Table of Content
Important
Tham khảo
1. Boosting Techniques
1.1. Overview of Bagging, Boosting, and Stacking

- Decision Tree là một biểu diễn trực quan của các quyết định dựa trên tập hợp điều kiện. Mỗi nhánh đại diện cho một lựa chọn, và kết quả cuối cùng ở các lá cây thể hiện nhãn hoặc giá trị dự đoán.
- Bagging (Bootstrap Aggregating) là kỹ thuật meta-algorithm kết hợp nhiều cây quyết định thông qua cơ chế bỏ phiếu đa số. Mục tiêu là giảm phương sai (variance) của mô hình bằng cách huấn luyện trên nhiều tập dữ liệu bootstrapped.
- Random Forest là một biến thể của Bagging, trong đó chỉ một tập con của đặc trưng (features) được chọn ngẫu nhiên tại mỗi bước chia node. Điều này tạo ra một “rừng cây” đa dạng và làm tăng tính tổng quát hóa của mô hình.
- Boosting xây dựng các mô hình một cách tuần tự, tập trung vào việc giảm lỗi từ các mô hình trước đó và tăng trọng số cho các mô hình hoạt động tốt. Đây là cách “tăng cường” (boost) độ chính xác dần qua từng vòng lặp.
- Gradient Boosting sử dụng thuật toán gradient descent để tối ưu hóa lỗi trong mô hình theo từng bước. Mỗi mô hình mới được xây dựng nhằm giảm sai số còn lại của mô hình trước, nhờ đó cải thiện hiệu quả dự đoán.
- XGBoost (Extreme Gradient Boosting) là phiên bản tối ưu của Gradient Boosting, với khả năng xử lý song song, cắt tỉa cây (tree pruning), quản lý dữ liệu thiếu và regularization để giảm bias/overfitting. Đây là một trong những thuật toán phổ biến nhất trong các cuộc thi AI/ML.
1.2. Ensemble Learning Techniques
Ensemble Learning là kỹ thuật học máy kết hợp nhiều weak classifiers (bộ phân loại yếu) để tạo thành một strong classifier (bộ phân loại mạnh). Ensemble learning đã được đề cập ở bài:
M04W1.4_Random Forest Advanced Concepts and Its Applications
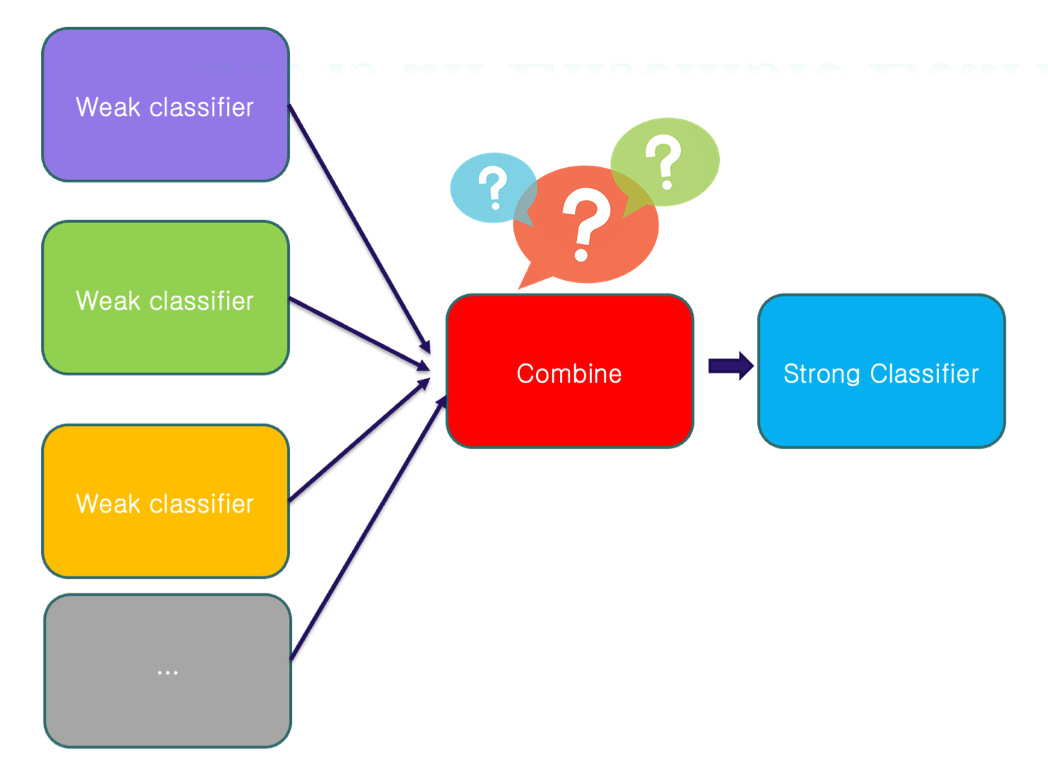
Bagging-based Method (Random Forest)
Review: Random Forest là một phương pháp dựa trên Bagging, trong đó nhiều Decision Tree được huấn luyện song song trên các mẫu dữ liệu bootstrapped. Kết quả của các cây được tổng hợp bằng majority voting (đối với phân loại) hoặc trung bình cộng (đối với hồi quy). Ưu điểm
- Giảm phương sai (variance) so với cây quyết định đơn lẻ.
- Khả năng tổng quát hóa tốt trên dữ liệu mới.
- Làm việc tốt với dữ liệu có nhiều đặc trưng và dễ mở rộng.
Hạn chế (Limitation)
- Khó diễn giải: Khi số lượng cây lớn, mô hình trở nên “hộp đen”, khó giải thích ý nghĩa.
- Tốn tài nguyên tính toán: Huấn luyện và dự đoán với hàng trăm cây có thể chậm và tốn bộ nhớ.
- Không tập trung vào lỗi: Mỗi cây trong Random Forest có trọng số ngang nhau, nên khó xử lý các điểm dữ liệu khó phân loại (không giống như Boosting).
