Mục tiêu
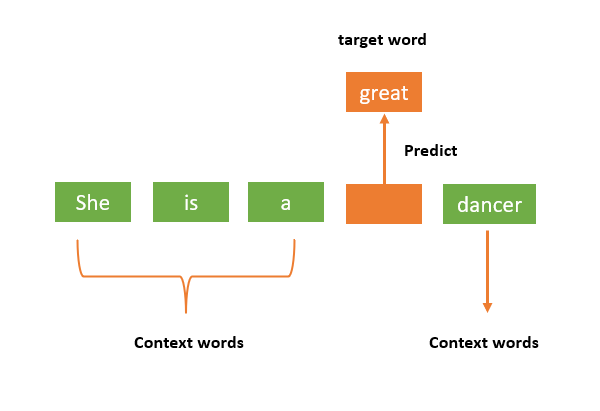
Dự đoán từ còn thiếu dựa vào ngữ cảnh.
Implement from scratch
Note: Các hàm tiện ích ở đây sẽ sử dụng lại từ bài Skip-gram.
import numpy as np
import random
import re
from collections import Counter
def tokenize(text):
"""Tokenize the input text."""
return re.findall(r'\w+', text.lower())
def build_vocab(tokens):
"""Build a vocabulary from the tokens."""
vocab = Counter(tokens)
vocab_size = len(vocab)
word2id = {word: i for i, (word, _) in enumerate(vocab.items())}
id2word = {i: word for word, i in word2id.items()}
return vocab, word2id, id2word
def generate_context_pairs(tokens, window_size=2):
"""Generate context pairs for CBOW: (context, target)."""
context_pairs = []
for i in range(window_size, len(tokens) - window_size):
context = tokens[i - window_size:i] + tokens[i + 1:i + window_size + 1]
target = tokens[i]
context_pairs.append((context, target))
return context_pairs
Define the CBOW Model
class CBOW:
def __init__(self, vocab_size, embed_size, lr=0.025):
self.vocab_size = vocab_size
self.embed_size = embed_size
self.lr = lr
# Initialize weight matrices
self.W_in = np.random.randn(vocab_size, embed_size) * 0.01 # Input to hidden layer
self.W_out = np.random.randn(embed_size, vocab_size) * 0.01 # Hidden to output layer
def forward(self, context):
"""Forward pass of the CBOW model."""
# Step 1: Average the embeddings of context words
context_vectors = self.W_in[context]
h = np.mean(context_vectors, axis=0) # Average the context word vectors
# Step 2: Calculate scores for each word in the vocabulary
u = np.dot(h, self.W_out) # Dot product to get scores
# Step 3: Apply softmax to get probabilities for each word in the vocab
exp_u = np.exp(u - np.max(u)) # Stability trick to prevent overflow
probs = exp_u / np.sum(exp_u)
return probs, h
def backpropagate(self, context, target, probs, h):
"""Backward pass to update the weights."""
# Step 1: Calculate the error (target - prediction)
target_vector = np.zeros(self.vocab_size)
target_vector[target] = 1 # One-hot encoding of the target word
error = probs - target_vector
# Step 2: Gradients for the output layer
grad_W_out = np.outer(h, error) # Gradient for W_out
# Step 3: Gradients for the hidden layer
grad_h = np.dot(self.W_out, error)
# Step 4: Gradients for the input layer
grad_W_in = np.zeros_like(self.W_in)
for i in range(len(context)):
grad_W_in[context[i]] += grad_h / len(context) # Average gradient for context words
# Step 5: Update the weights
self.W_in -= self.lr * grad_W_in
self.W_out -= self.lr * grad_W_out
Các tham số của class
def __init__(self, vocab_size, embed_size, lr=0.025):
self.vocab_size = vocab_size
self.embed_size = embed_size
self.lr = lr
# Initialize weight matrices
self.W_in = np.random.randn(vocab_size, embed_size) * 0.01 # Input to hidden layer
self.W_out = np.random.randn(embed_size, vocab_size) * 0.01 # Hidden to output layer- Khởi tạo ngẫu nhiên hai ma trận input và output có shape là vocab_size x embed_size
Forward
def forward(self, context):
"""Forward pass of the CBOW model."""
# Step 1: Average the embeddings of context words
context_vectors = self.W_in[context]
h = np.mean(context_vectors, axis=0) # Average the context word vectors
# Step 2: Calculate scores for each word in the vocabulary
u = np.dot(h, self.W_out) # Dot product to get scores
# Step 3: Apply softmax to get probabilities for each word in the vocab
exp_u = np.exp(u - np.max(u)) # Stability trick to prevent overflow
probs = exp_u / np.sum(exp_u)
return probs, hVí dụ ta có câu:
- “I love learning”
- Tokens:
['i', 'love', 'learning']
Bước 1: Tạo từ điển ánh xạ các từ tới chỉ số của chúng:
word2id = {'i': 0, 'love': 1, 'learning': 2}id2word = {0: 'i', 1: 'love', 2: 'learning'}
Bước 2: Xác định content và target Với window size = 1, từ trung tâm sẽ có một từ trước và một từ sau là ngữ cảnh của nó.
