1. Overview
Problem
Một công ty bán lẻ có nhiều cửa hàng phát sinh dữ liệu từ ba quy trình chính: Transactions (bán hàng, thanh toán), Inventory (tồn kho, điều chuyển) và Purchasing (mua hàng, nhập kho). Dữ liệu hiện đang nằm rải rác trong Excel, MySQL và Supabase, mỗi nguồn có schema, chu kỳ cập nhật và định dạng khác nhau. Doanh nghiệp cần Collect Data về một nơi tập trung để các phòng ban Marketing, Operations và Financial dùng cho Reporting. Nếu không có pipeline, việc báo cáo phụ thuộc tay – chậm, dễ sai, khó truy vết và không đồng nhất định nghĩa chỉ số giữa các bộ phận. Bảng tóm tắt nguồn – quy trình – nhu cầu tiêu thụ dữ liệu:
| Nguồn | Quy trình | Định dạng | Cập nhật | Phòng ban sử dụng chính | Ghi chú |
|---|---|---|---|---|---|
| Excel (file cửa hàng) | Transactions | .xlsx/.csv | Hàng ngày | Marketing, Financial | Hay bị đổi cột, thiếu log tải |
| MySQL (POS/ERP) | Inventory | Bảng quan hệ | Gần thời gian thực | Operations | Dữ liệu lịch sử đầy đủ |
| Supabase (ứng dụng nội bộ) | Purchasing | Bảng quan hệ + sự kiện | Hàng giờ | Operations, Financial | Có webhook sự kiện |
| ![[image 74.png | image 74.png]] |
Why we need report?
Các câu hỏi điều hành từ CEO/manager đòi hỏi dữ liệu đã được Transform từ nhiều nguồn khác nhau (customer/transaction, transaction thuần, purchasing + inventory). Báo cáo phải tái hiện xu hướng hành vi khách hàng 2 năm, doanh số tháng trước, và tồn kho các sản phẩm chủ lực 3 tháng gần đây. Để làm được, pipeline cần chuẩn hóa schema, hợp nhất thời gian, xử lý hoàn/đổi trả và định nghĩa KPI thống nhất. Bảng liên kết câu hỏi ↔ nguồn dữ liệu ↔ biến đổi chính ↔ đầu ra:
| Câu hỏi quản trị | Nguồn dữ liệu chính | Biến đổi/kiểm soát cần thiết | Đầu ra/KPI |
|---|---|---|---|
| Xu hướng hành vi KH 2 năm | Customer, Transaction data | Chuẩn hóa customer_id, hợp nhất kênh bán, xử lý timezone, loại trừ refund/cancel | MAU/WAU, số đơn/khách, AOV, repeat-rate theo tháng; biểu đồ xu hướng |
| Doanh số bán lẻ tháng trước | Transaction Data | Lọc theo kỳ, trừ đơn bị hủy/hoàn, chuẩn hóa thuế/chiết khấu | Total Sales, Net Revenue, Orders, AOV |
| Lượng tồn của sản phẩm chủ lực 3 tháng | Purchasing, Inventory data | Sử dụng snapshot tồn kho theo ngày/tháng, quy đổi đơn vị, mapping SKU | Ending Stock, Days of Inventory, Stockout occurrences |
| ![[image 1 35.png | image 1 35.png]] | ||
| Khi chưa có ELT pipeline tập trung, các báo cáo bị xây thủ công từ nhiều nguồn (Customer/Transaction, Transaction, Purchasing & Inventory). Điều này gây tốn thời gian, phụ thuộc nhiều thao tác con người, khó tích hợp do khác công cụ/thuật ngữ, và phát sinh sai lệch khó dự đoán (chênh số, sai thông tin). Mục tiêu của phần này là nêu rõ gốc rễ vấn đề và cách ELT giải quyết để tạo báo cáo chuẩn cho Marketing/Operations/Financial. | |||
| Bảng hóa vấn đề → nguyên nhân → hậu quả → hướng giải pháp ELT: |
| Vấn đề | Nguyên nhân gốc | Hậu quả | Giải pháp trong ELT |
|---|---|---|---|
| Time Consuming (thu thập dữ liệu thủ công, build từ đầu) | Nhiều nguồn rời rạc, không lịch tải cố định | Trễ báo cáo, không tái sử dụng | Orchestration (Airflow), lịch chạy định kỳ, CDC/connector để tự động Extract & Load vào raw zone |
| Many human involve (inconsistence, human error) | Quy tắc làm sạch/định nghĩa KPI không cố định | Sai số, mỗi người một cách làm | Data contracts, dbt models/tests, code review và idempotent load |
| Hard to have integrated report (many tools, many terminologies) | Khác thuật ngữ giữa phòng ban, schema không thống nhất | Không so sánh xuyên phòng ban | Semantic layer (dbt metrics/LookML/Power BI model), star schema (Dims/Fact), SCD lưu lịch sử |
| Unpredicted Issues (number not match, wrong info) | Lệch múi giờ, chưa trừ hoàn/hủy, trùng đơn | Dashboard mất tin cậy | Data quality checks, reconciliation giữa raw ↔ staging ↔ mart, alert khi lệch ngưỡng |
Solutions
Từ những vấn đề trên, ta cần xây dựng một kiến trúc tập trung, đáng tin cậy và mở rộng tốt để sử dụng dữ liệu.
Bốn hướng giải pháp phổ biến gồm Data Warehouse, Data Lake, Data Lakehouse và Data Mesh. Mỗi mô hình phục vụ loại dữ liệu, quy mô tổ chức và nhu cầu quản trị khác nhau. Trong thực tiễn bán lẻ, ta thường bắt đầu với Warehouse để giải quyết báo cáo nghiệp vụ nhanh, sau đó mở rộng lên Lakehouse khi xuất hiện dữ liệu semi-/unstructured (log, ảnh, JSON), và cân nhắc Mesh khi số miền dữ liệu (domain) đủ lớn, đòi hỏi phân quyền sở hữu dữ liệu theo phòng ban.
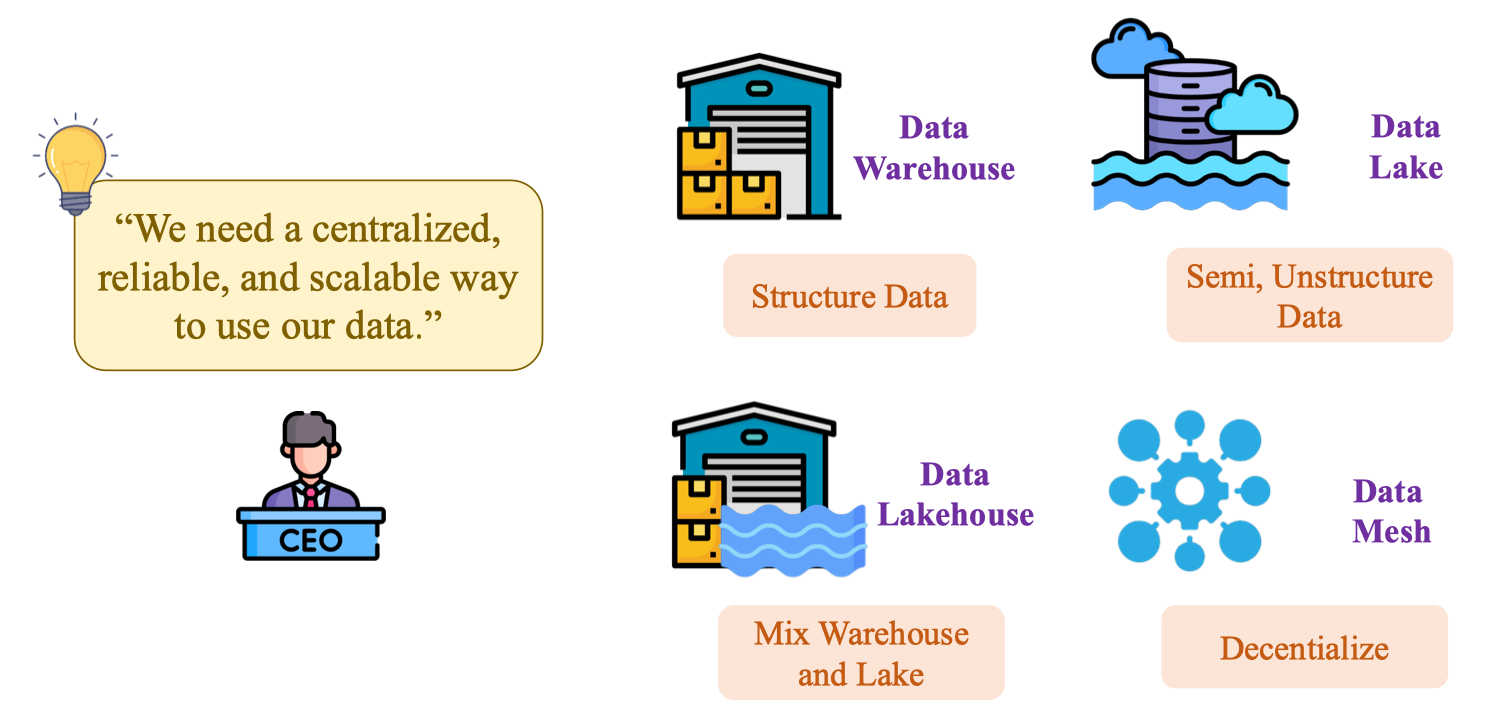
| Mô hình | Loại dữ liệu chính | Đặc trưng | Điểm mạnh | Lưu ý/Khi tránh |
|---|---|---|---|---|
| Data Warehouse | Structured (bản ghi giao dịch, tồn kho) | Lớp schema-on-write, star schema (Dims/Fact) | KPI nhanh, SQL thân thiện BI, quản trị chặt | Khó chứa file lớn/JSON phức; tốn ETL trước khi nạp |
| Data Lake | Semi/Unstructured (CSV, JSON, log, hình) | Schema-on-read, lưu object storage | Rẻ, co giãn, lưu trữ dài hạn | Thiếu semantic → khó báo cáo nếu không có “marts” |
| Lakehouse | Mixed | Hợp nhất storage (lake) + compute/ACID (warehouse), 3 lớp Bronze/Silver/Gold | Vừa linh hoạt vừa đáng tin; phù hợp ELT hiện đại | Cần kỷ luật governance, data quality |
| Data Mesh | Theo domain | Phân tán quyền sở hữu dữ liệu theo team, chuẩn hóa data product | Quy mô lớn, tự chủ domain, giảm “bottleneck” | Đòi hỏi trưởng thành về org, tiêu chuẩn hóa & catalogue mạnh |
Data Warehouse – As a Restaurant
So sánh giống như là vận hành một nhà hàng:
Dữ liệu đến từ nhiều “nguồn nguyên liệu” (Market/Mart/Farm) được đưa vào Warehouse để Collect → Cleaning → Processing → Preserve → Arrange, sau đó Kitchen chọn nguyên liệu đã xử lý để “nấu ăn” (phân tích, trực quan hóa) và phục vụ khách hàng (các phòng ban).