Boosting-based Method
Boosting là phương pháp xây dựng nhiều weak classifiers (ví dụ: decision stumps hoặc decision trees nhỏ) theo cách tuần tự. Điểm khác biệt chính so với Bagging là Boosting tập trung vào các điểm dữ liệu bị dự đoán sai từ mô hình trước đó, sau đó điều chỉnh trọng số để mô hình tiếp theo học tốt hơn ở những điểm khó phân loại này.
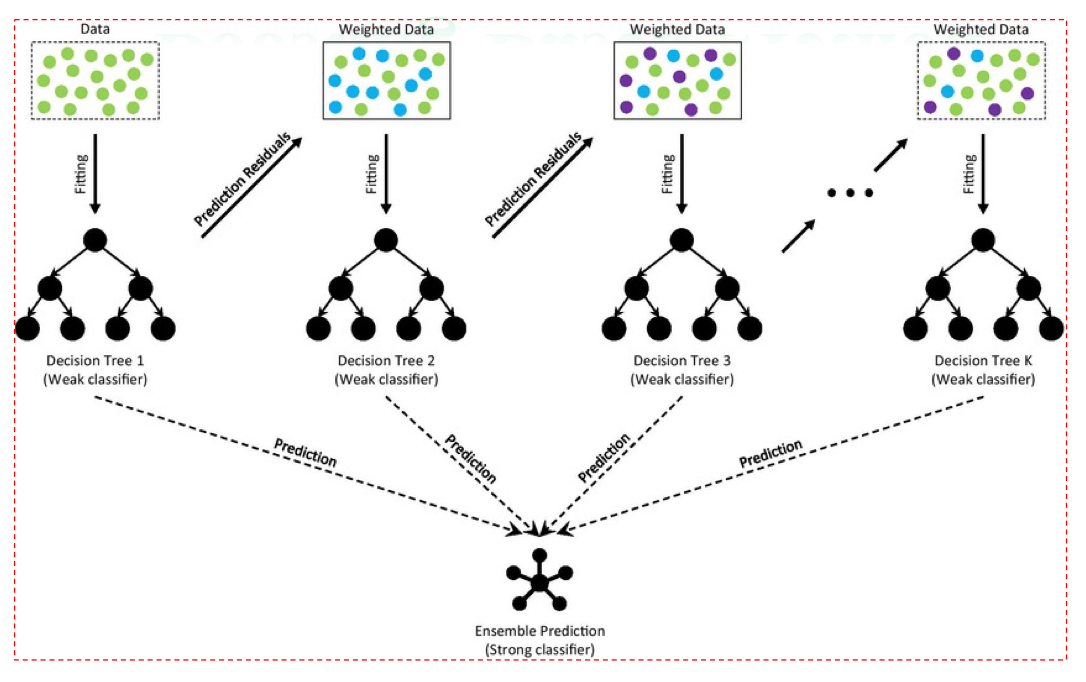 Cơ chế hoạt động
Cơ chế hoạt động
- Huấn luyện mô hình đầu tiên (Decision Tree 1) trên toàn bộ dữ liệu.
- Tính toán residuals / errors (các điểm bị phân loại sai).
- Tăng trọng số cho các điểm bị phân loại sai, giảm trọng số cho các điểm dự đoán đúng.
- Huấn luyện mô hình tiếp theo (Decision Tree 2) dựa trên dữ liệu đã được gán trọng số.
- Lặp lại quá trình cho đến khi đạt đủ số mô hình (K models).
- Kết hợp kết quả từ tất cả các mô hình (theo trọng số) để tạo thành strong classifier.
Stacking-based Method
Stacking là một phương pháp ensemble nâng cao, trong đó nhiều mô hình (có thể khác loại) được huấn luyện song song, sau đó một meta model sẽ học cách kết hợp các dự đoán từ những mô hình này để tạo ra dự đoán cuối cùng.
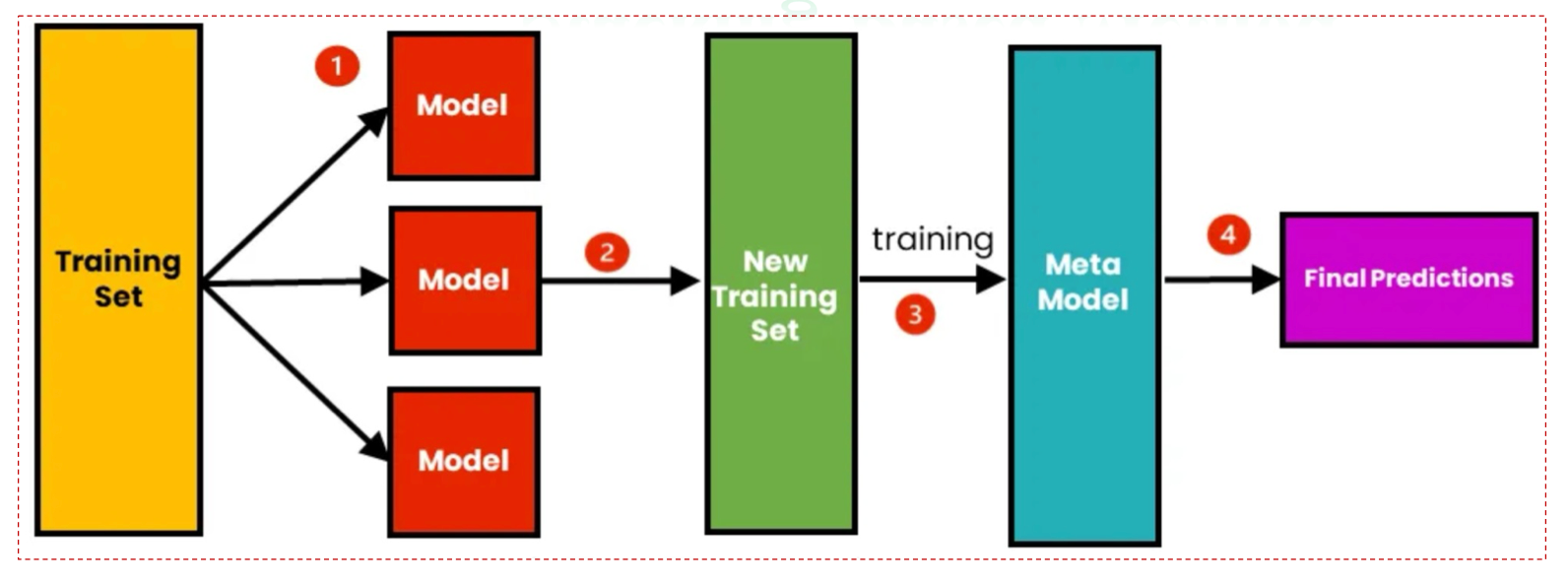
- Huấn luyện nhiều mô hình cơ sở (base models): Các mô hình này có thể là Decision Tree, Logistic Regression, SVM, hoặc Neural Network, chạy trên cùng một tập dữ liệu huấn luyện.
