Table of Content
Important
Tham khảo
I. Introduction to Data Visualization
Hệ thống hỗ trợ ra quyết định
Các loại quyết định:
- Có cấu trúc (structured decisions):
- Bán cấu trúc (semi-structured decisions):
- Không cấu trúc (unstructured decisions): Có thể nói mục tiêu của việc Visualization dữ liệu là để hỗ trợ cho người đọc ra quyết định.
Những yếu tố để đưa ra quyết định?
- Dữ liệu
- Điều kiện tại sao lại phải ra quyết định
Quy trình đưa ra quyết định:
- Xác định vấn đề (Problem definition)
- Information collection
- Developing alternatives to solving the problem
- Evidence consideration
- Choice of alternatives
- Decision implementation
- Results evaluation
Chất lượng của DSS:
-
Độ tin cậy
-
Mô hình giao tiếp
-
Khả năng diễn giải
-
Câu hỏi gợi mở:
- Tại sao ta lại cần phân tích dữ liệu?
- Phân tích = mô tả
- Nhưng trong DS thì bao gồm: mô tả, dự đoán, đưa ra quyết định (ứng phó).
- Sự khác nhau giữa dự đoán và dự báo?
- Dự đoán:
- Dự báo:
- Những yếu tố để đưa ra quyết định?
- Dữ liệu
- Điều kiện tại sao lại phải ra quyết định
- Tại sao để đo chất lượng DSS thì dùng những tiêu chí trên?