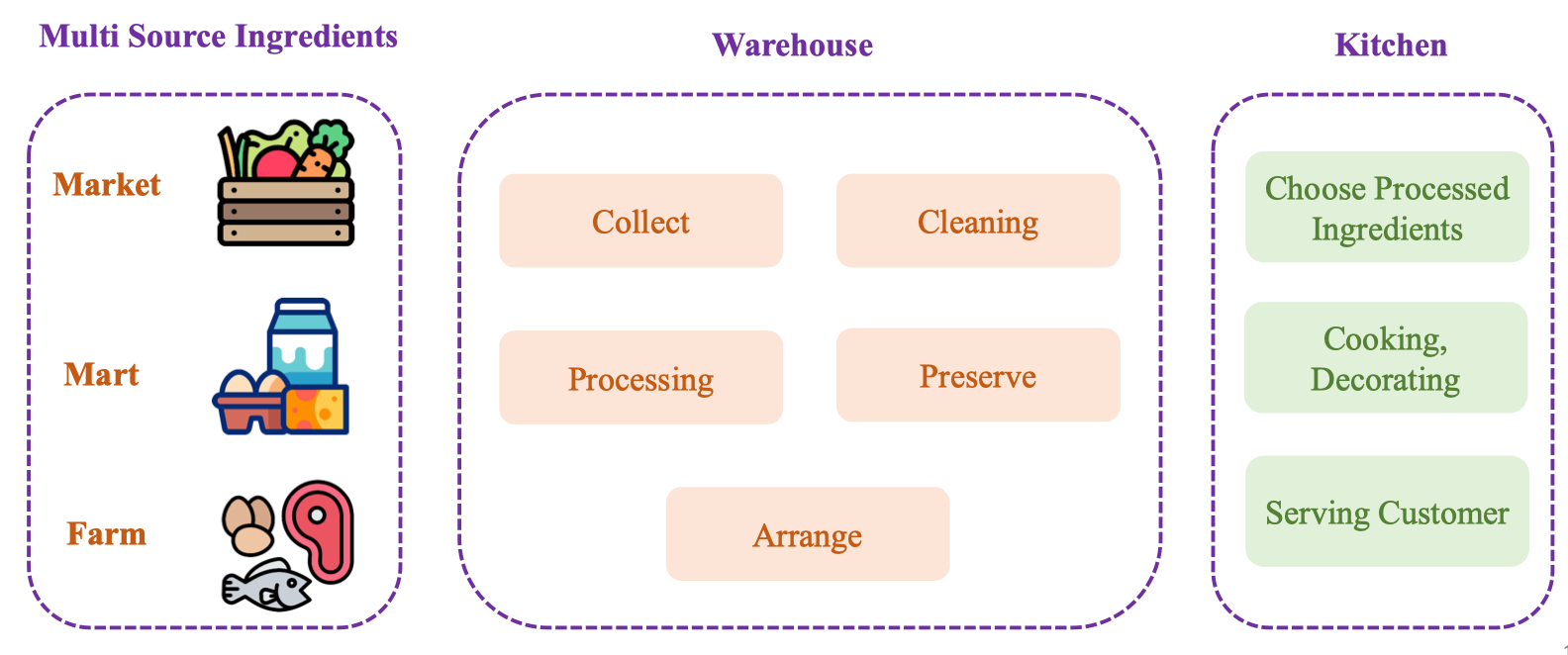
| Nhà hàng | Ý nghĩa dữ liệu | Kết quả mong muốn |
|---|---|---|
| Multi Source Ingredients (Market/Mart/Farm) | Nhiều nguồn dữ liệu (POS, ERP, Excel, API) | Dòng dữ liệu đầu vào đa dạng |
| Collect | Thu thập, lịch nạp, CDC | Dữ liệu vào raw/bronze đầy đủ, có lineage |
| Cleaning | Chuẩn hóa kiểu, loại bỏ trùng, xử lý thiếu | Dữ liệu sạch ở staging/silver |
| Processing | Tính toán, join, chuẩn hóa danh mục | Star schema: Dims/Fact |
| Preserve | Lưu lịch sử, SCD, phân vùng | Truy vấn nhanh, giữ được lịch sử |
| Arrange | Đóng gói theo semantic/metrics | Dùng chung định nghĩa KPI |
| Kitchen (Choose/Cook/Serve) | Chọn bảng đã xử lý để phân tích & báo cáo | Dashboard, mô hình ML, báo cáo định kỳ |
| ![[image 4 26.png | image 4 26.png]] |
ETL process overview
Quy trình ETL chuẩn hóa dữ liệu từ nhiều nguồn (Multi Sources: RDBMS, Excel, MongoDB) về cùng định dạng (Same Format Data), sau đó Transform để tạo Processed Data, cuối cùng Loading vào Data Warehouse sẵn sàng cho báo cáo/analytics. Trọng tâm của bước E là trích xuất có kiểm soát (checkpoint/CDC), của bước T là chuẩn hóa schema + quality gates, và của bước L là nạp an toàn, idempotent, có lineage và partitioning phù hợp.
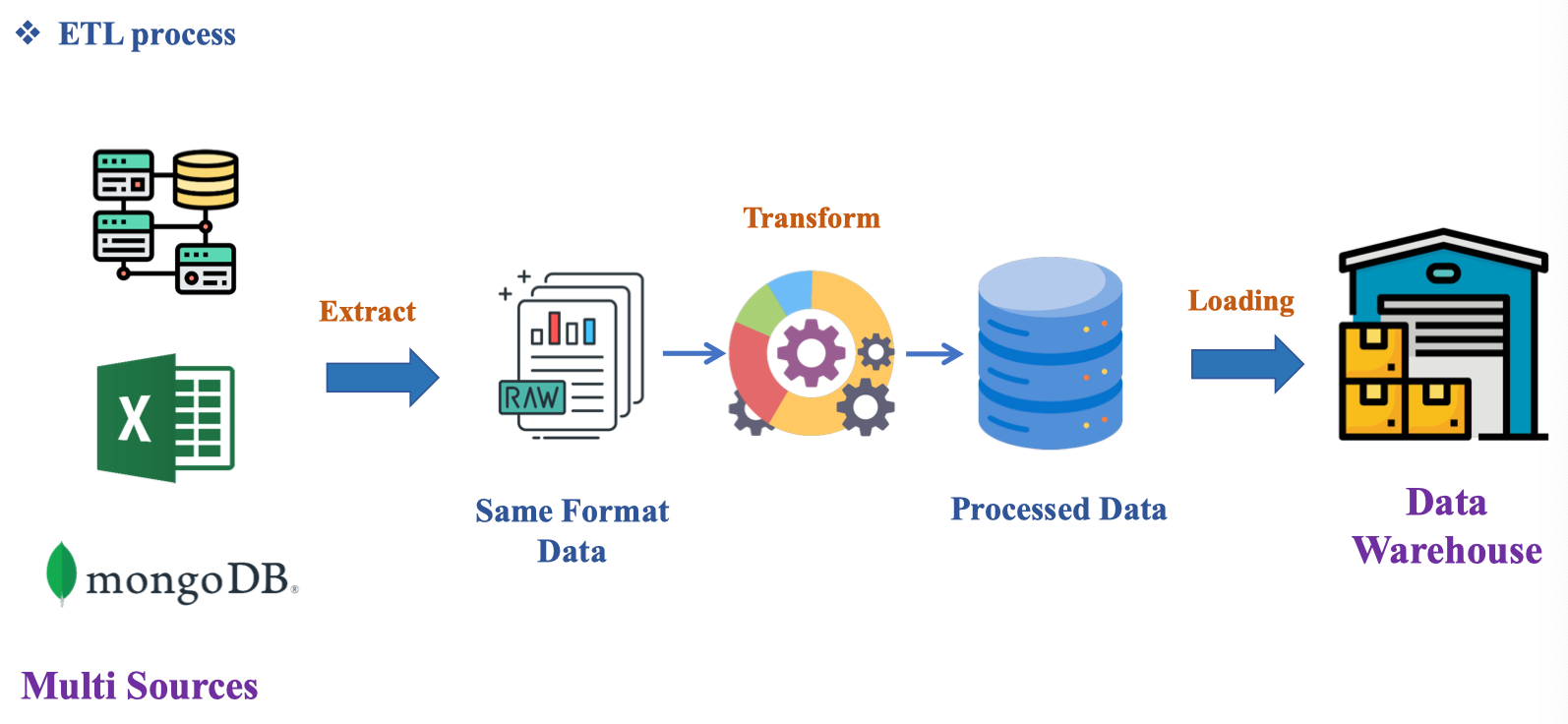
| Bước | Mục tiêu | Sản phẩm trung gian |
|---|---|---|
| Extract | Lấy dữ liệu từ nguồn, gắn ingest_time, source | Bảng raw cùng định dạng (CSV/Parquet) |
| Transform | Chuẩn hóa kiểu dữ liệu, mapping danh mục, xử lý thiếu/trùng, tính chỉ số | Bảng staging/marts (Dims/Fact) |
| Loading | Nạp vào DW, đảm bảo SCD/partition, kiểm thử cân đối số | Bảng Gold/Semantic dùng cho BI |
| Các tool hỗ trợ ETL: |
- Power BI
- Tableau
- SSIS (Visual Studio Code)
Data-driven Decision Making
Ref:
• Asana
Data-driven decision-making (DDDM) involves collecting data and using it to make decisions.
https://asana.com/resources/data-driven-decision-making
DDDM là cách tiếp cận ưu tiên dữ liệu và phân tích thay vì chỉ dựa vào trực giác để ra quyết định kinh doanh. Quy trình tổng quát: biết rõ mục tiêu, tìm nguồn dữ liệu, tổ chức dữ liệu, phân tích, và kết luận/ra quyết định. Trong bối cảnh bán lẻ, điều này chuyển hóa từ việc “đoán” sang chứng minh bằng số liệu như doanh thu ròng, tỷ lệ lặp mua, mức stockout, hoặc hiệu quả khuyến mãi.Ví dụ:
| Bước | Mục tiêu cụ thể | Ví dụ dữ liệu | Kết quả mong muốn |
|---|---|---|---|
| 1. Know your vision | Đặt mục tiêu đo lường được | “Giảm stockout 20% trong 3 tháng” | Chỉ số, mốc thời gian, phạm vi |
| 2. Find data sources | Liệt kê nguồn sự thật (POS, Inventory, Purchasing) | transactions, inv_snapshot, purchasing_orders | Danh mục nguồn + quyền truy cập |
| 3. Organize your data | Chuẩn hóa schema/khoá và lịch sử | Bảng dim/fact, SCD, partition | Single source of truth |
| 4. Perform data analysis | Phân tích, so sánh kỳ, kiểm định | A/B promo, xu hướng, cohort | Insight tin cậy |
| 5. Draw conclusions | Ra quyết định, hành động, giám sát | Thêm ngân sách kênh A, đổi ngưỡng đặt hàng | Kế hoạch + theo dõi KPI |
| Công thức (minh họa quyết định điểm đặt hàng lại): | |||
| Reorder point (ROP) = average daily demand × lead time + safety stock |
Business Intelligent
BI là chuỗi giá trị đi từ (Big) data → Information → Knowledge → Action. Kim tự tháp trong slide cho thấy các tầng chồng lên nhau: Data Sourcing (thu thập), Data Warehousing (ETL), Data Mining, Report Data Analysis, và đỉnh là Decision Making – đích đến của data-driven decision making. Ghi chú “Detail Exploration” nhấn mạnh việc đi xuống các tầng dưới để truy vấn chi tiết (drill-down) khi cần kiểm chứng con số báo cáo.