- Sinh tập dữ liệu mới (New Training Set): Đầu ra (predictions) của các base models sẽ được gom lại để tạo thành đặc trưng mới.
- Huấn luyện meta model: Meta model (ví dụ Logistic Regression hoặc một mô hình tuyến tính khác) sẽ học cách kết hợp đầu ra từ các base models.
- Dự đoán cuối cùng (Final Prediction): Meta model đưa ra kết quả tổng hợp với độ chính xác cao hơn so với từng base model riêng lẻ.
2. AdaBoost
Ở đây chúng ta sẽ làm quen với kĩ thuật Boosting thông qua AdaBoost Trong số các thuật toán Boosting, AdaBoost (Adaptive Boosting) là một trong những thuật toán đầu tiên và nổi tiếng nhất.
- AdaBoost sử dụng các decision stumps (cây quyết định 1 tầng) làm weak learners.
- Ở mỗi vòng lặp, AdaBoost cập nhật trọng số mẫu dữ liệu:
- Các mẫu phân loại sai được tăng trọng số → mô hình sau tập trung nhiều hơn vào chúng.
- Các mẫu phân loại đúng được giảm trọng số → ít ảnh hưởng hơn trong các vòng sau.
- Kết quả cuối cùng là strong classifier với hiệu quả cao, nhờ sự kết hợp thông minh của nhiều stumps.
2.1. Forest of Stump
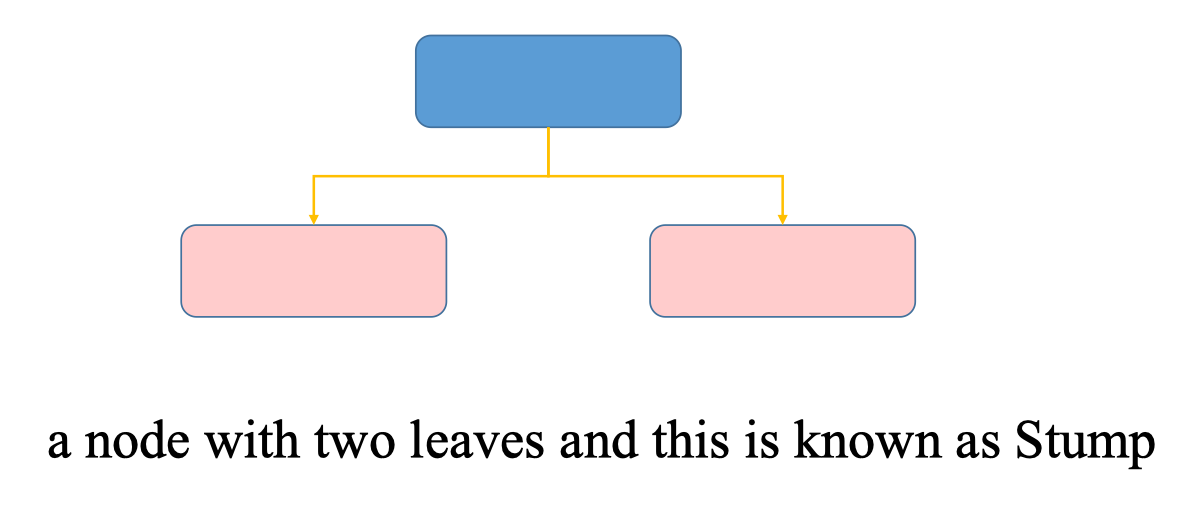
Stump
Stump là một dạng đặc biệt của Decision Tree, chỉ có một node gốc (root node) và hai lá (leaves).
- Node gốc thực hiện một phép chia đơn giản dựa trên một đặc trưng duy nhất.
- Hai nhánh đi xuống là kết quả phân loại (ví dụ: YES hoặc NO).
 Vì sao chọn Stump trong AdaBoost?
Vì sao chọn Stump trong AdaBoost? - Đơn giản & nhanh: Việc huấn luyện một stump cực kỳ nhanh chóng.
- Weak learner đúng nghĩa: Stump có độ chính xác chỉ nhỉnh hơn dự đoán ngẫu nhiên một chút.
- Kết hợp nhiều stump: AdaBoost tận dụng nhiều stump, mỗi stump khắc phục một phần lỗi của stump trước, từ đó tạo ra một strong classifier.
Forest of Stump
Trong AdaBoost, thay vì xây dựng một cây quyết định sâu và phức tạp, ta sẽ tạo ra một rừng các stumps (forest of stumps).
- AdaBoost kết hợp nhiều stump liên tiếp, mỗi stump khắc phục một phần lỗi của stump trước.
- Khi kết hợp lại, cả rừng stumps sẽ trở thành một strong classifier.