- Bởi vì không thể xác định được chính xác.
- Mô hình giao tiếp
- Tại sao ta lại cần phân tích dữ liệu?
Business Intelligence
BI 1.0: chú trọng dữ liệu, hỗ trợ quy trình ra quyết định
- data, information
- models, methods
- decision making
Choose the Right Chart Type
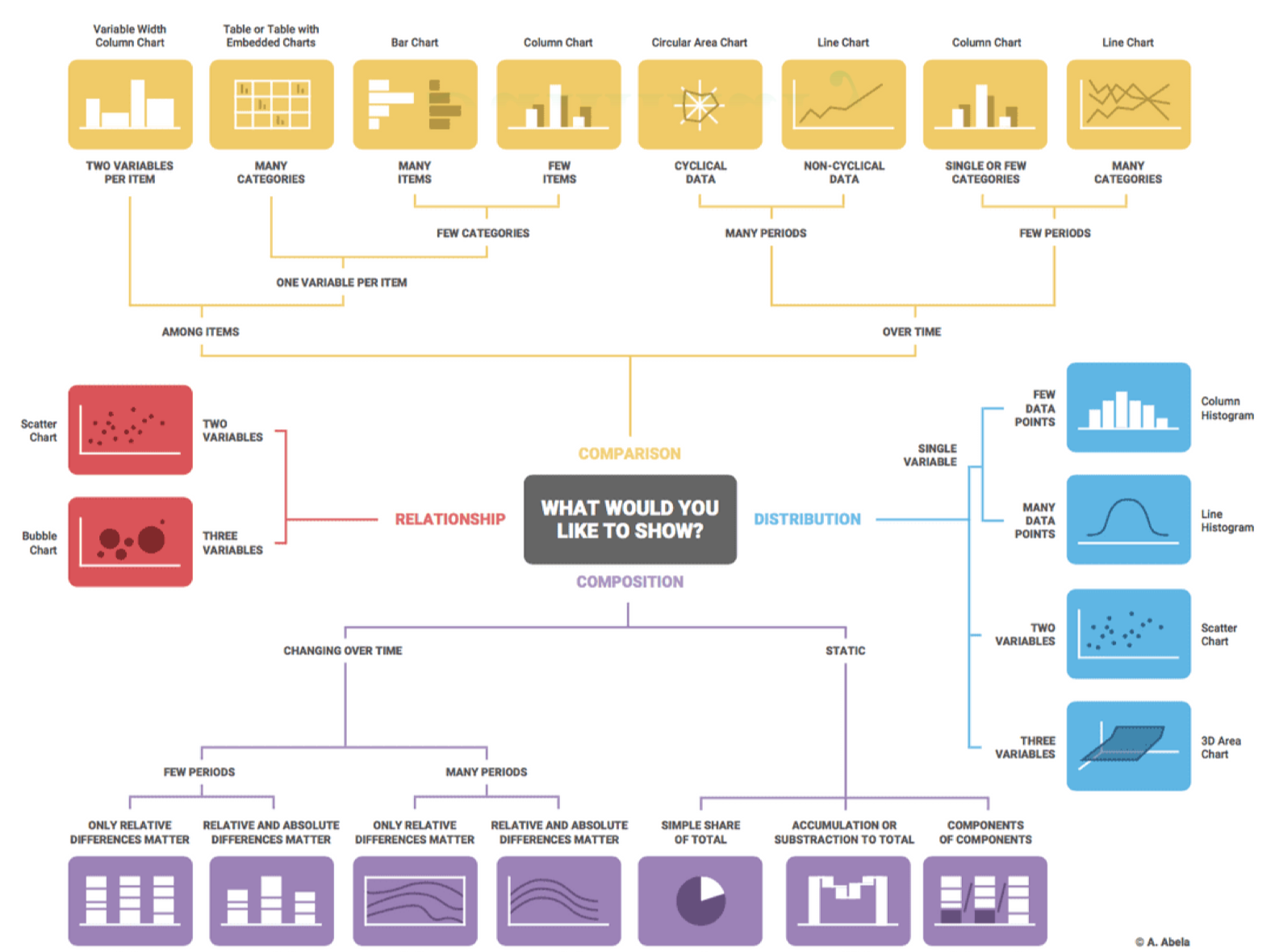 Step 1: Determine the Type of Data
Step 1: Determine the Type of Data
Step 2: Identify the Relationship Between Variables
Step 3: Determine the Purpose of Visualization
Step 4: Identify the Audience
Step 5: Select the Appropriate Chart Type
Step 1 – Determine the Type of Data
Dữ liệu có thể được phân thành 4 loại chính:
- Quantitative data: Dữ liệu dạng số, thể hiện giá trị đo lường hoặc tính toán (ví dụ: nhiệt độ, doanh thu, sản lượng).
- Categorical data: Dữ liệu phân loại, không phải số, không có thứ tự, thường là tên nhóm hoặc nhãn (ví dụ: loại sản phẩm, khu vực, giới tính).
- Temporal data: Dữ liệu gắn với yếu tố thời gian, cho phép phân tích xu hướng hoặc chu kỳ (ví dụ: ngày, tháng, năm, timestamp).
- Spatial data: Dữ liệu gắn với vị trí địa lý hoặc không gian (ví dụ: tọa độ GPS, địa chỉ, khu vực địa lý).