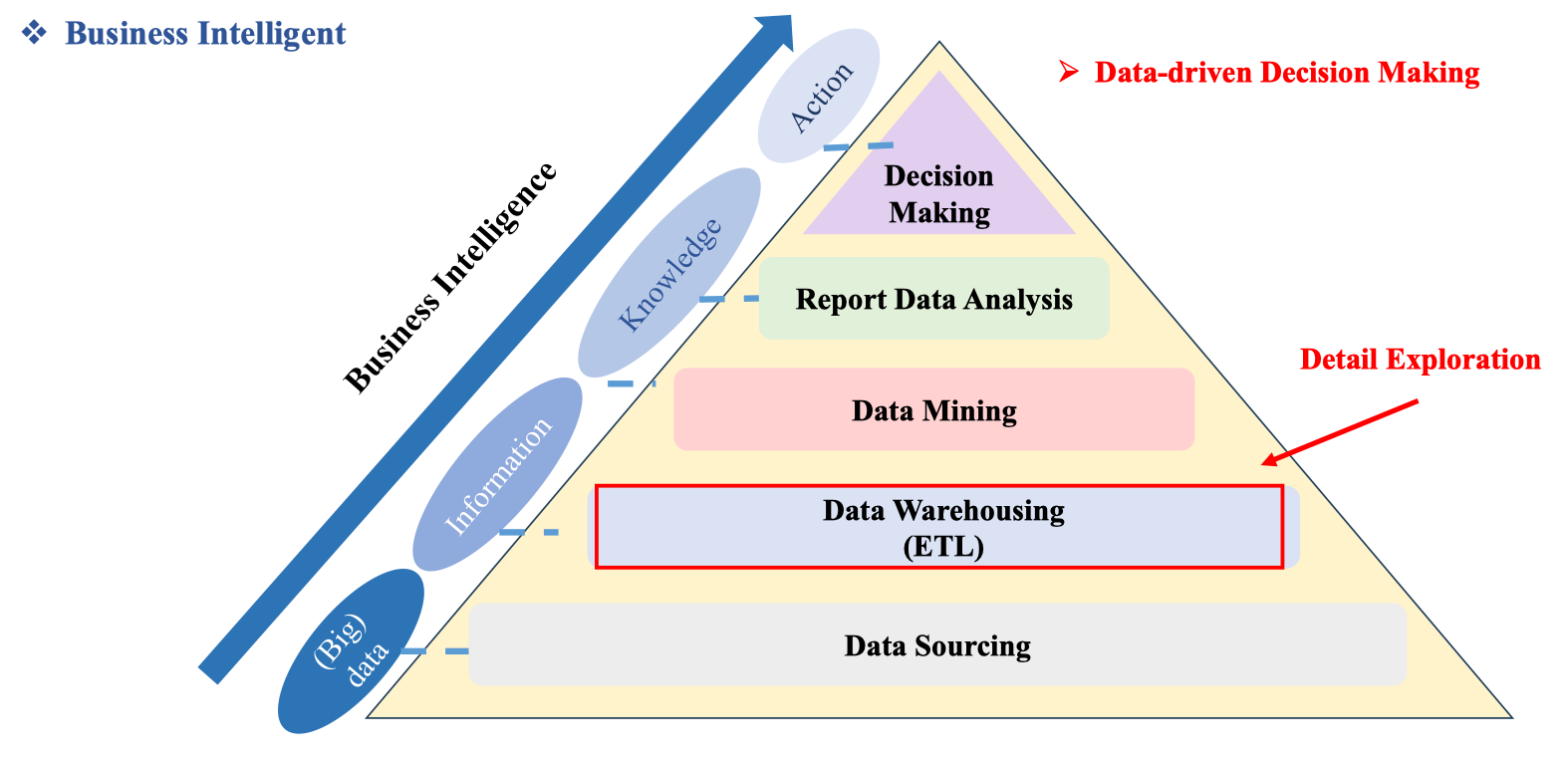 Bản đồ vai trò theo tầng BI:
Bản đồ vai trò theo tầng BI:
| Tầng | Mục tiêu | Owner chính | Sản phẩm/đầu ra | Công cụ thường dùng |
|---|---|---|---|---|
| Data Sourcing | Kết nối nguồn, bảo toàn tính toàn vẹn | Data Engineer | Raw landing + metadata | Fivetran/Airbyte, CDC, API |
| Data Warehousing (ETL) | Chuẩn hóa, lịch sử, mô hình Dims/Fact | Data Engineer | Silver/Gold marts, semantic layer | dbt, SQL, Airflow |
| Data Mining | Khai phá mẫu/luật, dự báo | Data Scientist | Feature set, mô hình | Python, Spark/SQL, MLflow |
| Report Data Analysis | Trực quan, đo KPI, theo dõi | Data Analyst | Dashboard, báo cáo tự phục vụ | Power BI/Looker/Tableau |
| Decision Making | Hành động & giám sát kết quả | Business/PO | Quyết định, A/B, guardrails | OKR, alerting/observability |
2. Data Extraction
2.1. What is Data Extraction?
Data Extraction là quá trình lấy dữ liệu từ các nguồn như CSV/Excel, RDBMS, MongoDB, API và đưa vào Staging Area. Có ba chiến lược chính:
- Pull (hệ thống chủ động lấy)
- Push (nguồn đẩy sự kiện tới ta)
- Change Data Capture – CDC (bắt thay đổi cấp log/row)
- Đồng thời, để tiết kiệm chi phí, ta ưu tiên Incremental load thay vì full refresh: chỉ lấy những bản ghi mới/cập nhật dựa trên watermark (ví dụ cột
updated_at)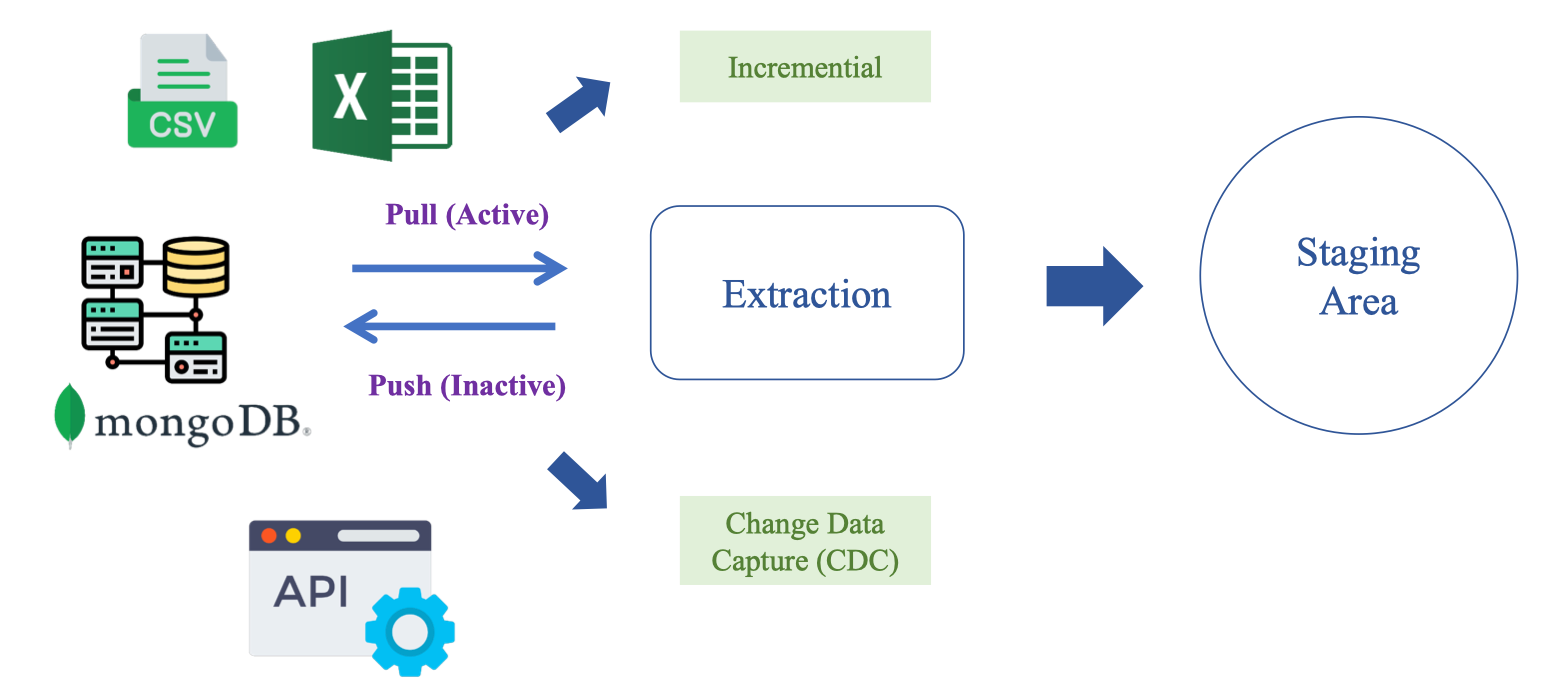
2.2. Problem during Extraction Process
Composite Key Collisions
Khi hợp nhất giao dịch từ nhiều cửa hàng/nguồn, các bản ghi có mã giao dịch giống nhau (ví dụ tran001) nhưng khác **store_id** sẽ bị trùng khóa nếu ta chỉ dùng natural key transac_id hoặc định nghĩa khóa tổng hợp (composite key) không nhất quán giữa các file/DB.
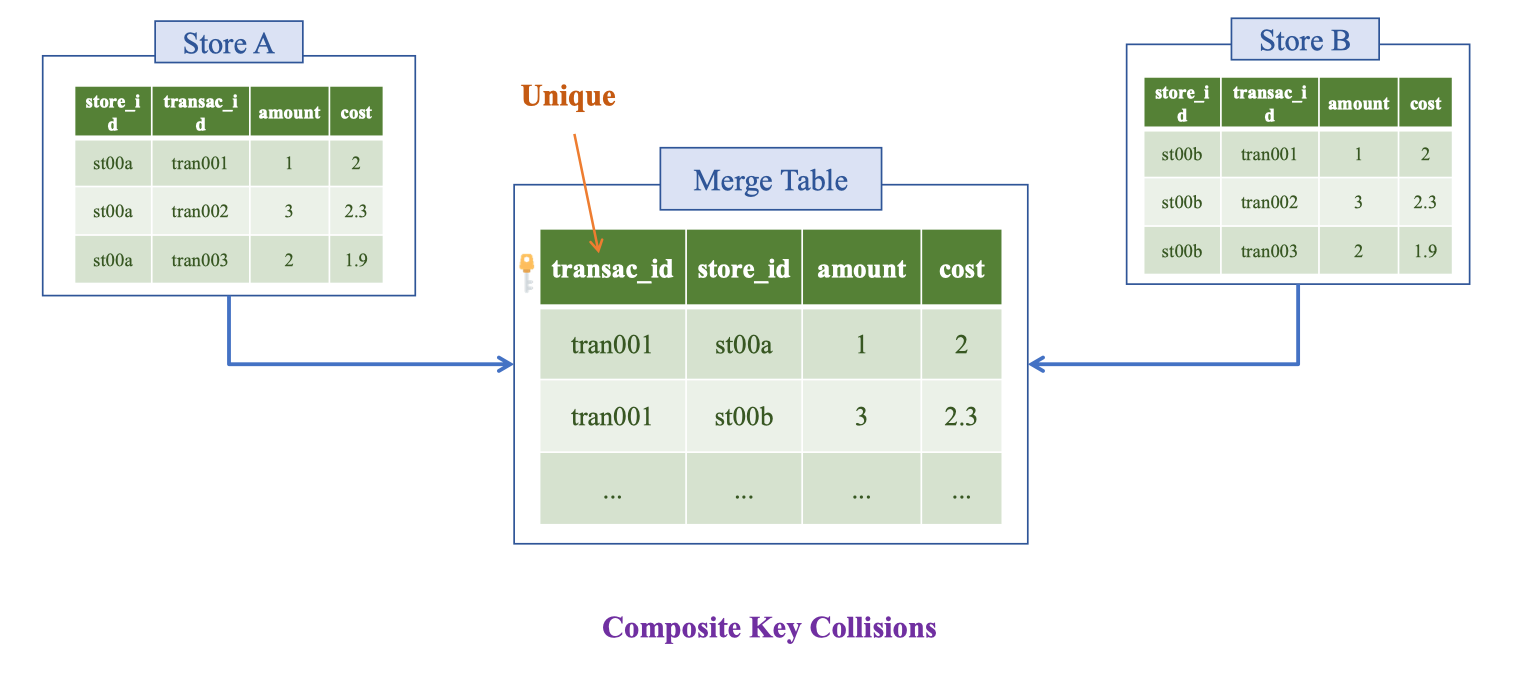 Hậu quả: bản ghi bị ghi đè, mất dòng, hoặc đếm sai khi load vào kho.