- Target word (từ trung tâm) là “love”.
- Context words (từ ngữ cảnh) là từ trước và sau “love”, tức là “i”, “learning”.
Với CBOW, ta sẽ cố gắng dự đoán từ target word (“love”) từ các context words (“i”, “learning”).
Bước 3: Khởi tạo các embedding và trọng số Chúng ta khởi tạo ngẫu nhiên các ma trận trọng số (embedding matrices).
- Ma trận W_in (Input-to-Hidden): Là ma trận ánh xạ từ các từ trung tâm tới không gian embedding.
- Ma trận W_out (Hidden-to-Output): Là ma trận ánh xạ từ không gian embedding tới không gian output, nơi ta dự đoán xác suất của các từ trong từ vựng.
Giả sử embedding dimension = 2, và chúng ta khởi tạo trọng số ngẫu nhiên:
- (với 3 từ trong từ vựng, mỗi từ có 2 chiều embedding): \begin{bmatrix} 0.1 & 0.3 \\ 0.4 & 0.2 \\ 0.6 & 0.9 \end{bmatrix}$$ * **i**: [0.1, 0.3] * **love**: [0.4, 0.2] * **learning**: [0.6, 0.9]
- (với 2 chiều embedding và 3 từ trong từ vựng): \begin{bmatrix} 0.2 & 0.1 & 0.3 \\ 0.4 & 0.5 & 0.6 \end{bmatrix}$$ * **Output vector của "i"**: [0.2, 0.1] * **Output vector của "love"**: [0.4, 0.5] * **Output vector của "learning"**: [0.3, 0.6]
Bước 4: Tính toán forward pass (dự đoán)
- Context words: “i” và “learning”.
- Context word vectors:
- “i” (context): [0.1, 0.3]
- “learning” (context): [0.6, 0.9]
-
Average embedding của context words:
Chúng ta sẽ lấy trung bình của các vector embedding của các từ ngữ cảnh (context): Vector trung gian (hidden layer) . -
Tính output scores:
Để dự đoán từ trung tâm, chúng ta tính điểm cho mỗi từ trong từ vựng bằng cách nhân vector trung gian với ma trận .Tính toán cho mỗi từ trong từ vựng:u_{\text{"i"}} = [0.35, 0.6] \cdot [0.2, 0.4] = 0.35 \times 0.2 + 0.6 \times 0.4 = 0.07 + 0.24 = 0.31$$$$u_{\text{"love"}} = [0.35, 0.6] \cdot [0.1, 0.5] = 0.35 \times 0.1 + 0.6 \times 0.5 = 0.035 + 0.3 = 0.335
Điểm số cho mỗi từ:
- “i”: 0.31
- “love”: 0.335
- “learning”: 0.465
-
Áp dụng softmax để tính xác suất cho mỗi từ:
Chúng ta sử dụng hàm softmax để chuyển các điểm số thành xác suất. Công thức softmax là:Tính toán: Tổng :
Xác suất softmax cho mỗi từ:
Backpropagation
1. Tính toán lỗi (Error) Lỗi trong mô hình được tính là sự khác biệt giữa xác suất dự đoán (probs) và xác suất thực tế (one-hot encoding của target).
target_vectorlà một mảng one-hot cho từ trung tâm (target). Vì trong ví dụ của chúng ta, từ “love” là từ trung tâm, chúng ta sẽ có:probslà xác suất mà mô hình dự đoán cho mỗi từ trong từ vựng, mà chúng ta đã tính được từ forward pass:errorlà sự khác biệt giữa xác suất dự đoán và target (lỗi dự đoán): Điều này có nghĩa là mô hình đã dự đoán một xác suất khá cao cho từ “love”, nhưng xác suất cho từ “love” thực tế phải là 1 (một-hot encoding). Vì vậy, ta có lỗi âm cho “love” và lỗi dương cho các từ khác.
2. Gradient cho output layer Tiếp theo, chúng ta cần tính gradient cho ma trận (từ hidden layer đến output layer). Gradient cho output được tính bằng cách sử dụng tích ngoài (outer product) của vector ẩn và lỗi (error).
grad_W_out = np.outer(h, error): Tích ngoài giữa vector ẩn và lỗi. Cách tính này cho phép tính được sự thay đổi cần thiết cho mỗi trọng số của ma trận .
Ví dụ:
- là vector trung gian (hidden layer).
error = [0.313, -0.679, 0.365]là lỗi.
Tính toán tích ngoài:
undefined