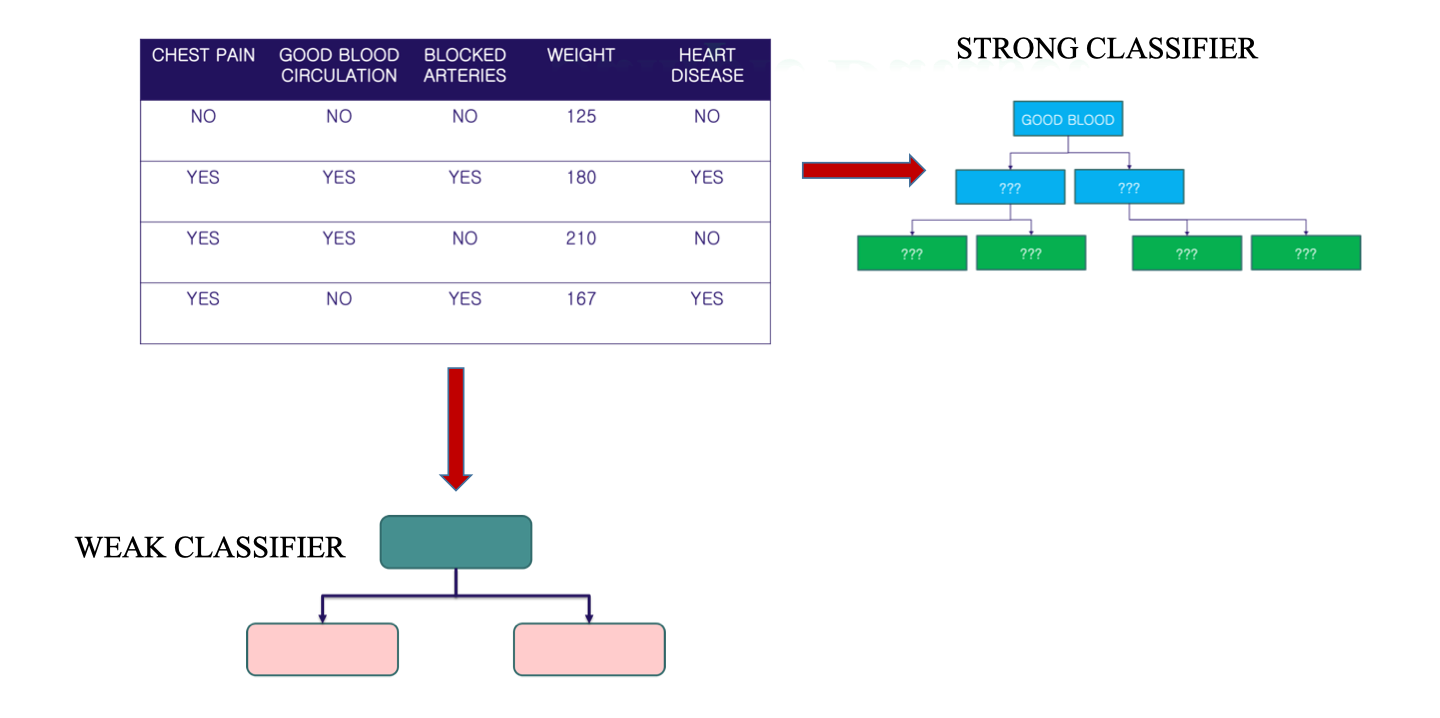
 Ví dụ minh họa AdaBoost được trình bày với một tập dữ liệu y tế nhỏ, nhằm dự đoán bệnh tim (Heart Disease) dựa trên một số thuộc tính:
Ví dụ minh họa AdaBoost được trình bày với một tập dữ liệu y tế nhỏ, nhằm dự đoán bệnh tim (Heart Disease) dựa trên một số thuộc tính:
| CHEST PAIN | GOOD BLOOD CIRCULATION | BLOCKED ARTERIES | WEIGHT | HEART DISEASE |
|---|---|---|---|---|
| NO | NO | NO | 125 | NO |
| YES | YES | YES | 180 | YES |
| YES | YES | NO | 210 | NO |
| YES | NO | YES | 167 | YES |
- Biến đầu vào (features): Chest Pain, Good Blood Circulation, Blocked Arteries, Weight.
- Biến đầu ra (target): Heart Disease (Yes/No). Từ dataset này, AdaBoost sẽ tạo ra các weak classifiers (ví dụ: stump dựa trên một thuộc tính như Chest Pain hoặc Weight).
- Một weak classifier chỉ đưa ra quyết định đơn giản (Yes/No).
- Độ chính xác thường không cao (có thể chỉ 55–60%).
Trọng số của Stump trong AdaBoost
Khác với Random Forest – nơi tất cả cây được tính trọng số ngang nhau khi bỏ phiếu, trong AdaBoost:
- Mỗi stump không được gán trọng số như nhau.
- Stump càng chính xác thì có trọng số càng lớn trong quyết định cuối cùng.
- Stump tạo ra nhiều lỗi hơn thì có trọng số thấp, đóng góp ít hơn vào strong classifier.