Hậu quả: bản ghi bị ghi đè, mất dòng, hoặc đếm sai khi load vào kho.
Tailored Storing Method (Unique + Version)
Cùng một business key có thể phát sinh nhiều phiên bản (ví dụ sửa đơn, bổ sung chiết khấu). Nếu chỉ ghi đè theo transac_id sẽ mất lịch sử; nếu để tự do sẽ trùng số.
Cách an toàn là thiết kế bảng merge có khóa duy nhất + version/SCD: mỗi lần bản ghi cùng business key thay đổi, ta đóng phiên bản cũ và tạo phiên bản mới.
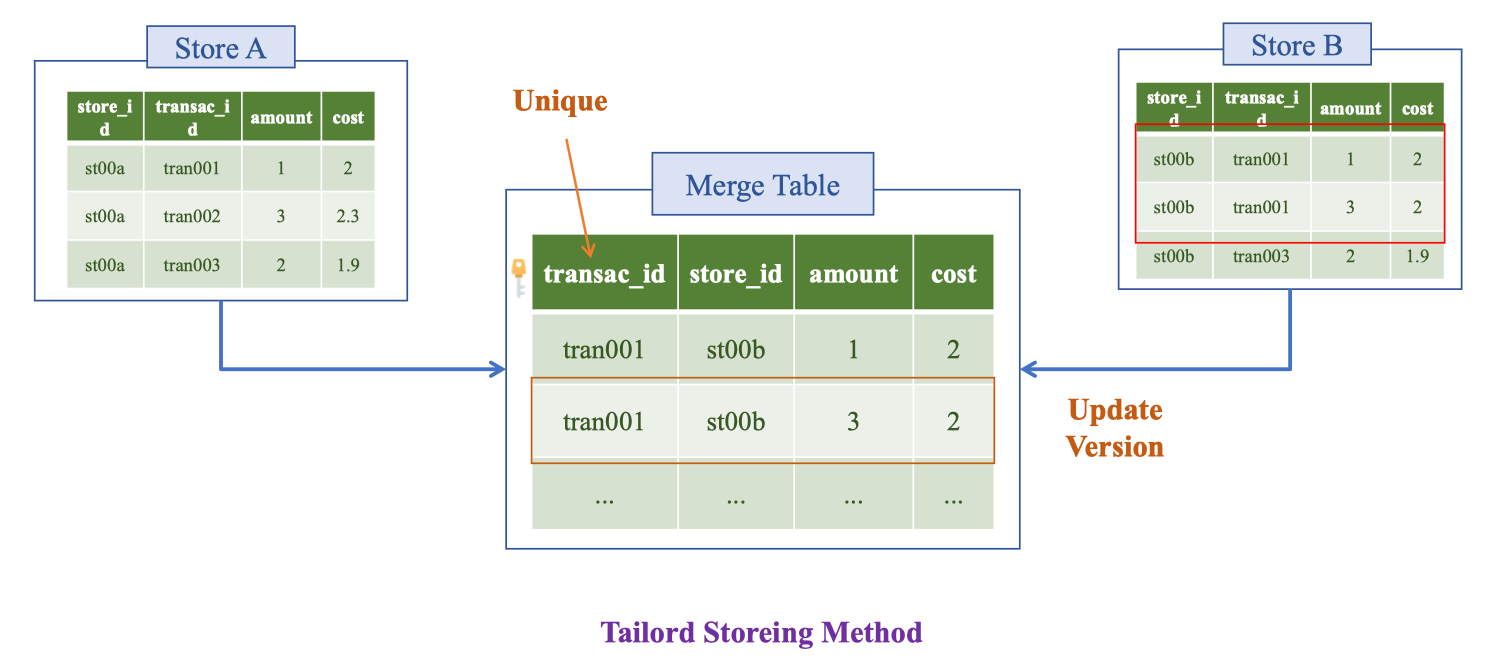 Vd: Cửa hàng cho khách hàng chuyển khoản → đổi tiền mặt.
Vd: Cửa hàng cho khách hàng chuyển khoản → đổi tiền mặt.
2.3. Case Study: Iowa Liquor Sale
Link: https://www.kaggle.com/datasets/stealthtechnologies/iowa-liquor-sales
About dataset
Bộ dữ liệu ghi nhận thông tin mua bán rượu của các cửa hàng có giấy phép loại “E” tại bang Iowa, theo sản phẩm và ngày mua (từ 01/01/2012 đến hiện tại). Dữ liệu dùng để phân tích doanh số rượu theo cấp cửa hàng và theo sản phẩm/nhà cung cấp. Bảng dữ liệu (các cột quan trọng ảnh hưởng đến doanh số):
| Column Name | Description | API Field Name | Data Type |
|---|---|---|---|
| Invoice/Item Number | Mã hóa đơn + dòng hàng, định danh duy nhất mỗi sản phẩm trong đơn | invoice_line_no | Text |
| Date | Ngày đặt mua | date | Floating Timestamp |
| Store Number | Mã cửa hàng | store | Text |
| Store Name | Tên cửa hàng | name | Text |
| Address | Địa chỉ cửa hàng | address | Text |
| City | Thành phố | city | Text |
| Zip Code | Mã bưu chính | zipcode | Text |
| Store Location | Tọa độ địa lý (geocoded) | store_location | Point |
| County Number | Mã quận của Iowa | county_number | Text |
| County | Tên quận | county | Text |
| Category | Mã danh mục sản phẩm | category | Text |
| Category Name | Tên danh mục | category_name | Text |
| Vendor Number | Mã nhà cung cấp | vendor_no | Text |
| Vendor Name | Tên nhà cung cấp | vendor_name | Text |
| Item Number | Mã sản phẩm | itemno | Text |
| Item Description | Mô tả sản phẩm | im_desc | Text |
| Pack | Số chai mỗi thùng | pack | Number |
| Bottle Volume (ml) | Dung tích mỗi chai (ml) | bottle_volume_ml | Number |
| State Bottle Cost | Giá cơ quan quản lý trả/ chai | state_bottle_cost | Number |
| State Bottle Retail | Giá cửa hàng trả/ chai | state_bottle_retail | Number |
| Bottles Sold | Số chai bán trong đơn | sale_bottles | Number |
| Sale (Dollars) | Tổng tiền của đơn | sale_dollars | Number |
| Volume Sold (Liters) | Thể tích (lít) | sale_liters | Number |
| Volume Sold (Gallons) | Thể tích (gallon), trường dẫn xuất | (derived: sale_gallons) | Number |
| ![[image 11 16.png | image 11 16.png]] | ||
| Lưu ý: Với những file có hàng triệu record thì không nên mở bằng excel mà dùng pandas để đọc. |
Tổng quan pipeline
Code: xử lý ETL https://github.com/dangnha/ETL_Iowa_liquor_sale
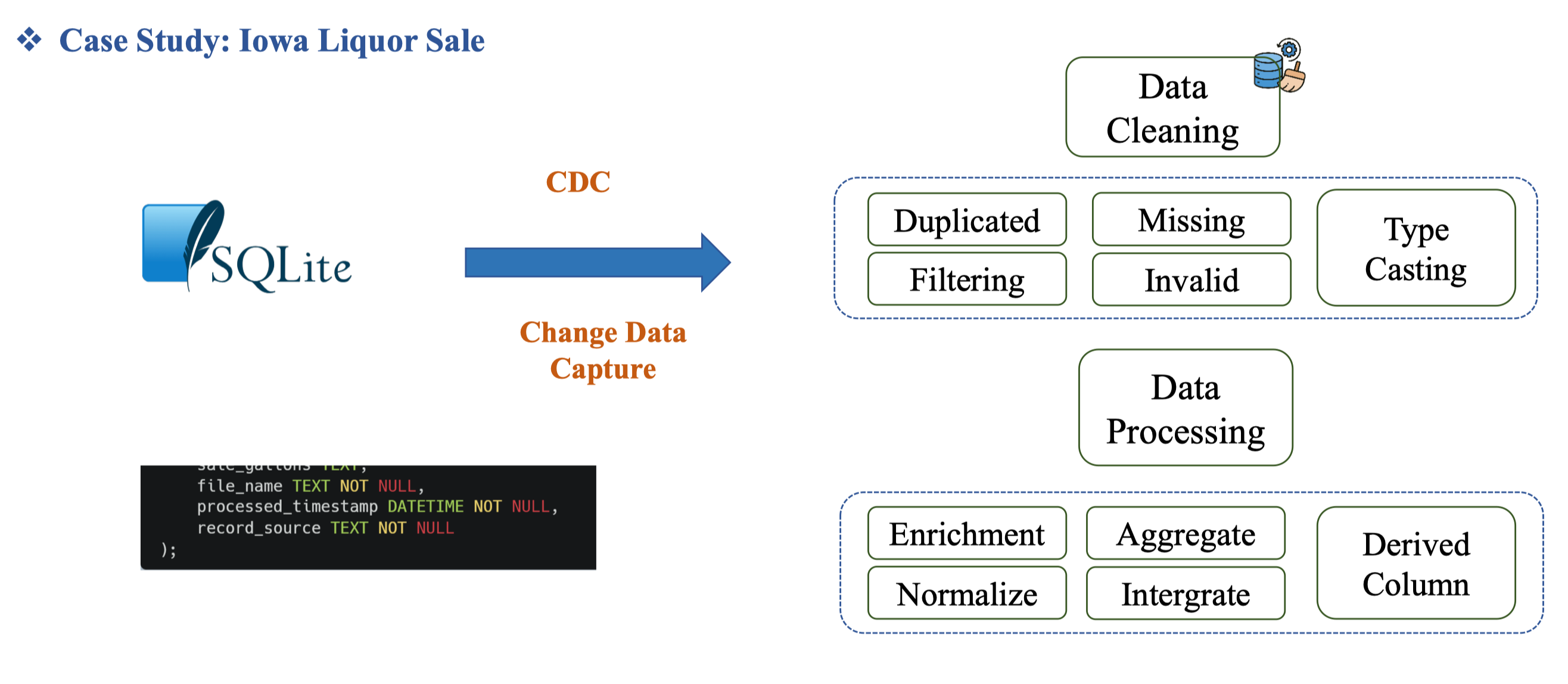
Tổng quan pipeline cho bộ dữ liệu Iowa Liquor Sales: nhiều file CSV được gom vào SQLite/Staging, sau đó Data Cleaning (loại trùng, lọc sai, điền thiếu, ép kiểu) và Data Processing (chuẩn hóa, làm giàu, tích hợp, tổng hợp, tạo cột dẫn xuất). Kết quả cuối cùng được Load vào Warehouse theo mô hình Fact–Dims phục vụ BI.