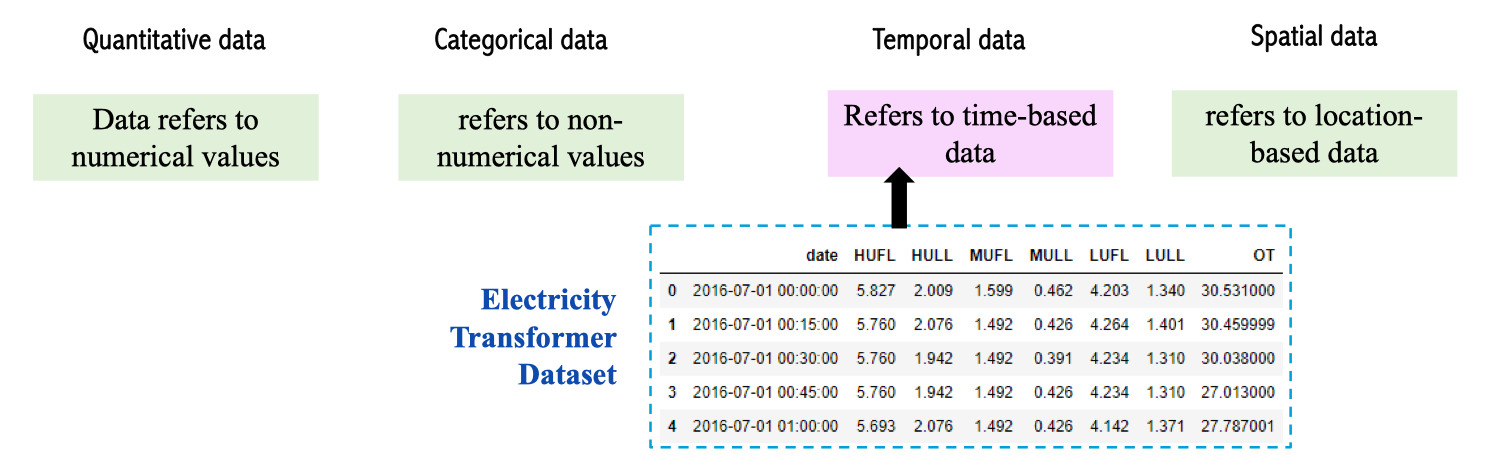 Trong Electricity Transformer Dataset, ví dụ về temporal data là cột date, còn các cột như HUFL, HULL, MUFL, MULL, LUFL, LULL, OT là quantitative data.
💡 Tip: Khi load dữ liệu, hãy gắn nhãn kiểu dữ liệu cho từng cột ngay từ đầu để hỗ trợ việc chọn biểu đồ sau này.
Trong Electricity Transformer Dataset, ví dụ về temporal data là cột date, còn các cột như HUFL, HULL, MUFL, MULL, LUFL, LULL, OT là quantitative data.
💡 Tip: Khi load dữ liệu, hãy gắn nhãn kiểu dữ liệu cho từng cột ngay từ đầu để hỗ trợ việc chọn biểu đồ sau này. - Câu hỏi gợi mở
-
Có các cách nào khác để phân loại dữ liệu không, tại sao người ta lại phân loại như vậy?
Important
- Dữ liệu định danh (Categorical data,…):
- Dữ liệu định tính (Ordinal, quanlitative data): Có quan hệ thứ tự
- Dữ liệu định lượng (quantitative data):
- Rời rạc: Là dữ liệu đếm được. Ví dụ: Số học sinh trong phòng học, số hạt electron trong phân tử.
- Liên tục: Là dữ liệu đo được. Ví dụ: Chiều cao, vận tốc
-
Interval scaled: Sự lấy tỷ lệ không có ý nghĩa, chỉ là cột mốc và không có ý nghĩa. Ví dụ: Nhiệt độ, thang đo likert,…
→ Khi này khi ta tịnh tiến đơn vị (từ Kevin → độ C) thì bài toán vẫn giữ lại bản chất.
→ Vì vậy thang đo này khi so sánh chỉ có ý nghĩa với hiệu số. Ví dụ:
-
Ratio scaled: Có ý nghĩa khi ta lấy tỷ lệ, số có ý nghĩa .Ví dụ: Chiều cao, cân nặng. Việc một vật cao 2m sẽ gấp đôi 1m.
→ Lúc này ta không thể tịnh tiến đơn vị mà vẫn đảm bảo cho bài toán giữ lại được ý nghĩa, đơn vị chỉ có thể thay đổi theo phép nhân chia.
→ Ở đây cả hiệu số và thương số đều có ý nghĩa.
-
-
Các xác định giá trị của một đại lượng là liên tục hay rời rạc?