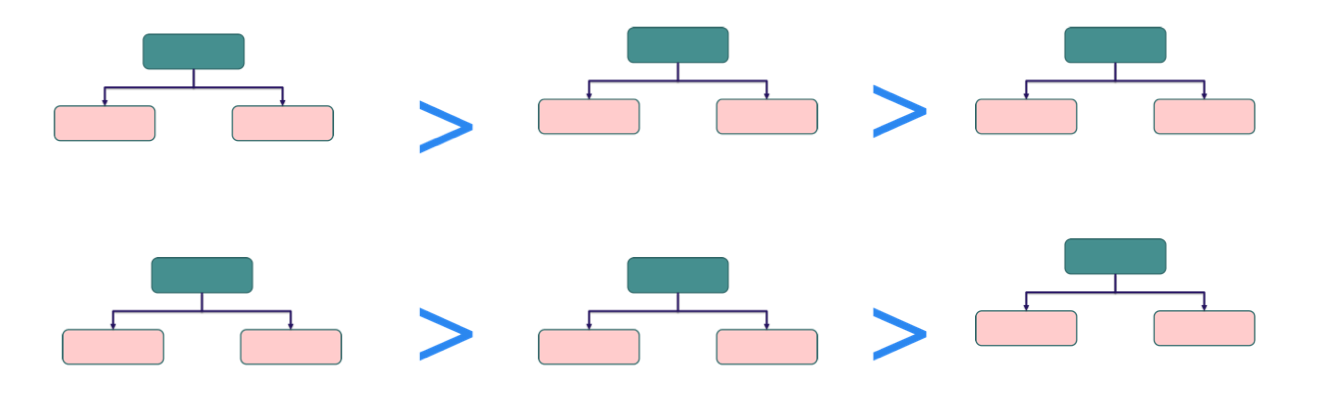 Ý nghĩa:
Ý nghĩa: - Đảm bảo rằng các mô hình “giỏi” hơn sẽ có ảnh hưởng lớn hơn trong strong classifier.
- Giúp AdaBoost tập trung vào các mô hình có khả năng phân loại tốt nhất.
- Ngăn tình trạng một số stump kém làm nhiễu kết quả cuối cùng.
Cách xây dựng stumps
Trong AdaBoost, các stumps không được xây dựng độc lập như trong Random Forest, mà có ảnh hưởng tuần tự đến nhau.
- Stump 1: huấn luyện trên dữ liệu gốc.
- Stump 2: tập trung vào các điểm mà Stump 1 dự đoán sai (thông qua cập nhật trọng số).
- Stump 3: tiếp tục học từ những sai sót còn lại của Stump 2.
- Stump 4: bổ sung thêm để giảm lỗi tổng thể.
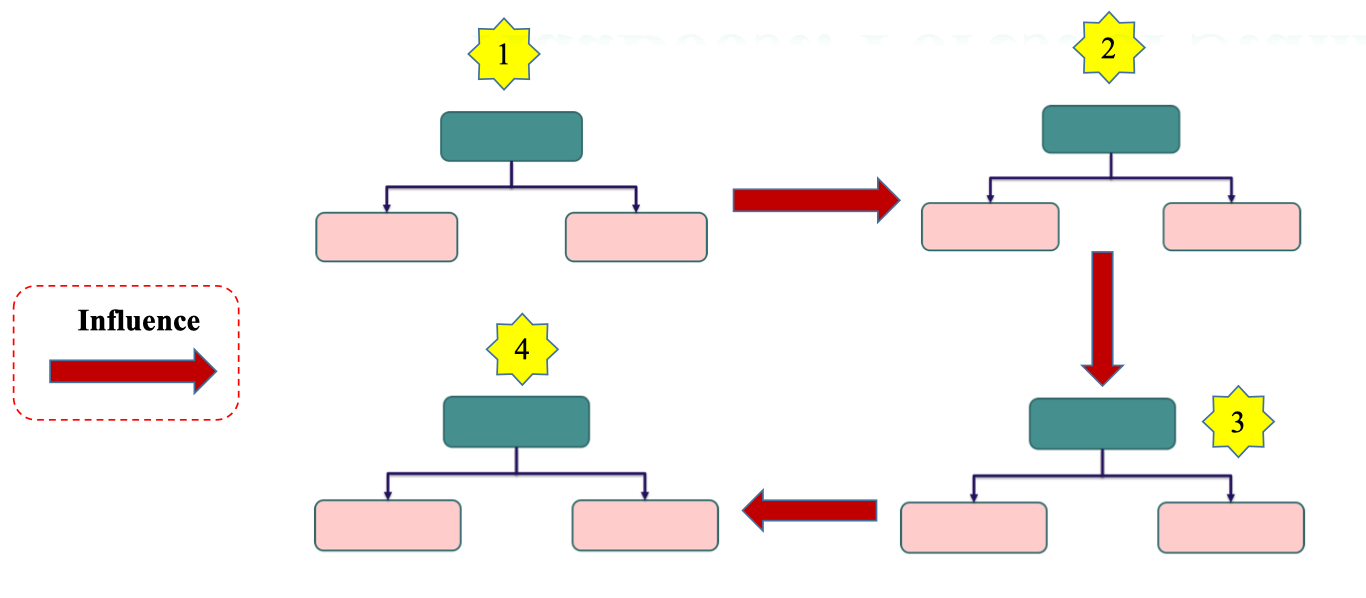 Ảnh hưởng giữa các stumps
Ảnh hưởng giữa các stumps - Ảnh hưởng từ trái sang phải: Stump mới sẽ học từ lỗi của stump trước đó.
- Ảnh hưởng từ trên xuống dưới: Tập trung dần vào các điểm dữ liệu khó hơn, ít được phân loại đúng.
- Kết quả cuối cùng: Một strong classifier, nơi mỗi stump đóng góp theo mức độ chính xác của nó.
2.2. Build the first stump
Chọn đặc trưng để chia node
Để xây dựng stump, ta cần chọn một đặc trưng giúp phân loại dữ liệu tốt nhất. Ở đây ta sẽ tính thử cho Chest Pain và Heart Diease Tính toán chỉ số Gini cho Chest Pain
-
Với Chest Pain = Yes: có 5 mẫu → 3 YES, 2 NO
-
Với Chest Pain = No: có 3 mẫu → 1 YES, 2 NO
Kết hợp theo trọng số:
Cấu trúc stump đầu tiên
- Root Node: Chest Pain
- Nhánh trái (Yes): dự đoán Heart Disease = YES (đa số mẫu YES).
- Nhánh phải (No): dự đoán Heart Disease = NO (đa số mẫu NO).
