 2.2$$x_2 = 3, \quad y_2 = 2.7$$x = 2 Tính:f(2) = 2.2 + \frac{2 - 1}{3 - 1} \cdot (2.7 - 2.2)$$f(2) = 2.2 + 0.5 \cdot 0.5 = 2.45 Kết quả:
Missing Values trong Pandas Series
Tạo một Series có giá trị thiếu
import pandas as pd
import numpy as np
data = pd.Series(
[1, 6, 3, 8, np.nan, 7, np.nan, 2],
name='num_dropped'
)| Index | Value |
|---|---|
| 0 | 1 |
| 1 | 6 |
| 2 | 3 |
| 3 | 8 |
| 4 | NaN |
| 5 | 7 |
| 6 | NaN |
| 7 | 2 |
Khi ta dùng các hàm thống kê của Pandas thì nó mặc định bỏ qua các giá trị NaN khi tính toán: |
data.min() # 1
data.max() # 8
data.sum() # 27
data.mean() # 4.5
data.std() # 2.88
data.idxmax() # 3
data.argmax() # 3Xóa giá trị thiếu:
data.dropna()| Index | Value |
|---|---|
| 0 | 1 |
| 1 | 6 |
| 2 | 3 |
| 3 | 8 |
| 5 | 7 |
| 7 | 2 |
| Điền giá trị cố định: |
data.fillna(1.0)| Index | Value |
|---|---|
| 0 | 1.0 |
| 1 | 6.0 |
| 2 | 3.0 |
| 3 | 8.0 |
| 4 | 1.0 |
| 5 | 7.0 |
| 6 | 1.0 |
| 7 | 2.0 |
| Nội suy giá trị: |
data.interpolate()| Index | Value |
|---|---|
| 0 | 1.0 |
| 1 | 6.0 |
| 2 | 3.0 |
| 3 | 8.0 |
| 4 | 7.5 |
| 5 | 7.0 |
| 6 | 4.5 |
| 7 | 2.0 |
3. Case study: Temperature forecasting
Dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('weatherHistory2D.csv')
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 96453 entries, 0 to 96452
Data columns (total 2 columns):Column Non-Null Count Dtype
0 Formatted Date 96453 non-null object
1 Temperature (C) 96453 non-null float64
dtypes: float64(1), object(1)
memory usage: 1.5+ MB
- Cột
**Date**: Ngày quan sát. - Cột
**Temperature (°C)**: Nhiệt độ trung bình ngày (theo °C). - Dữ liệu gồm nhiều năm, ghi nhận nhiệt độ theo ngày.
- Data: Dữ liệu mô tả thực tế.
- Meta data: Dữ liệu để mô tả data.
Fill missing data
Điền bằng giá trị trung bình (**fillna(mean)**)
mean = df_train['Temperature (C)'].mean()
df_train = df_train.fillna(mean)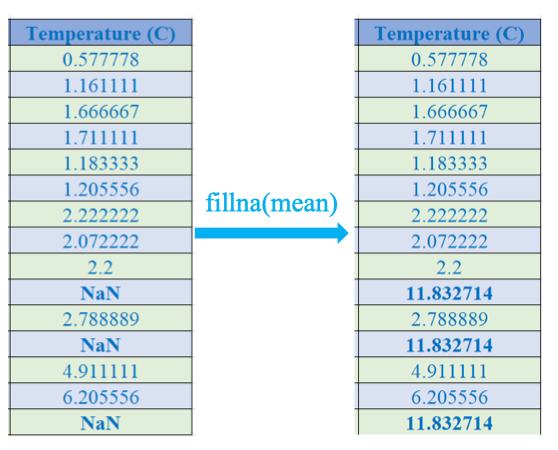 Nội suy (
Nội suy (**interpolate()**)
df_train = df_train.interpolate()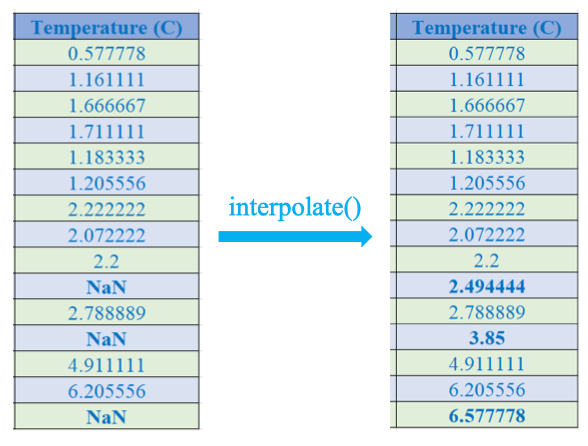
4. Noise Reduction
Khi làm việc với dữ liệu chuỗi thời gian (time series), đặc biệt là dữ liệu nhiệt độ, tốc độ gió, độ ẩm… thường tồn tại nhiễu – các dao động ngẫu nhiên không mang thông tin xu hướng. Giảm nhiễu (Noise Reduction) giúp:
- Làm mượt đường biểu diễn.