→ Dùng hàm Cadlag
-
Step 2 – Identify the Relationship Between Variables
Khi trực quan hóa dữ liệu, cần xác định mối quan hệ giữa các biến để chọn loại biểu đồ phù hợp. Có ba dạng quan hệ chính:
-
Comparison (So sánh): Hiển thị sự khác biệt giữa hai hoặc nhiều điểm dữ liệu.
Ví dụ: So sánh giá trị HUFL và HULL theo từng khoảng thời gian → Bar chart hoặc Column chart.
-
Distribution (Phân bố): Thể hiện cách dữ liệu được trải rộng, có tập trung hay không, và có ngoại lệ hay không.
Ví dụ: Phân bố giá trị OT trong toàn bộ tập dữ liệu → Histogram hoặc Box plot.
-
Relationship (Quan hệ): Thể hiện mối liên kết giữa hai hoặc nhiều biến.
Ví dụ: Mối quan hệ giữa HUFL và OT → Scatter plot hoặc Bubble chart.
💡 Tip: Trước khi chọn biểu đồ, hãy trả lời câu hỏi: “Mình muốn người xem so sánh, xem phân bố, hay tìm quan hệ?“.
Step 3 – Determine the Purpose of Visualization
Mục tiêu của trực quan hóa dữ liệu là truyền đạt thông điệp một cách nhanh chóng và dễ hiểu. Trước khi chọn biểu đồ, hãy xác định rõ bạn muốn thể hiện điều gì:
-
Xu hướng theo thời gian (Trend over time): Dùng Line chart hoặc Area chart để hiển thị sự thay đổi của biến qua các mốc thời gian.
Ví dụ: Theo dõi OT (Oil Temperature) trong 24 giờ để thấy biến động nhiệt độ.
-
So sánh (Comparison): Dùng Bar chart hoặc Column chart để so sánh giá trị giữa các nhóm hoặc mốc thời gian cụ thể.
Ví dụ: So sánh giá trị trung bình HUFL, HULL, MUFL trong một ngày.
-
Phân bố (Distribution): Dùng Histogram hoặc Box plot để hiển thị cách dữ liệu phân tán, nhận biết xu hướng lệch hoặc ngoại lệ.
Ví dụ: Phân tích phân bố OT để phát hiện giá trị bất thường.
💡 Tip: Luôn kiểm tra xem biểu đồ của bạn có thể giúp người xem hiểu ý chính trong 5 giây hay không.
Step 4 – Identify the Audience
Khi thiết kế biểu đồ, cần xem xét đối tượng người xem để quyết định độ phức tạp và cách trình bày:
-
Audience là chuyên gia: Có khả năng đọc hiểu biểu đồ phức tạp, như heatmap, pair plot, hoặc biểu đồ đa biến.
→ Ví dụ: Heatmap thể hiện tương quan giữa HUFL, HULL, MUFL, MULL, LUFL, LULL và OT trong Electricity Transformer Dataset.
-
Audience phổ thông hoặc ít kinh nghiệm với trực quan hóa: Nên dùng biểu đồ đơn giản, dễ đọc như pie chart, bar chart, hoặc column chart.
→ Ví dụ: Pie chart hiển thị tỷ lệ trung bình của các loại tải trong dataset.
💡 Tip: Luôn thử nghiệm một phiên bản đơn giản trước, sau đó mới nâng độ phức tạp nếu audience có thể tiếp nhận.
Step 5 – Select the Appropriate Chart Type
Không có loại biểu đồ nào phù hợp cho mọi tình huống (one-size-fits-all). Tùy theo thông điệp, bản chất dữ liệu và đối tượng khán giả, ta có thể:
- Chọn 1 biểu đồ duy nhất nếu dữ liệu đơn giản, thông điệp rõ ràng.
- Kết hợp nhiều biểu đồ (multiple chart types) để truyền đạt toàn diện hơn, ví dụ: một Line chart cho xu hướng + một Box plot cho phân bố. 💡 Tip: Luôn thử nghiệm với nhiều loại biểu đồ khác nhau để tìm phương án trực quan hóa hiệu quả nhất.
