1. Introduction
 Machine Learning là một nhánh của Trí tuệ Nhân tạo (AI) và Khoa học Máy tính, tập trung vào việc sử dụng dữ liệu và thuật toán để mô phỏng cách con người học, từ đó dần dần cải thiện độ chính xác của nó.
Machine Learning là một nhánh của Trí tuệ Nhân tạo (AI) và Khoa học Máy tính, tập trung vào việc sử dụng dữ liệu và thuật toán để mô phỏng cách con người học, từ đó dần dần cải thiện độ chính xác của nó.
Trong lập trình truyền thống, bạn sẽ viết một chương trình với các điều kiện cụ thể để xử lý dữ liệu và đưa ra kết quả. Tuy nhiên, để tận dụng các tập dữ liệu hiện có cho các vấn đề phức tạp hơn, chúng ta có thể sử dụng Machine Learning. Một mô hình Machine Learning học cách ánh xạ một tập hợp các đặc trưng (features) X tới một giá trị mục tiêu (target) y dựa trên tập dữ liệu hiện có
**Ví dụ: Car Price Prediction
Một ví dụ điển hình để minh họa ML là bài toán dự đoán giá xe. Dữ liệu đầu vào bao gồm các thuộc tính như:
- Mileage (số km đã đi)
- Has AC? (xe có điều hòa hay không)
- Age (tuổi đời của xe)
Dữ liệu mẫu:
| Mileage | Has AC? | Age | Price |
|---|---|---|---|
| 7.5 | yes | 3 | 8.5 |
| 6.0 | no | 2 | 9.2 |
| 9.0 | yes | 4 | 7.8 |
| 4.5 | yes | 1 | 10.0 |
| 6.8 | no | 3 | 8.9 |
| 8.0 | yes | 2 | 8.3 |
| 5.5 | no | 2 | 9.5 |
Mục tiêu là xây dựng một chương trình (mô hình Machine Learning) nhận các đặc trưng đầu vào (Mileage, Has AC, Age) và trả về Price dự đoán.
I.3. Truyền thống vs Machine Learning
Truyền thống (Traditional Programming)
Trong lập trình truyền thống, ta phải viết quy tắc bằng tay để biến đổi dữ liệu đầu vào (Mileage, Has AC, Age) thành đầu ra (Price). Điều này thường được triển khai dưới dạng cấu trúc điều kiện (if-else).
[Hình: Sơ đồ điều kiện → code → giá trị dự đoán]
Vấn đề của cách này:
-
Rất khó viết quy tắc tổng quát cho dữ liệu phức tạp.
-
Các điều kiện dễ trở nên dài dòng, khó bảo trì.
-
Khó mở rộng khi dữ liệu mới xuất hiện.
Machine Learning Approach
Thay vì viết quy tắc thủ công, ta dùng dataset có sẵn để máy học quy tắc.
-
Features (X): Mileage, Has AC, Age
-
Target (y): Price
| Mileage | Has AC? | Age | Price |
|---|---|---|---|
| 7.5 | yes | 3 | 8.5 |
| 6.0 | no | 2 | 9.2 |
| 9.0 | yes | 4 | 7.8 |
| 4.5 | yes | 1 | 10.0 |
| 6.8 | no | 3 | 8.9 |
| 8.0 | yes | 2 | 8.3 |
| 5.5 | no | 2 | 9.5 |
Quy trình:
-
Training: Dùng dữ liệu đầu vào (X) và đầu ra (y) để huấn luyện Machine Learning Model.
-
Prediction: Khi có dữ liệu mới, mô hình sẽ dự đoán Price mà không cần viết quy tắc thủ công.
Machine Learning learns cách ánh xạ một tập hợp đặc trưng X sang giá trị mục tiêu y dựa trên dataset có sẵn.
1.1. Supervised Learning
Introduction
Gradient Boosting là một phương pháp ensemble theo từng bước (stage-wise ensemble), xây dựng bộ dự đoán mạnh bằng cách cộng dồn tuần tự các weak learners (thường là các cây quyết định nông). Ở mỗi vòng lặp, thuật toán khớp một cây mới vào (pseudo-)residuals hiện tại và thêm nó vào mô hình với một learning rate nhỏ, nhờ đó giảm dần loss qua từng bước.
Phương pháp này hoạt động tốt cho cả hồi quy (regression) và phân loại (classification). Khi kết hợp với các kỹ thuật regularization, Gradient Boosting thường đạt được hiệu suất hàng đầu trên dữ liệu dạng bảng.
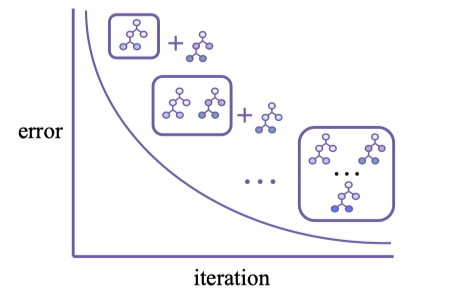
Bagging vs Boosting
Bagging và Boosting đều là kỹ thuật ensemble learning, nhưng khác nhau ở cách kết hợp các mô hình yếu (weak learners).
Trong Bagging, dữ liệu huấn luyện được chia thành nhiều sub data thông qua kỹ thuật bootstrap sampling. Các mô hình con được huấn luyện độc lập và song song, sau đó dự đoán cuối cùng được tổng hợp bằng cách bỏ phiếu (với phân loại) hoặc trung bình (với hồi quy). Bagging thường giúp giảm phương sai (variance) và chống overfitting. Ví dụ điển hình: Random Forest.
Ngược lại, Boosting huấn luyện các mô hình con theo tuần tự (sequential). Mỗi mô hình mới cố gắng sửa lỗi mà mô hình trước đó mắc phải. Cuối cùng, dự đoán tổng hợp được tính theo trọng số, trong đó các mô hình tốt hơn sẽ có trọng số cao hơn. Boosting thường giúp giảm thiên lệch (bias) và đạt hiệu suất dự đoán cao hơn. Ví dụ điển hình: AdaBoost, Gradient Boosting.