- Dễ quan sát xu hướng dài hạn.
- Giảm tác động của biến động đột ngột (outlier) tới mô hình học máy.
Moving Average – Trung bình trượt
SMA (Simple Moving Average):
- SMA (Simple Moving Average): Lấy trung bình của k giá trị gần nhất.
EMA (Exponential Moving Average):
- Gán trọng số lớn hơn cho các giá trị mới hơn.
- Ít bị trễ (lag) so với SMA. Ví dụ:
data_sma = data.rolling(window=5).mean()window=5: lấy trung bình của 5 điểm liên tiếp.- Kết quả: đường biểu diễn mượt hơn, giảm các dao động nhỏ.
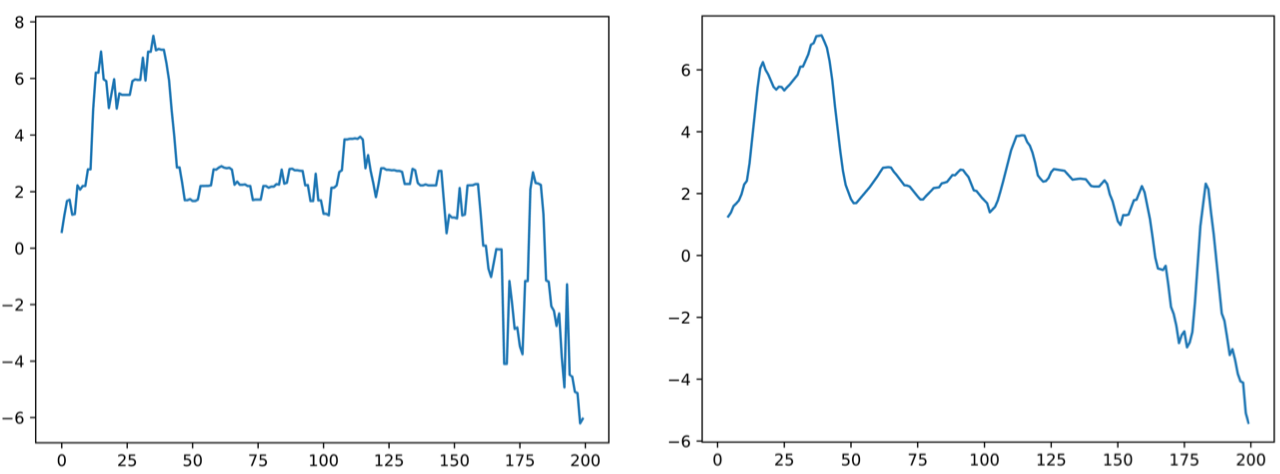
II. DataFrame
1. Simple functions
Create a dataframe
Đọc dữ liệu advertising_simple.csv :
import pandas as pd
df = pd.read_csv('advertising_simple.csv')
print(df)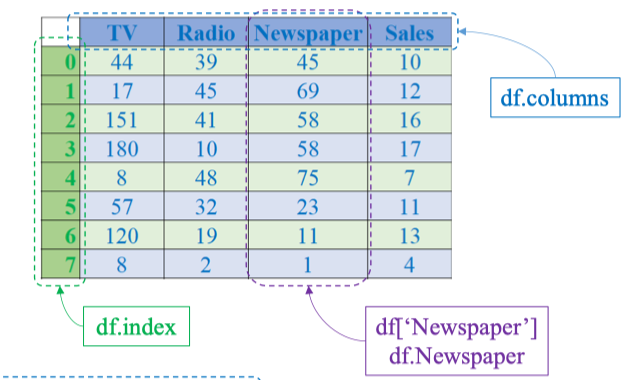 Các thành phần quan trọng của DataFrame
Các thành phần quan trọng của DataFrame
| Thành phần | Cách truy cập | Mô tả |
|---|---|---|
**df.index** | df.index | Danh sách chỉ số (số thứ tự) của các hàng. |
**df.columns** | df.columns | Danh sách tên các cột. |
| Cột cụ thể | df['Newspaper'] hoặc df.Newspaper | Truy xuất dữ liệu của một cột. |