II. Case study: ETTH dataset
Mô tả dữ liệu
Electricity Transformer Dataset
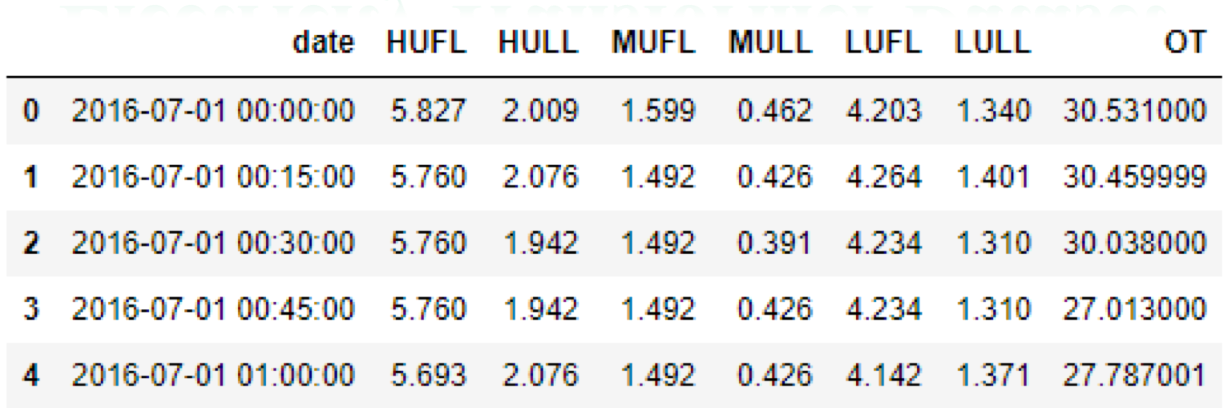
| Field | Description |
|---|---|
| date | Ngày và thời gian ghi nhận dữ liệu (temporal data). |
| HUFL | High Useful Load – tải cao hữu ích (quantitative). |
| HULL | High Useless Load – tải cao không hữu ích (quantitative). |
| MUFL | Middle Useful Load – tải trung bình hữu ích (quantitative). |
| MULL | Middle Useless Load – tải trung bình không hữu ích (quantitative). |
| LUFL | Low Useful Load – tải thấp hữu ích (quantitative). |
| LULL | Low Useless Load – tải thấp không hữu ích (quantitative). |
| OT | Oil Temperature – nhiệt độ dầu (biến mục tiêu cần dự đoán). |
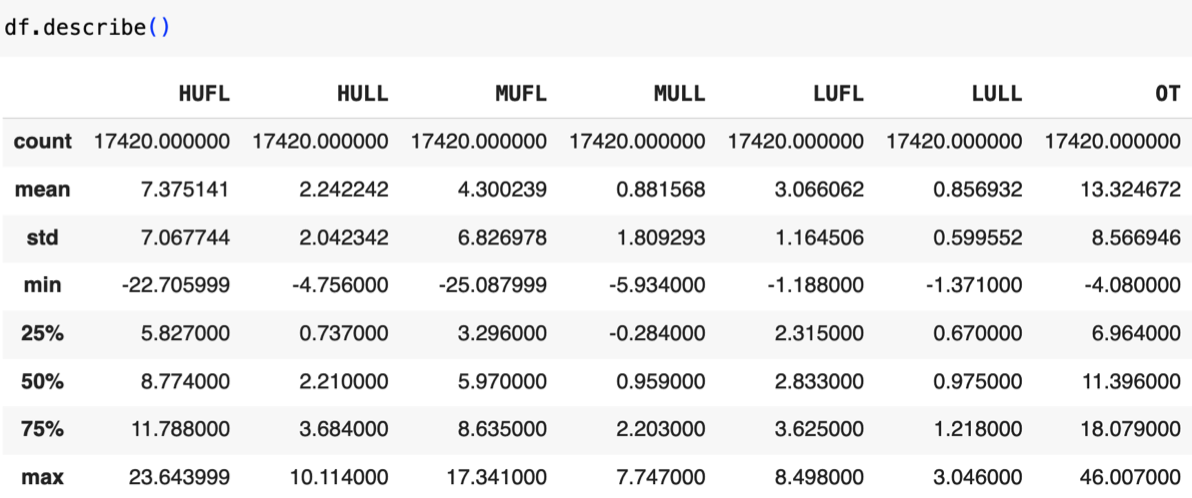
Sau khi load ETTh Dataset, bước đầu tiên là khám phá dữ liệu bằng df.describe() để thu được các thống kê cơ bản: |
-
count: Số lượng giá trị không rỗng (non-empty values).