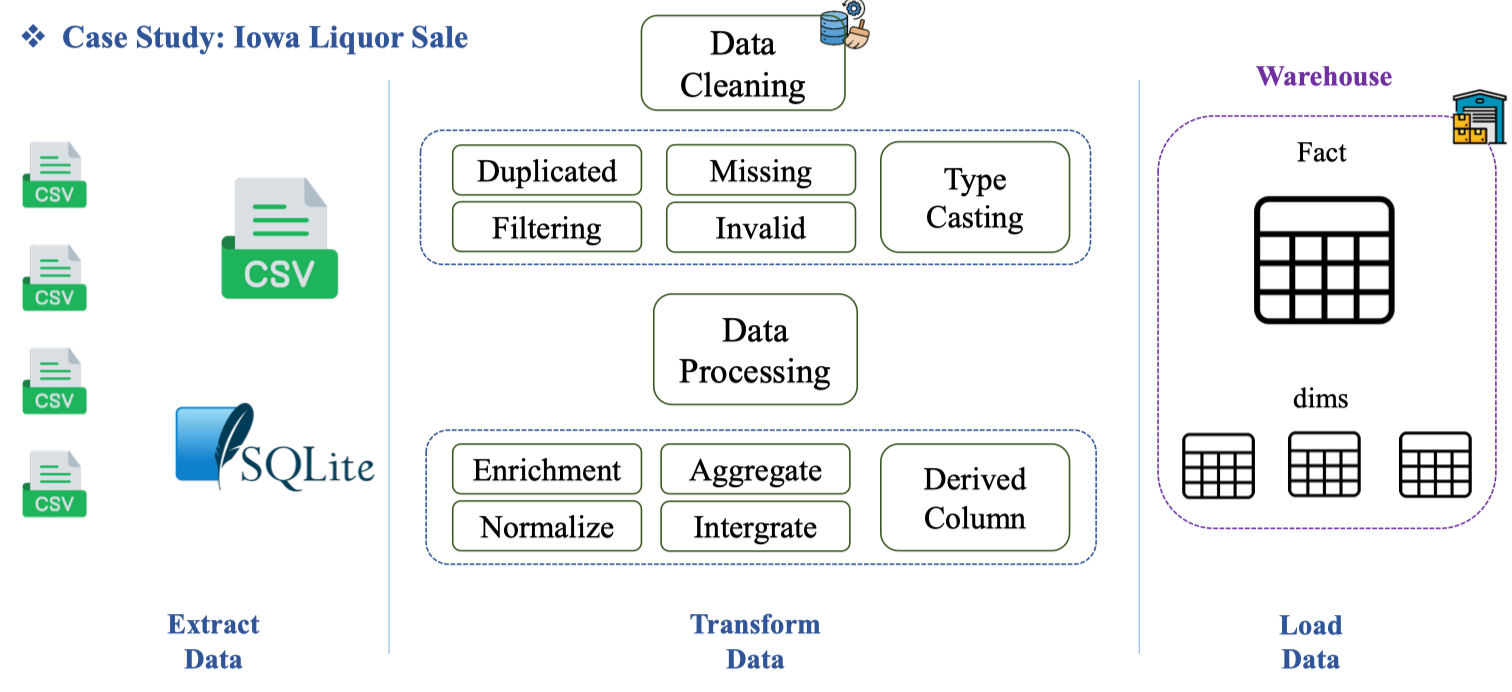
| Bước | Mục tiêu | Kỹ thuật/Quy tắc |
|---|---|---|
| Extract → Staging | Gom CSV rải rác về một DB tạm (SQLite) để kiểm soát schema | Đặt ingest_time, batch_id, giữ nguyên invoice_line_no |
| Data Cleaning | Dọn dữ liệu cho đúng và đủ | drop_duplicates(invoice_line_no), lọc date hợp lệ, điền thiếu zipcode/county nếu có, type casting số & ngày |
| Data Processing | Chuẩn hóa và tính toán | Normalize đơn vị; Integrate với danh mục store/vendor/category; Aggregate theo ngày/cửa hàng; Derived columns (doanh thu, thể tích, margin) |
| Load | Nạp vào DW theo Dims/Fact | dim_store, dim_product (SCD2); fact_sales ở hạt invoice line hoặc daily |
Data Cleaning
- Duplicated: Bản ghi trùng lặp cần loại bỏ hoặc giữ bản mới nhất. (vd: trùng
invoice_item_id)- Filtering: Lọc ra bản ghi không cần/không hợp lệ theo điều kiện nghiệp vụ. (vd: bỏ đơn test, ngày ngoài phạm vi)
- Missing: Xử lý giá trị thiếu: điền, suy luận, hoặc loại bỏ. (vd: thiếu
zipcode)- Invalid: Giá trị sai quy tắc/miền. (vd:
bottlesâm, ngày không parse được)- Type Casting: Ép kiểu đúng cho cột. (vd:
order_date→ date,sale_dollars→ numeric)Data Processing
- Enrichment: Làm giàu dữ liệu bằng thông tin ngoài. (vd: join bảng quận/huyện theo
store)- Normalize: Chuẩn hóa đơn vị/định dạng/khóa. (vd: ml → lít, lowercase mã cửa hàng)
- Aggregate: Tổng hợp theo cấp mong muốn. (vd: doanh thu theo ngày/cửa hàng)
- Integrate (thường bị viết nhầm “Intergrate”): Hợp nhất nhiều nguồn/bảng thành một bức tranh thống nhất.
- Derived Column: Tạo cột dẫn xuất từ cột gốc. (vd:
sale_dollars = retail × bottles,margin = (retail−cost)×bottles)
Extract Data Pipeline
Trong bài toán Iowa Liquor Sales, ta gom nhiều file CSV thành một nguồn hợp nhất (Iowa Liquor Sale Data), Batch Processing nạp vào SQLite làm Staging Area, sau đó triển khai Change Data Capture (CDC) để phát hiện bản ghi mới/sửa/xóa và chuyển sang bước Data Transformation. Quy trình này giúp chạy lặp ổn định, theo dõi được thay đổi và đảm bảo idempotent.
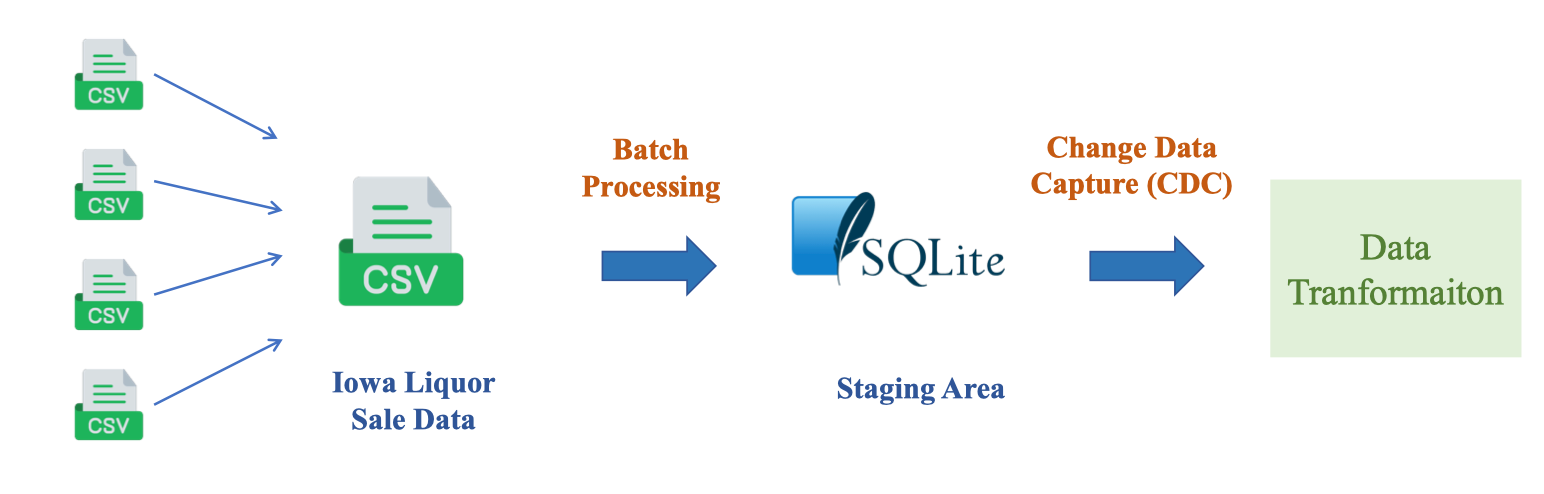
Batch Processing là gì và tại sao?
Batch Processing là cách thu thập và xử lý dữ liệu theo lô (batch) vào các thời điểm định sẵn (theo schedule: mỗi giờ/ngày/tuần). Thay vì xử lý từng sự kiện ngay khi phát sinh, ta gom dữ liệu lại, kiểm tra–làm sạch–biến đổi rồi nạp vào Staging/Warehouse trong một phiên làm việc có ràng giới rõ ràng (batch boundary). Trong case Iowa Liquor Sales, các file CSV được gom theo ngày ⇒ chạy một job batch để nạp vào SQLite/Staging trước khi CDC/Transform.
Vì sao dùng Batch?
- Phù hợp nguồn dữ liệu: file dump (CSV/Excel), xuất từ hệ thống theo kỳ.
- Đáp ứng SLA báo cáo: đa số báo cáo ngày/tháng không cần real-time.
- Đơn giản & rẻ: ít thành phần vận hành, tắt máy khi không chạy.
- Dễ kiểm soát chất lượng: có ranh giới batch để đối soát tổng, idempotent và replay khi lỗi.
- Backfill thuận tiện: nạp lại một hoặc nhiều kỳ lịch sử khi thay đổi logic.
Change Data Capture (CDC) là kỹ thuật bắt các thay đổi (insert, update, delete) từ hệ thống nguồn và phát chúng như một luồng sự kiện theo thời gian. Thay vì quét toàn bảng mỗi lần nạp, CDC chỉ gửi phần thay đổi để đồng bộ Staging/Warehouse gần thời gian thực, giảm tải lên nguồn và giữ được lịch sử biến động cho phân tích/kiểm toán.
Bản chất CDC:
- Nguồn tạo ra một chuỗi sự kiện có thứ tự cho từng khóa nghiệp vụ; đích áp dụng (apply) các sự kiện này để cập nhật bảng đích một cách idempotent.
- Thường dùng cho hệ giao dịch bận rộn (POS/ERP) hoặc khi SLA yêu cầu dữ liệu tươi hơn batch.
Vì sao dùng CDC?
- Giảm độ trễ dữ liệu;
- giảm chi phí so với quét toàn bảng;
- bảo toàn lịch sử thay đổi (hữu ích cho SCD, audit);
- an toàn cho nguồn vì không cần chạy truy vấn nặng.
Các tool hỗ trợ CDC:
- PowerBI
- SSIS: VSCode
- Tableu
- Pandas: Mạnh, tùy biến
Batch Processing → Staging
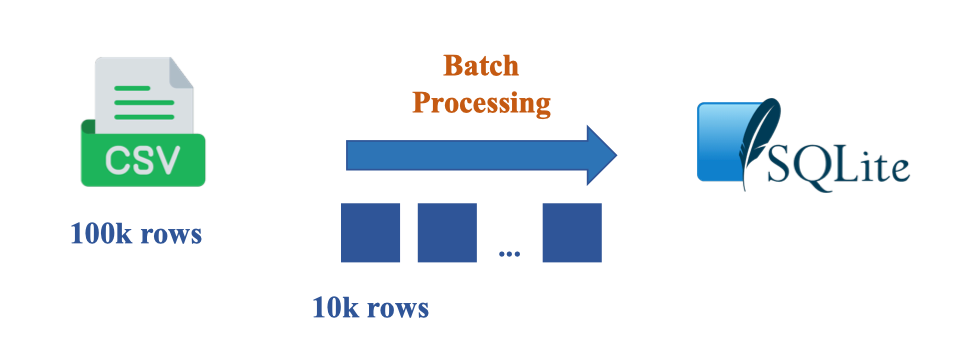
Để nạp các file CSV lớn (ví dụ 100k rows) vào Staging an toàn, ta chia lô (chunking) khoảng 10k rows/lô rồi ghi lần lượt vào SQLite. Cách này tránh tràn bộ nhớ, dễ retry, và cho phép kiểm soát chất lượng theo batch (đếm dòng, checksum). Bảng staging được định nghĩa sẵn để cố định schema và thêm metadata (file_name, processed_timestamp) phục vụ lineage và idempotency.