| Đảo cột thành dòng (chuyển vị dataframe): |
df_t = df.T
print(df)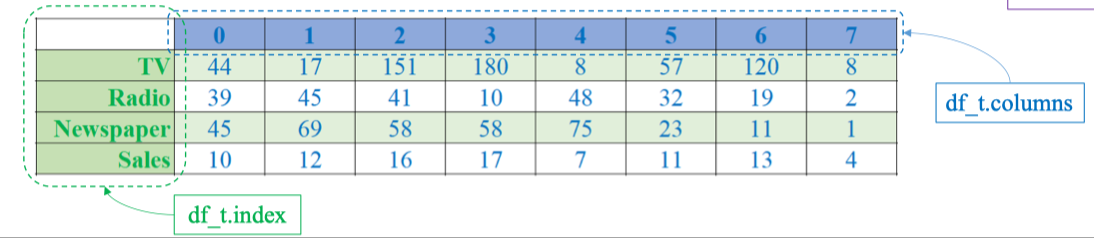
Sorting
Sắp xếp theo một cột
import pandas as pd
df = pd.read_csv('advertising_simple.csv')
df.sort_values('Sales')-
**sort_values('Sales')**: sắp xếp DataFrame tăng dần dựa trên giá trị trong cộtSales. -
Mặc định ascending=True → tăng dần.
Nếu muốn giảm dần:
df.sort_values('Sales', ascending=False).
📌 Kết quả: bảng được sắp từ giá trị Sales nhỏ nhất đến lớn nhất.
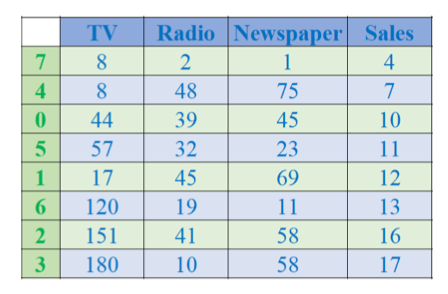
Sắp xếp theo nhiều cột
df.sort_values(['Newspaper', 'Sales'])- Danh sách cột: Pandas sẽ sắp xếp theo thứ tự ưu tiên trong list.
- Bước 1: sắp theo
Newspapertăng dần. - Bước 2: nếu giá trị
Newspaperbằng nhau → sắp tiếp theoSales. 📌 Kết quả: ưu tiênNewspaper, nếu trùng thì xétSales. Note: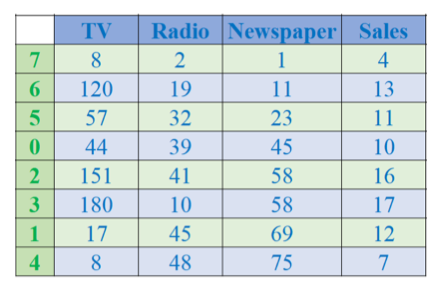
- Không thay đổi dữ liệu gốc trừ khi dùng
inplace=True. - Có thể kết hợp
ascending=[True, False]để mỗi cột có thứ tự riêng.