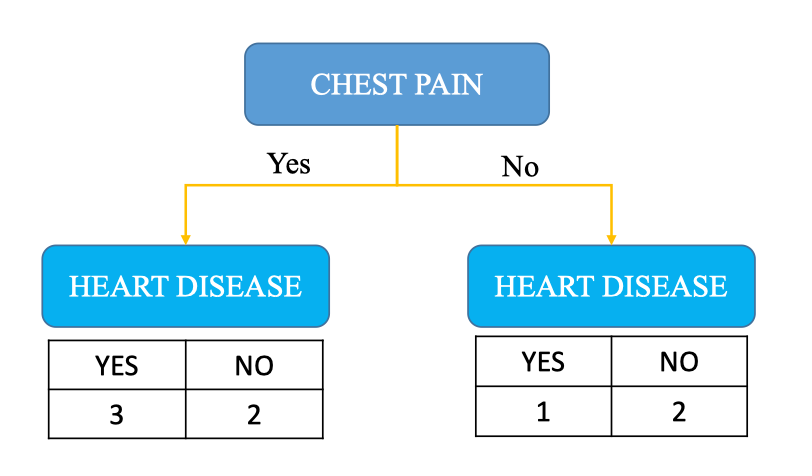 Tính toán chỉ số Gini cho Heart Diease
Tính toán chỉ số Gini cho Heart Diease
2.3. Build Next Stump
Sau khi xây dựng stump đầu tiên (Patient Weight > 170), AdaBoost sẽ:
- Tăng trọng số cho các mẫu bị phân loại sai.
- Giữ nguyên trọng số cho các mẫu được phân loại đúng.
- Nhờ vậy, stump tiếp theo sẽ tập trung nhiều hơn vào các mẫu khó, thay vì lặp lại các dự đoán cũ.
Solution 2
Công thức cập nhật trọng số Với mỗi mẫu : Trong đó:
- : trọng số mẫu trước khi cập nhật
- : amount of say (độ tin cậy của stump)
- : hàm chỉ báo (1 nếu dự đoán sai, 0 nếu đúng) Ví dụ:
- Tổng lỗi của stump = 2/8.
- Amount of say (α):
Code:
def update_weights_formula2(w_i, alpha, y, y_pred):
result = w_i * np.exp(alpha * (np.not_equal(y, y_pred)).astype(int))
w_norm = result / np.sum(result)
return w_normNew Sample Weight
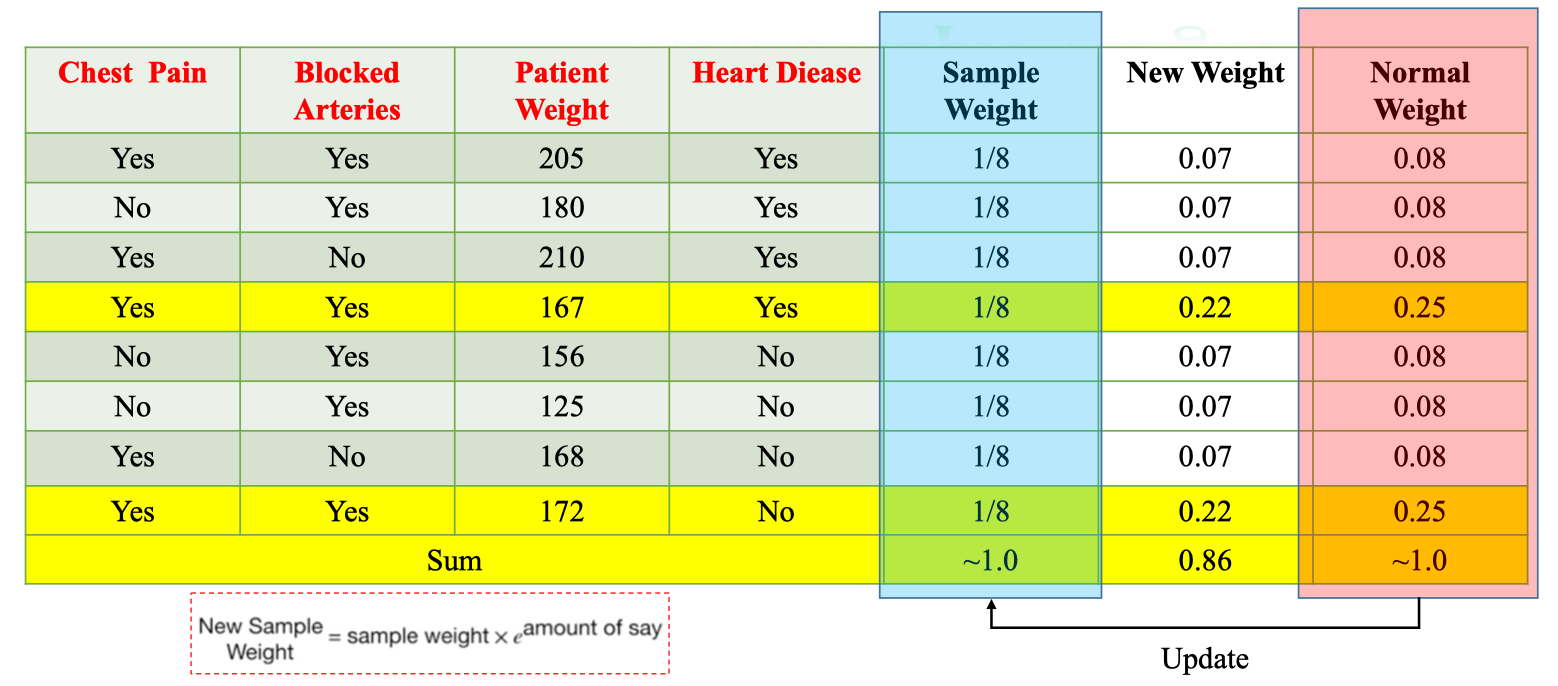 Vì tổng các New Weights không bằng 1 (ở đây tổng ≈ 0.86), nên ta phải chuẩn hóa (normalize):
Vì tổng các New Weights không bằng 1 (ở đây tổng ≈ 0.86), nên ta phải chuẩn hóa (normalize):
- Sau khi chuẩn hóa, tổng Normal Weights ≈ 1.0.