-
mean: Giá trị trung bình.
-
std: Độ lệch chuẩn, thể hiện độ phân tán của dữ liệu.
-
min / max: Giá trị nhỏ nhất và lớn nhất.
-
25%, 50%, 75%: Các percentile (Q1, median, Q3) dùng trong phân tích phân bố và xác định outlier.
Mục tiêu phân tích:
- Xác định thời điểm OT cao nhất → Line chart (để quan sát xu hướng theo thời gian) + đánh dấu giá trị cực đại.
- Hiểu tương quan giữa các biến → Heatmap hoặc Pair plot để thấy mức độ liên quan giữa HUFL, HULL, MUFL, MULL, LUFL, LULL, OT.
- Phân tích phân bố dữ liệu → Histogram hoặc Box plot để nhận diện độ lệch, mật độ, và ngoại lệ.
- Xác định tỷ lệ dữ liệu lỗi → Bar chart hoặc Pie chart nếu có nhãn phân loại dữ liệu lỗi.
- Phân bố tải trung bình theo từng loại (HUFL, HULL, MUFL, MULL, LUFL, LULL) → Pie chart hoặc Donut chart để hiển thị tỷ lệ từng loại tải.
Dựa trên sơ đồ quyết định “Which chart?”, ta có thể ánh xạ từng mục tiêu phân tích sang loại biểu đồ phù hợp:
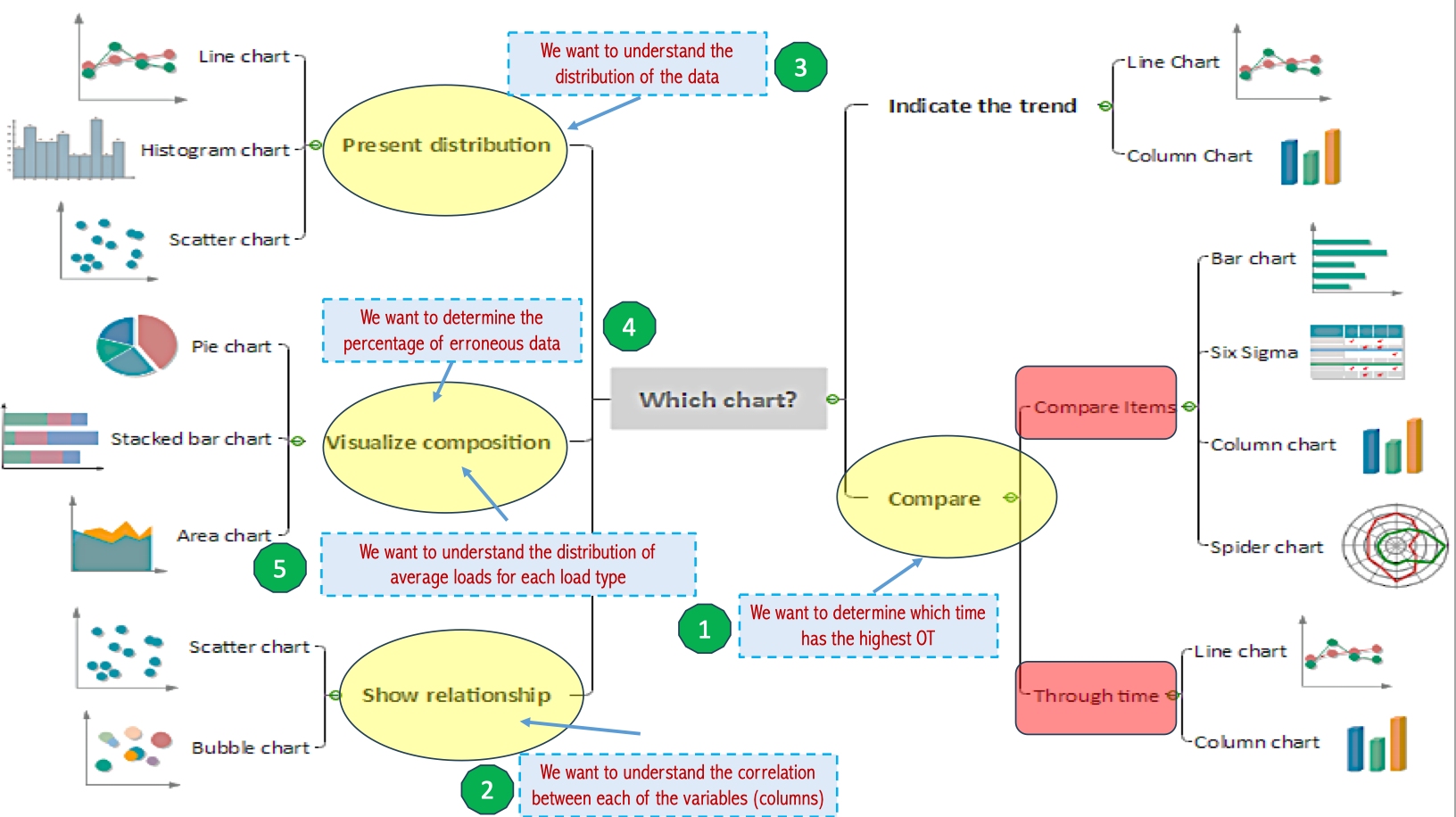
-
Xác định thời điểm OT cao nhất
→ Mục tiêu: So sánh theo thời gian (Through time)
→ Biểu đồ đề xuất: Line chart (theo trục thời gian) hoặc Column chart (nếu so sánh theo mốc cụ thể).
-
Hiểu tương quan giữa các biến
→ Mục tiêu: Show relationship
→ Biểu đồ đề xuất: Scatter chart (2 biến) hoặc Bubble chart (3 biến). Có thể mở rộng dùng Heatmap nếu muốn xem toàn bộ ma trận tương quan.
-
Phân tích phân bố dữ liệu
→ Mục tiêu: Present distribution
→ Biểu đồ đề xuất: Histogram chart (dạng tần suất) hoặc Box plot (phát hiện outlier).
-
Xác định tỷ lệ dữ liệu lỗi
→ Mục tiêu: Visualize composition
→ Biểu đồ đề xuất: Pie chart (tỷ lệ %) hoặc Stacked bar chart (so sánh giữa nhóm).
-
Phân bố tải trung bình theo từng loại tải
→ Mục tiêu: Visualize composition
→ Biểu đồ đề xuất: Pie chart, Donut chart, hoặc Stacked bar chart.