Add a column
Thêm một cột mới vào DataFrame
import pandas as pd
df = pd.read_csv('advertising_simple.csv')
df['ID'] = list(range(2, 10))**df['ID']**: tạo cột mới tên làID.**list(range(2, 10))**: sinh dãy số từ 2 → 9 để gán vào cộtID.- Lúc này
df.columnssẽ có thêmIDở cuối.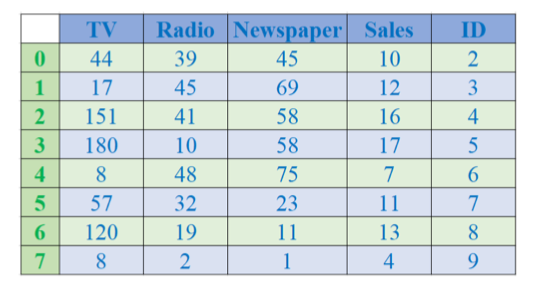 Đặt một cột làm index
Đặt một cột làm index
df = df.set_index('ID')**set_index('ID')**: đặt cộtIDlàm chỉ số dòng (index) mới.- Nếu không gán lại hoặc dùng
inplace=Truethì DataFrame gốc không thay đổi. - Index mới thay thế df.index, và cột
IDbiến mất khỏidf.columns.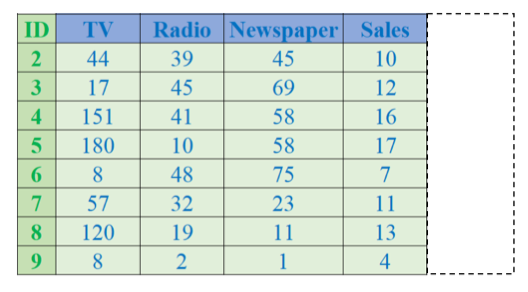 📌 Kết quả:
📌 Kết quả: - Index hiển thị các giá trị từ cột
ID. - Cột
IDkhông còn nằm trong phần dữ liệu chính nữa.
Get values
df.columns→ Lấy danh sách tên cột.df.index→ Lấy danh sách index (nhãn hàng).df['Newspaper']→ Lấy dữ liệu của cột Newspaper. Truy cập dữ liệu theo cột:
df.Radio
df['Radio']→ Trả về Series của cột Radio.
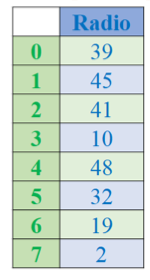
Tuy nhiên nên dùng
df[’Radio’]: _như là chỉ số (dictionary-style indexing)_→ vì tránh được việc tên cột có ký tự đặc biệt hoặc khoảng trắng.
Ngược lại:df.Radionhư là thuộc tính (attribute-style access).
Duyệt các dòng của dataframe
df = pd.read_excel(folder + '/Data/Data.xls', sheet_name = 'Insurance')
df = df.head()
for idx, row in df.iterrows():
print(f'* Dòng {idx}:')
print(row, '\n')==Quy tắc: Dòng trước cột sau==
Bởi vì df của chúng ta có cấu trúc là:
* Dòng 0:
age 19
sex female
bmi 27.9
children 0
smoker yes
region southwest
charges 16884.924
Name: 0, dtype: object
* Dòng 1:
age 18
sex male
bmi 33.77
children 1
smoker no
region southeast
charges 1725.5523
Name: 1, dtype: object
* Dòng 2:
age 28
sex male
bmi 33.0
children 3
...
region northwest
charges 3866.8552
Name: 4, dtype: object 2. Example 1: Weather dataset
Quay lại với dữ liệu nhiệt độ ở phần 1 đã giới thiệu.
-
Dữ liệu thời gian (
datetime) được giữ nguyên dạng chuỗi ‘2006-12-01 00’→ Mô hình Machine Learning không thể hiểu ý nghĩa trực tiếp của chuỗi thời gian này (chuỗi ký tự không có quan hệ số học rõ ràng).
-
datetimeđược tách thành nhiều feature số học:year = 2006month = 12day = 1hour = 0
→ Mô hình dễ học hơn, vì các giá trị này là dữ liệu dạng số và thể hiện trực tiếp các đặc trưng thời gian.
Datatime
Cấu trúc datetime
year-month-day hour:minute:second.millisecondTrong Pandas, có thể truy cập từng thành phần qua:
datetime = pd.to_datetime('2006-12-01 00:00:00.000')
print(datetime) \#2006-12-01 00:00:00
print(datetime.year) #2006
print(datetime.month) #12
print(datetime.day) #1
print(datetime.hour) #0Chuyển đổi cột ngày giờ sang kiểu datetime
- Cột
'Formatted Date'được chuyển sang kiểu datetime64[ns, UTC] để dễ thao tác với thời gian. utc=Trueđảm bảo dữ liệu được chuẩn hóa theo múi giờ UTC. Tách các thành phần thời gian:.dt.year→ Lấy năm..dt.month→ Lấy tháng..dt.day→ Lấy ngày..dt.hour→ Lấy giờ.- Giúp phân tích dữ liệu theo từng thành phần thời gian hoặc xây dựng mô hình dự báo theo các yếu tố này.