- Mẫu sai có New Weight = 0.22 → Normal Weight =
- Mẫu đúng có New Weight = 0.07 → Normal Weight = Từ đây chúng ta có thể dùng cho vòng lặp kế tiếp của AdaBoost.
New Dataset
Sau khi cập nhật Normal Weights cho từng mẫu, AdaBoost sẽ tạo một tập dữ liệu mới để huấn luyện stump tiếp theo.
- Các mẫu bị phân loại sai (có trọng số cao, ví dụ 0.25) sẽ được chọn nhiều lần hơn.
- Các mẫu phân loại đúng (có trọng số thấp, ví dụ 0.08) sẽ ít được chọn hơn.
- Điều này giúp stump kế tiếp tập trung học từ lỗi của stump trước. Phân bổ khoảng chọn mẫu Sau khi tính Normal Weight, mỗi mẫu sẽ chiếm một khoảng xác suất trong đoạn [0,1]. Ví dụ:
| Patient Weight | Heart Disease | Normal Weight | Range |
|---|---|---|---|
| 205 | Yes | 0.08 | [0 – 0.08] |
| 180 | Yes | 0.08 | (0.08 – 0.16] |
| 210 | Yes | 0.08 | (0.16 – 0.24] |
| 167 | Yes | 0.25 | (0.24 – 0.495] |
| 156 | No | 0.08 | (0.495 – 0.575] |
| 125 | No | 0.08 | (0.575 – 0.655] |
| 168 | No | 0.08 | (0.655 – 0.735] |
| 172 | No | 0.25 | (0.735 – 1.0] |
| Cách chọn mẫu mới: |
- Sinh số ngẫu nhiên
- Kiểm tra xem rơi vào khoảng nào
- Chọn mẫu tương ứng.
- Lặp lại đến khi đủ số lượng mẫu bằng dataset gốc (8 mẫu). Ví dụ:
-
Nếu → Chọn mẫu 180 (Yes).
-
Nếu → Chọn mẫu 167 (Yes).
-
Nếu → Chọn mẫu 172 (No).
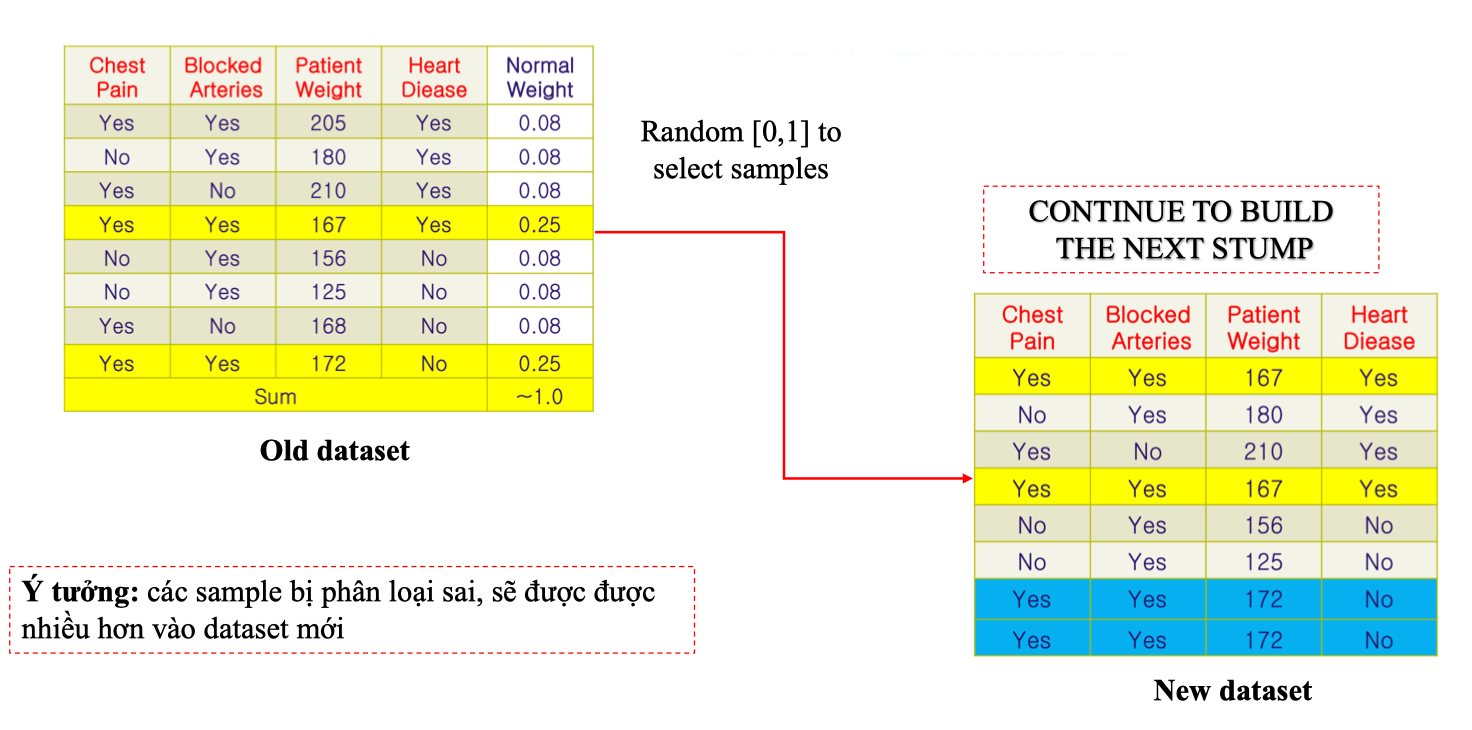
-
Các mẫu có Normal Weight cao (0.25) sẽ xuất hiện nhiều lần (như 167 và 172).