DROP TABLE IF EXISTS Staging_Sales;
CREATE TABLE Staging_Sales (
invoice_line_no TEXT,
date TEXT,
store TEXT,
name TEXT,
address TEXT,
city TEXT,
zipcode TEXT,
store_location TEXT,
county_number TEXT,
county TEXT,
category TEXT,
category_name TEXT,
vendor_no TEXT,
vendor_name TEXT,
itemno TEXT,
im_desc TEXT,
pack TEXT,
bottle_volume_ml TEXT,
state_bottle_cost TEXT,
state_bottle_retail TEXT,
sale_bottles TEXT,
sale_dollars TEXT,
sale_liters TEXT,
sale_gallons TEXT,
file_name TEXT NOT NULL,
processed_timestamp DATETIME NOT NULL
);Ở đây chỉ là Extract data nên chúng ta thấy chưa có Cleaning ví dụ như làm Type Casting.
Batch Processing “New File” → Staging (SQLite) kèm metadata
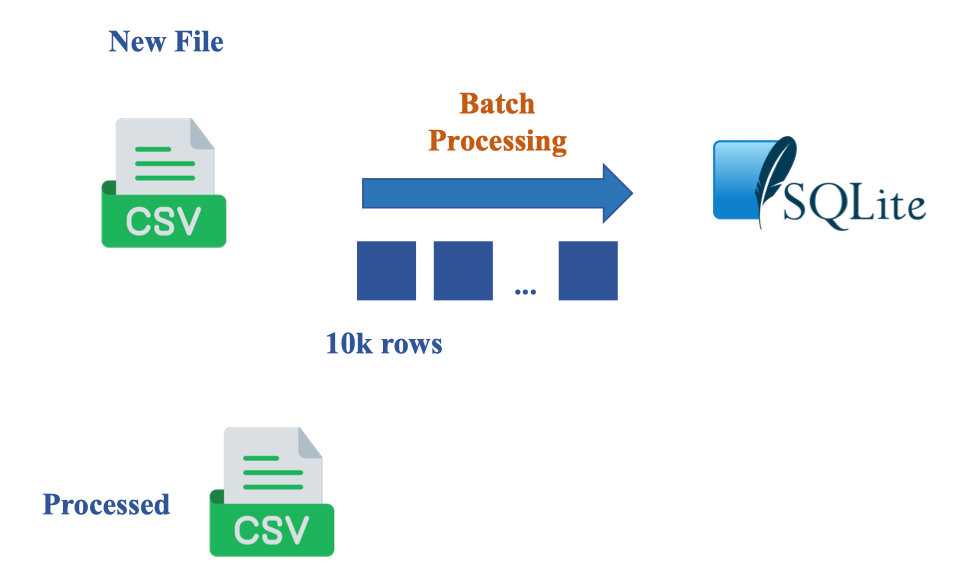
Sau khi đã set up bộ dataset thì từ đây về sau mỗi khi thêm những file mới:
Trong luồng batch, mỗi file CSV mới được đọc theo lô 10k dòng, ghi vào bảng Staging_Sales của SQLite rồi được đánh dấu đã xử lý (Processed) để tránh nạp lặp. Bảng staging cố định schema và bổ sung metadata: file_name, processed_timestamp, record_source (ví dụ: incoming, historical, fixup) giúp lineage, idempotent và truy vết nguồn.
CREATE TABLE Staging_Sales (
invoice_line_no TEXT,
date TEXT,
store TEXT,
name TEXT,
address TEXT,
city TEXT,
zipcode TEXT,
store_location TEXT,
county_number TEXT,
county TEXT,
category TEXT,
category_name TEXT,
vendor_no TEXT,
vendor_name TEXT,
itemno TEXT,
im_desc TEXT,
pack TEXT,
bottle_volume_ml TEXT,
state_bottle_cost TEXT,
state_bottle_retail TEXT,
sale_bottles TEXT,
sale_dollars TEXT,
sale_liters TEXT,
sale_gallons TEXT,
file_name TEXT NOT NULL,
processed_timestamp DATETIME NOT NULL,
record_source TEXT NOT NULL
);3. Data Transformation
3.1. Handle duplicated
-Duplicated: trong train model, khi những dữ liệu trùng thì ta đơn giản là xóa nó. Nhưng trong quy trình ETL thì ta cần phải cẩn thận đối chiếu trước khi thực hiện xóa hoặc gộp lại.
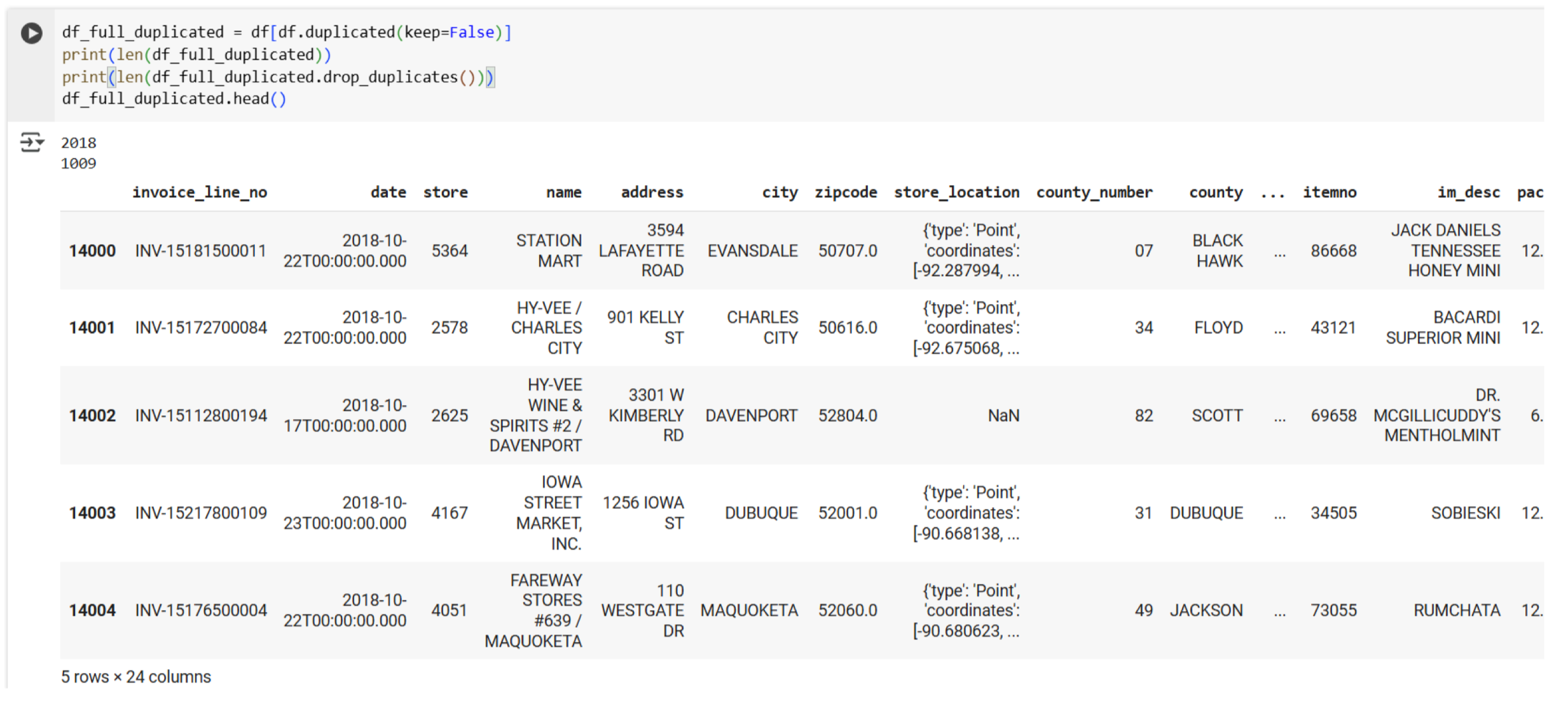
Ở đây có 2018 sample bị duplicate và sau khi xóa thì còn lại 1009 dòng.
Tuy nhiên nếu thử xử lý duplicate duyệt theo invoice và store
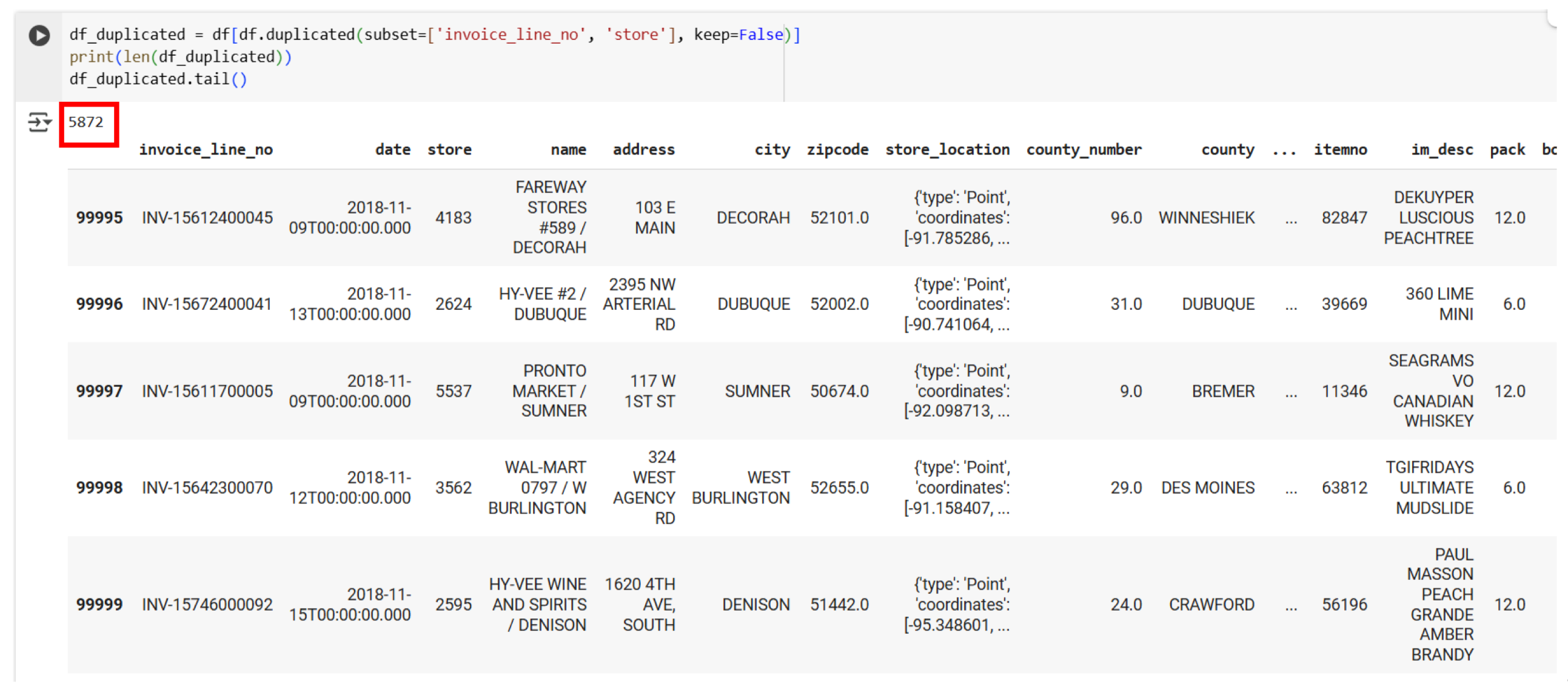 Thì ta thấy là có tận 5872 sample bị trùng nhau
Từ đó ta phải tự tìm hiểu xem là các bản ghi trùng nhau ở đâu và xung đột cái gì:
Thì ta thấy là có tận 5872 sample bị trùng nhau
Từ đó ta phải tự tìm hiểu xem là các bản ghi trùng nhau ở đâu và xung đột cái gì:
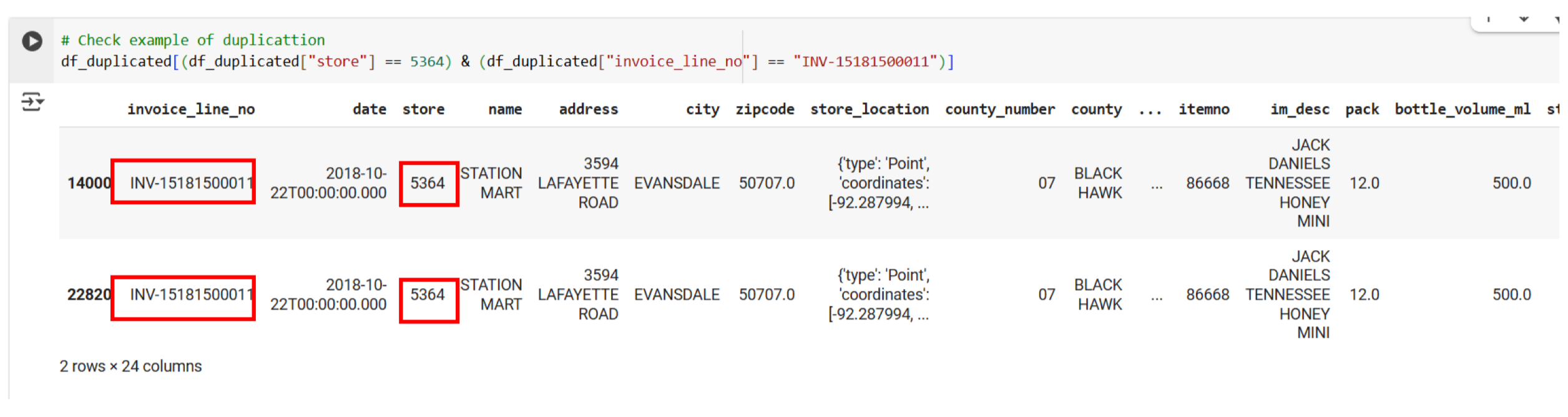
Duyệt thử một mẫu, thì ta thấy hai bản ghi này sẽ là trường hợp hoàn toàn trùng nhau nên có thể xóa dễ dàng df_duplicated.dropna() .