Sau đó xóa cột gốc
Formatted Date
df = pd.read_csv('weatherHistory2D.csv')
df['Formatted Date'] = pd.to_datetime(df['Formatted Date'],
utc=True)
df['year'] = df['Formatted Date'].dt.year
df['month'] = df['Formatted Date'].dt.month
df['day'] = df['Formatted Date'].dt.day
df['hour'] = df['Formatted Date'].dt.hour
df = df.drop('Formatted Date', axis=1)
df| Temperature (C) | year | month | day | hour | |
|---|---|---|---|---|---|
| 0 | 0.577778 | 2005 | 12 | 31 | 23 |
| 1 | 1.161111 | 2006 | 1 | 1 | 0 |
| 2 | 1.666667 | 2006 | 1 | 1 | 1 |
| 3 | 1.711111 | 2006 | 1 | 1 | 2 |
| 4 | 1.183333 | 2006 | 1 | 1 | 3 |
| … | … | … | … | … | … |
| 96448 | 0.488889 | 2016 | 12 | 31 | 18 |
| 96449 | 0.072222 | 2016 | 12 | 31 | 19 |
| 96450 | -0.233333 | 2016 | 12 | 31 | 20 |
| 96451 | -0.472222 | 2016 | 12 | 31 | 21 |
| 96452 | -0.677778 | 2016 | 12 | 31 | 22 |
| 96453 rows × 5 columns |
3. Example 2: Tweets dataset
Mô tả dữ liệu
Dataset Tweets dùng để phân loại tweet thành disaster hoặc non-disaster.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7613 entries, 0 to 7612
Data columns (total 5 columns):Column Non-Null Count Dtype
0 id 7613 non-null int64
1 keyword 7552 non-null object
2 location 5080 non-null object
3 text 7613 non-null object
4 target 7613 non-null int64
dtypes: int64(2), object(3)
memory usage: 297.5+ KB
- Số lượng mẫu huấn luyện (Training samples):
7613 - Số tweet disaster:
4342(target = 1) - Số tweet non-disaster:
3271(target = 0) Các trường dữ liệu:
|Cột|Ý nghĩa|
|---|---|
|id|Mã định danh duy nhất của tweet|
|keyword|Từ khóa liên quan (nếu có)|
|location|Địa điểm được nhắc đến trong tweet|
|text|Nội dung tweet|
|target|Nhãn phân loại:
Các trường dữ liệu:
|Cột|Ý nghĩa|
|---|---|
|id|Mã định danh duy nhất của tweet|
|keyword|Từ khóa liên quan (nếu có)|
|location|Địa điểm được nhắc đến trong tweet|
|text|Nội dung tweet|
|target|Nhãn phân loại: 1= disaster tweet,0= non-disaster tweet|
Delete a row
df.drop(label, axis)**axis=0**→ xóa dòng (row) theo index**axis=1**→ xóa cột (column) theo tên cột Xóa 1 dòng
df.drop(1, axis=0) → Xóa dòng có index = 1.
Xóa 2 dòng
df.drop([1, 2, 3], axis=0)→ Xóa các dòng có index = 1, 2, 3.
Delete a column
Xóa 1 cột
df.drop('Radio', axis=1)→ Xóa cột Radio. Xóa nhiều cột
df.drop(['Radio', 'Sales'], axis=1)→ Xóa cột Radio và Sales. Ví dụ: Trong xử lý dữ liệu NLP, thường id, keyword, và location không cần thiết cho bước tiền xử lý văn bản, nên ta sẽ xóa chúng.
import pandas as pd
# Đọc dữ liệu từ file CSV
df = pd.read_csv("path_to_cvs_file")
# Xóa 3 cột: id, keyword, location
df.drop(["id", "keyword", "location"], axis=1, inplace=True)