-
Các mẫu có Normal Weight thấp (0.08) ít xuất hiện hơn. Như vậy, New Dataset được tạo ra sẽ có nhiều bản sao của những mẫu khó phân loại → đảm bảo stump kế tiếp học tập trung vào các điểm này.
Forest of Stumps
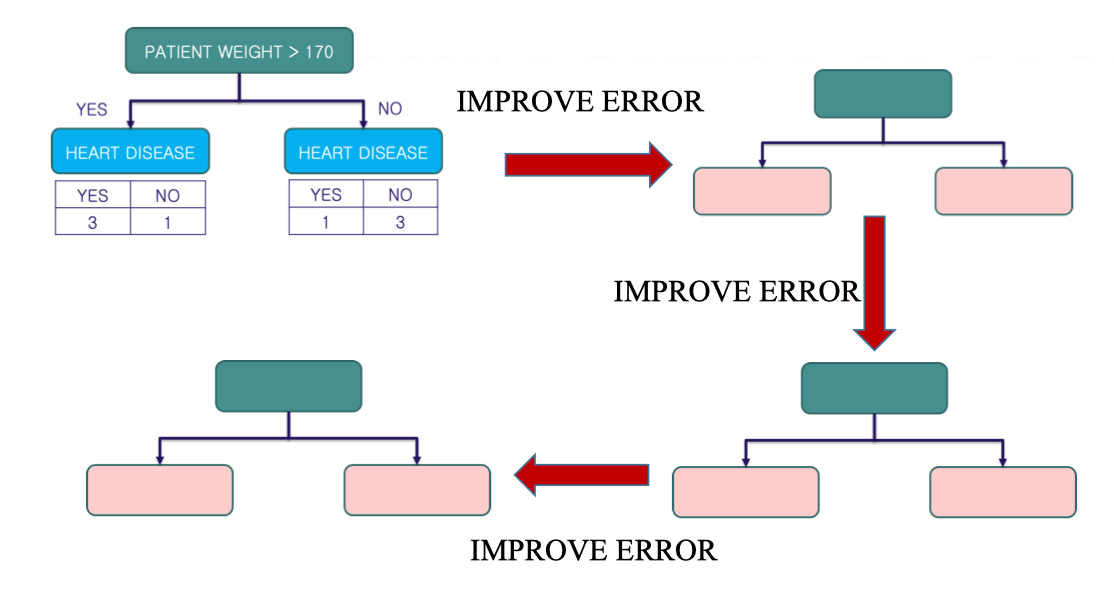 Vấn đề khi số vòng lặp stump quá lớn:
Vấn đề khi số vòng lặp stump quá lớn:
- Khi ta tiếp tục đến stump thứ N, rõ ràng là ở đây nó chỉ cập nhật weight của stump phía trước. Từ đó nó cũng không giải quyết được vấn đề là cho một kết quả dự đoán khách quan nhất. Vì vậy việc xây dựng Forest of Stumps là điều cần thiết.
2.x. Classify The Final Result
Trong AdaBoost, mỗi stump được huấn luyện để sửa lỗi của stump trước. Ví dụ: Kết thúc quá trình, ta có một tập hợp các stumps:
- Một số stumps thiên về dự đoán Heart Disease = Yes.
- Một số stumps thiên về dự đoán Heart Disease = No. Ở đây chúng ta có hai hướng tiếp cận
Algorithm 1: Freund & Schapire 1997
Ref: https://hastie.su.domains/Papers/samme.pdf
- Khởi tạo:
- Gán trọng số ban đầu cho mỗi mẫu:
- Mỗi mẫu có trọng số bằng nhau trước khi bắt đầu huấn luyện.
-
Lặp qua M vòng (m = 1 → M):
a. Huấn luyện weak classifier:
- Dùng tập dữ liệu với trọng số .
- Mỗi stump được huấn luyện ưu tiên vào những mẫu có trọng số lớn hơn.
b. Tính error của stump:
- : nhãn thật.
- : dự đoán của stump thứ m.
- : hàm chỉ báo (1 nếu sai, 0 nếu đúng).
c. Tính Amount of Say ()
- Nếu error nhỏ → lớn → stump này có tiếng nói mạnh trong strong classifier.
- Nếu error gần 0.5 → gần 0 → stump yếu, đóng góp ít.
Đào sâu vào ý nghĩa
Tại sao tác giả lại thiết kế được thuật toán trên và các công thức được xây dựng như thế nào? Ở đây ta có hàm giả thuyết (Hypothesis function):
- : số lượng stumps
- : dự đoán của stump thứ m (chỉ trả về +1 hoặc -1)
- : trọng số (amount of say) của stump, tính theo độ chính xác. Tức là strong classifier = cộng tất cả dự đoán của các stump nhưng có trọng số (stump giỏi thì nói to, stump dở thì nói nhỏ).
Tiếp theo tác giả sử dụng hàm mất mát là Exponential loss bởi vì với sai số lớn → giá trị mũ tăng rất nhanh: Trong đó:
- : nhãn thực tế
- : tổ hợp dự đoán có trọng số Nếu mẫu được phân loại sai → tích số dương → giá trị mũ tăng rất lớn → mẫu sai được trừng phạt nặng. Ví dụ: nếu dự đoán sai nặng, thay vì cộng lỗi 1 (như MSE) thì ở đây lỗi có thể thành 2, 5, 10… → khiến mô hình ưu tiên sửa lỗi này ở vòng sau.
Từ đây ta có thể thấy khi cập nhật strong classifier sau mỗi vòng (giả sử tại vòng lặp m) thì ta có: Strong classifier ở vòng m = kết quả vòng trước + stump mới nhân với amount of say.
- Nếu stump mới tốt → α cao → ảnh hưởng mạnh.
- Nếu stump mới kém → α thấp → ảnh hưởng nhỏ. Thay vào hàm mất mát:
Đặt: → Lúc này:
Note: Ở đây ta được công thức khá giống Phương trình chu kì bán rã