Mặt khác ta sẽ xét trường hợp sau:
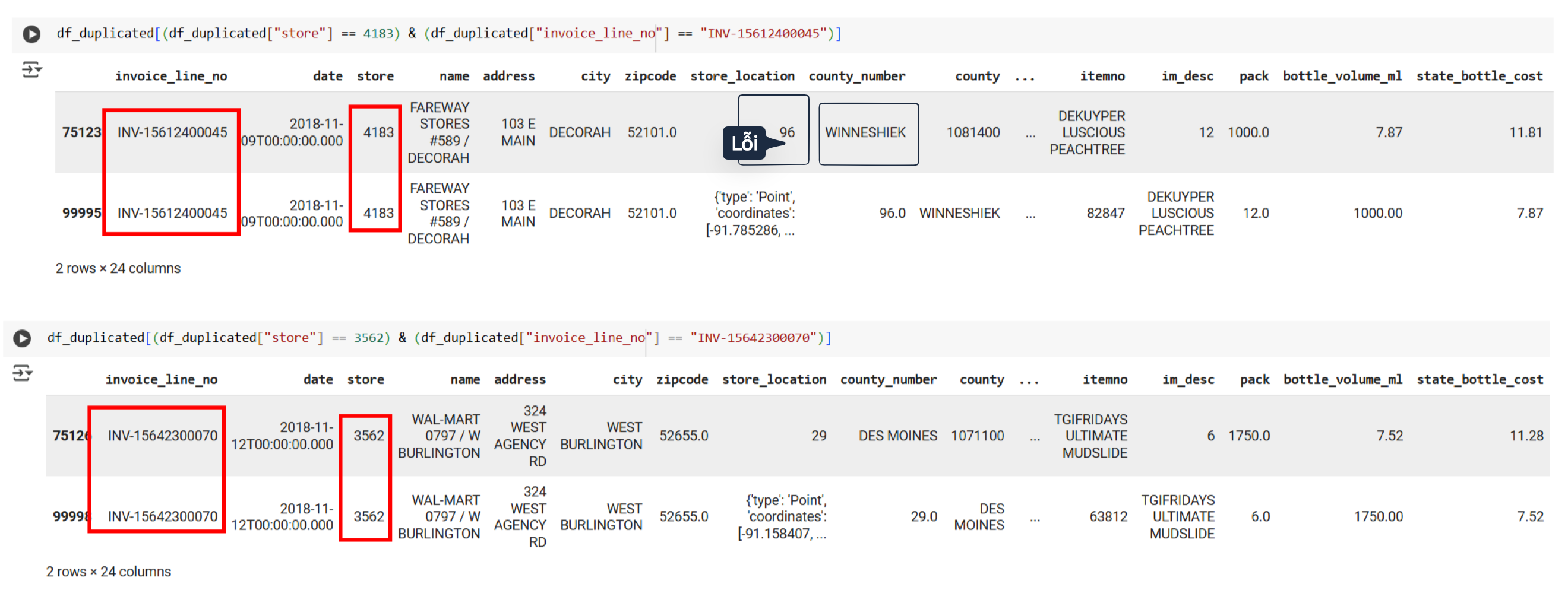 Ở đây ta thấy các dòng đầu tiên của hai mẫu trùng đều bị lỗi (store_location là số, sai county_number,…)
Vì vậy ở đây ta sẽ xóa dòng đầu của các mẫu trùng để lấy dòng sau như sau:
Ở đây ta thấy các dòng đầu tiên của hai mẫu trùng đều bị lỗi (store_location là số, sai county_number,…)
Vì vậy ở đây ta sẽ xóa dòng đầu của các mẫu trùng để lấy dòng sau như sau:
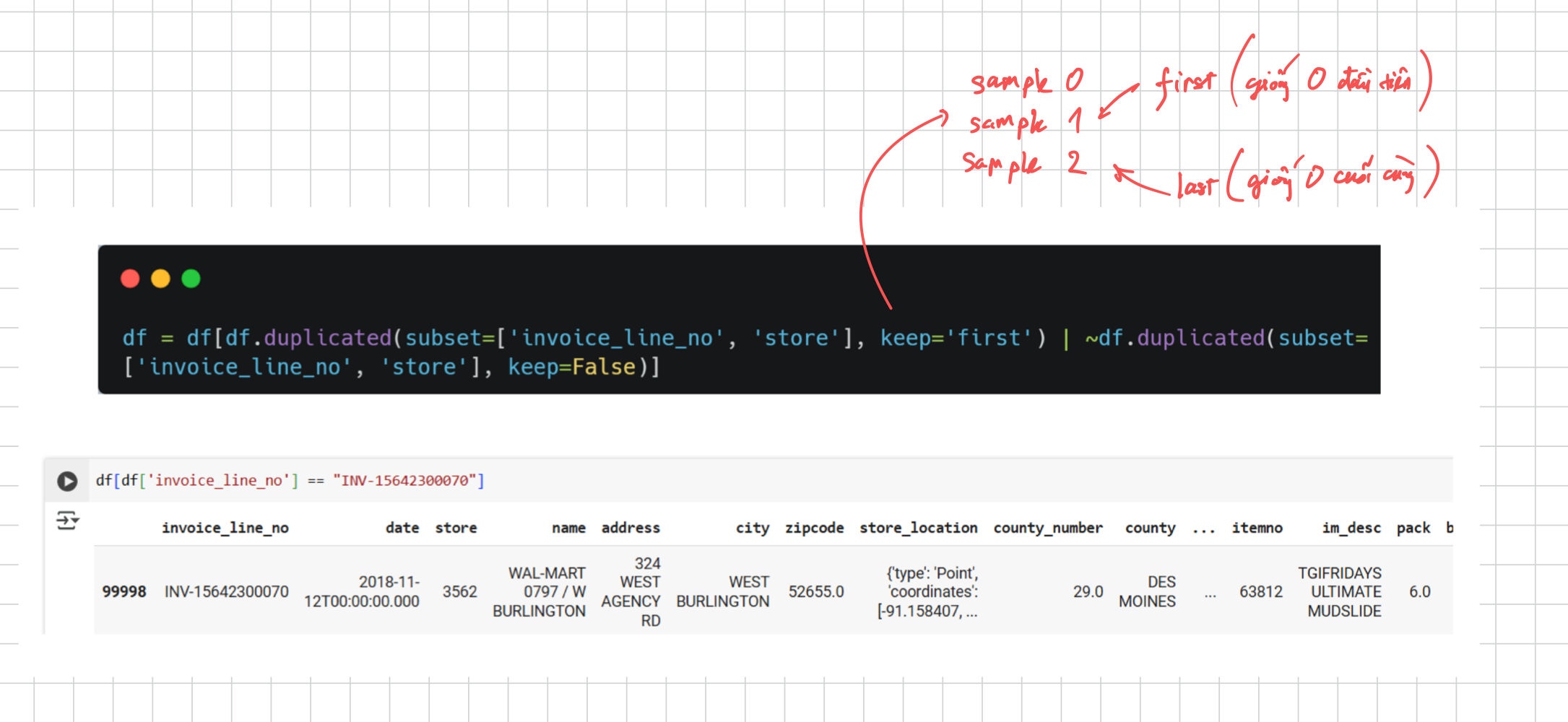
Kinh nghiệm: Đối với đa số trường hợp thì chỉ cần set
keep='last'là được vì thường thì các dữ liệu bản update cuối cùng là bản đúng nhất.