II.1. Line chart
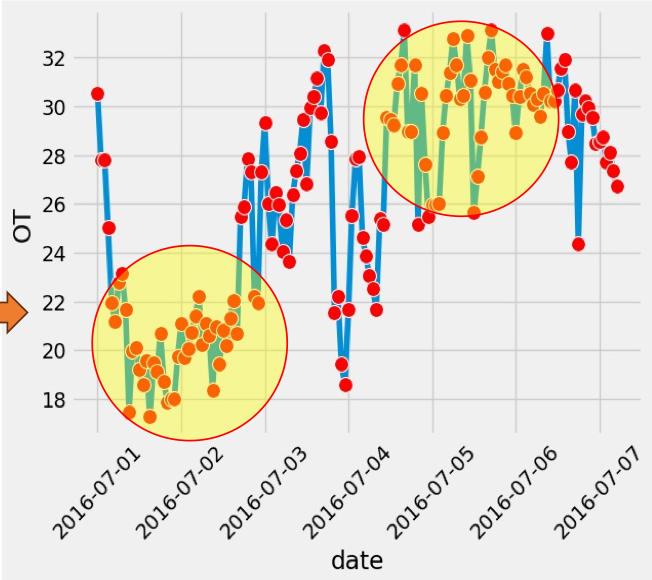
Mục tiêu: Quan sát xu hướng biến OT (Oil Temperature) theo thời gian trên 150 mẫu đầu tiên của dataset. Giải thích:
- Line chart là một trong những biểu đồ phổ biến nhất, đặc biệt trong phân tích xu hướng (trend analysis) và chuỗi thời gian (time series analysis).
- Mỗi điểm dữ liệu được biểu diễn bằng một marker (
'o') kết hợp với đường nối, cho phép theo dõi sự thay đổi của OT theo từng thời điểm ghi nhận. - Biểu đồ còn đánh dấu các cụm dữ liệu đáng chú ý bằng hình tròn vàng.
plt.plot(df.date[0:150], df.OT[0:150], marker='o', color='black',
linewidth=0.9, linestyle='--',
markeredgecolor='blue', markeredgewidth=2.0,
markerfacecolor='red', markersize=7.0)
plt.title('Oil Temperature', color='Blue', size=14)
plt.xlabel('Date', size=14)
plt.ylabel('Value', size=14)
plt.style.use('fivethirtyeight')
plt.grid(True)
plt.xticks(rotation=90)
plt.show()Phần 1 – **plt.plot()**
Hàm **plt.plot(x, y, ...)** dùng để vẽ đường nối giữa các điểm (x, y).
-
**df.date[0:150]**: Lấy 150 giá trị đầu tiên của cộtdate→ trục X (thời gian). -
**df.OT[0:150]**: Lấy 150 giá trị đầu tiên của cộtOT(Oil Temperature) → trục Y. Tham số tùy chỉnh đường và điểm: -
**marker='o'**→ Dùng hình tròn để đánh dấu từng điểm dữ liệu. -
**color='black'**→ Màu của đường nối giữa các điểm (ở đây là màu đen). -
**linewidth=0.9**→ Độ dày của đường nối (0.9 là khá mảnh). -
**linestyle='--'**→ Kiểu đường nét đứt. -
**markeredgecolor='blue'**→ Màu viền của marker (xanh dương). -
**markeredgewidth=2.0**→ Độ dày viền marker là 2px. -
**markerfacecolor='red'**→ Màu bên trong marker (đỏ). -
**markersize=7.0**→ Kích thước marker (7px). Phần 2 – Tiêu đề và nhãn trục -
**plt.title('Oil Temperature', color='Blue', size=14)**Tiêu đề biểu đồ, chữ màu xanh, cỡ 14.
-
**plt.xlabel('Date', size=14)**Nhãn cho trục X là “Date”.
-
**plt.ylabel('Value', size=14)**Nhãn cho trục Y là “Value”.
Phần 3 – Kiểu dáng và định dạng
**plt.style.use('fivethirtyeight')**→ Dùng style có sẵnfivethirtyeight(nền sáng, lưới mảnh).**plt.grid(True)**→ Bật lưới nền.**plt.xticks(rotation=90)**→ Xoay nhãn trục X 90 độ để dễ đọc khi giá trị là ngày tháng. Phần 4 – Hiển thị**plt.show()**→ Hiển thị biểu đồ.