Vậy có phải lúc nào cùng đi tra từng dòng để sửa các lỗi giống như trên không? → Thường thì đây là luồn tư duy xử lý: Column (duyệt xem vấn đề gì) → Problem → Code check (đọc bằng mắt xem lỗi như nào) → Solution
3.2. Hanlde missing data
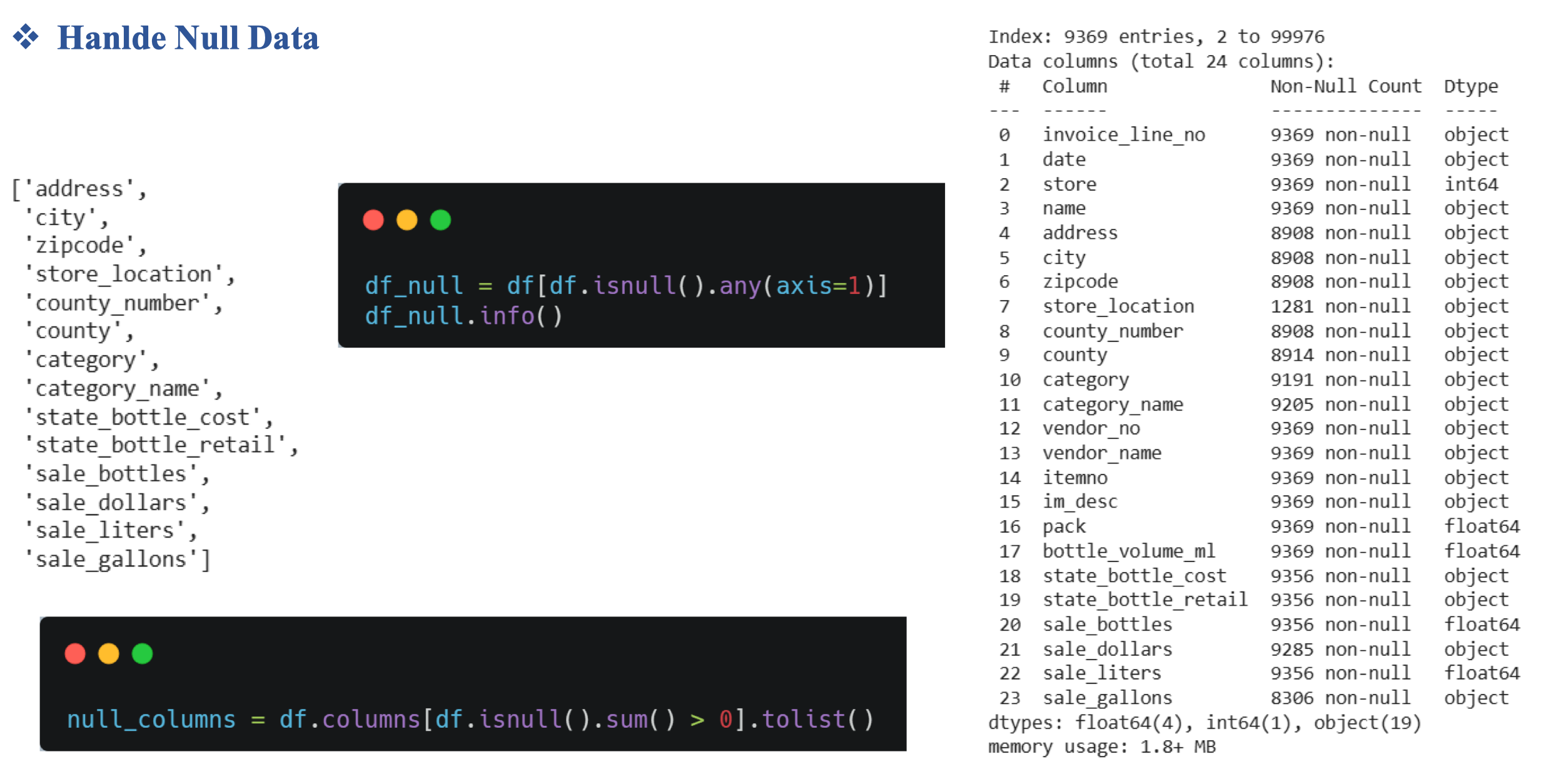
Ví dụ ở đây ta thấy cột store_location null khá nhiều và do nó không quan trọng nên có thể xóa đi luôn
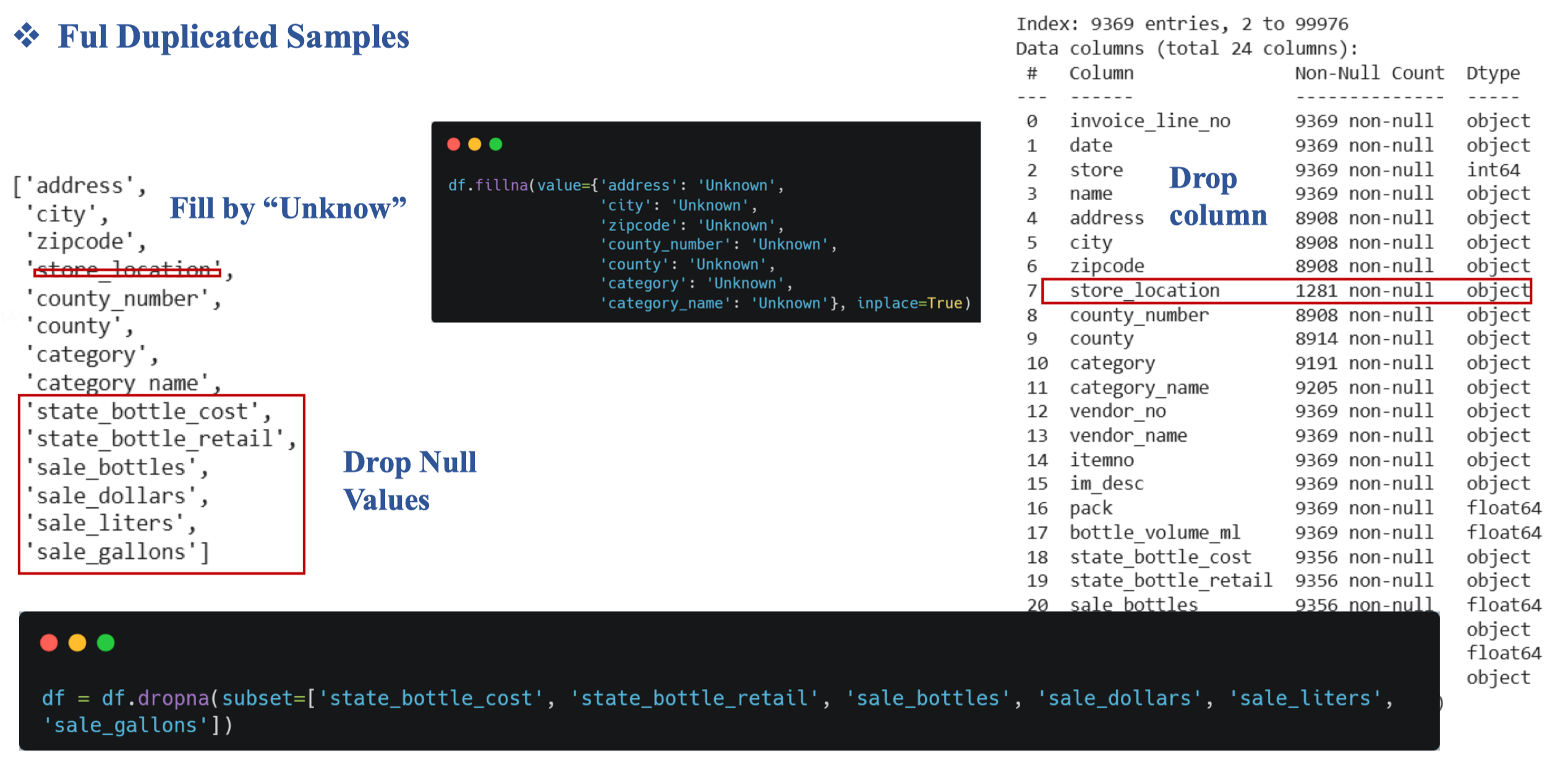
4. Data Loading
Đây là quá trình chuyển từ csv → sql
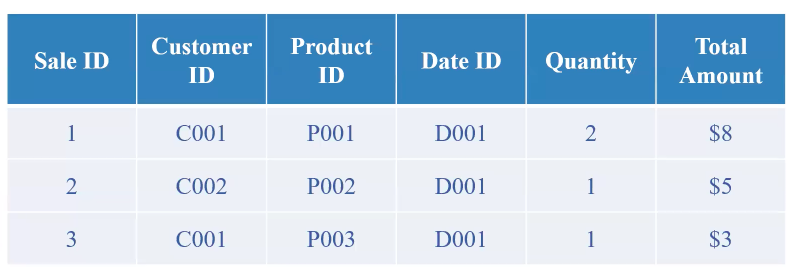
Khái niệm Dimension and Fact Table
Ví dụ:

Ta sẽ chuyển thành Fact Table như sau:
 Fact table sẽ lưu trữ định lượng (quantitative) có thể đo lường về các sự kiện kinh doanh xảy ra.
Các thành phần: Numerical measures và Foreign keys
Fact table sẽ lưu trữ định lượng (quantitative) có thể đo lường về các sự kiện kinh doanh xảy ra.
Các thành phần: Numerical measures và Foreign keys
Đọc thêm: Data cube
Dimension Table:
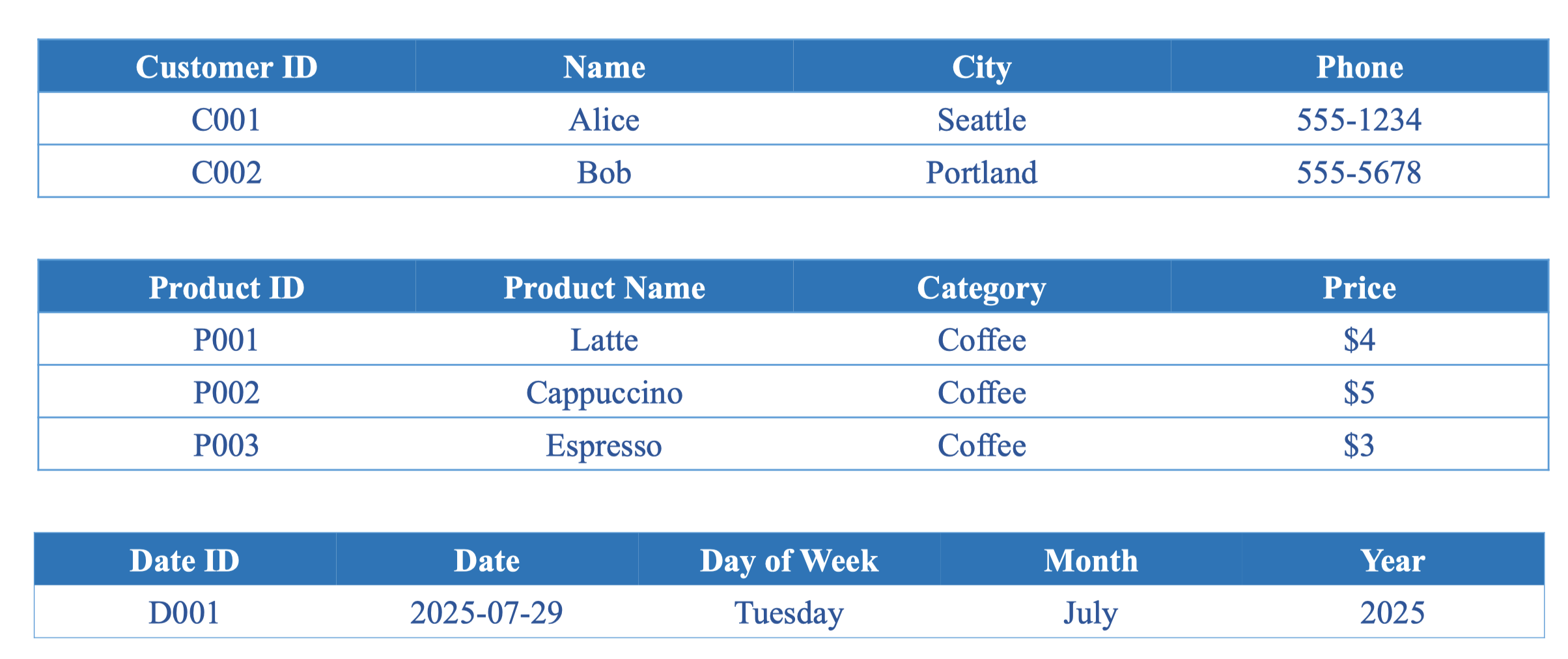 Từ Fact table ta dựa vào khóa ngoại để truy xuất các dữ liệu khác theo Dimension Tables
Định nghĩa: (Dims table) Lưu trữ dữ liệu mô tả về thuộc tính để thêm thông tin cho facts, trả lời cho các câu hỏi ‘who, what, where, when’
Thành phần: Có các cột mô tả, Có primary key, Ít dòng hơn fact tables
Từ Fact table ta dựa vào khóa ngoại để truy xuất các dữ liệu khác theo Dimension Tables
Định nghĩa: (Dims table) Lưu trữ dữ liệu mô tả về thuộc tính để thêm thông tin cho facts, trả lời cho các câu hỏi ‘who, what, where, when’
Thành phần: Có các cột mô tả, Có primary key, Ít dòng hơn fact tables
Lưu ý rằng Data Warehouse khác với Database ở chỗ là Data Warehouse khi chúng ta thực hiện hành động xóa thì thật ra chỉ là soft delete (lưu lại version đó ở một nơi khác) Còn Database xóa là xóa luôn.
Vì vậy khi Loading data vào Warehouse thì thay vì ghi đè thì sẽ là kiểu lưu lại các version khác nhau để tránh việc bị mất dữ liệu lịch sử. Ở đây là các cách lưu trữ version:
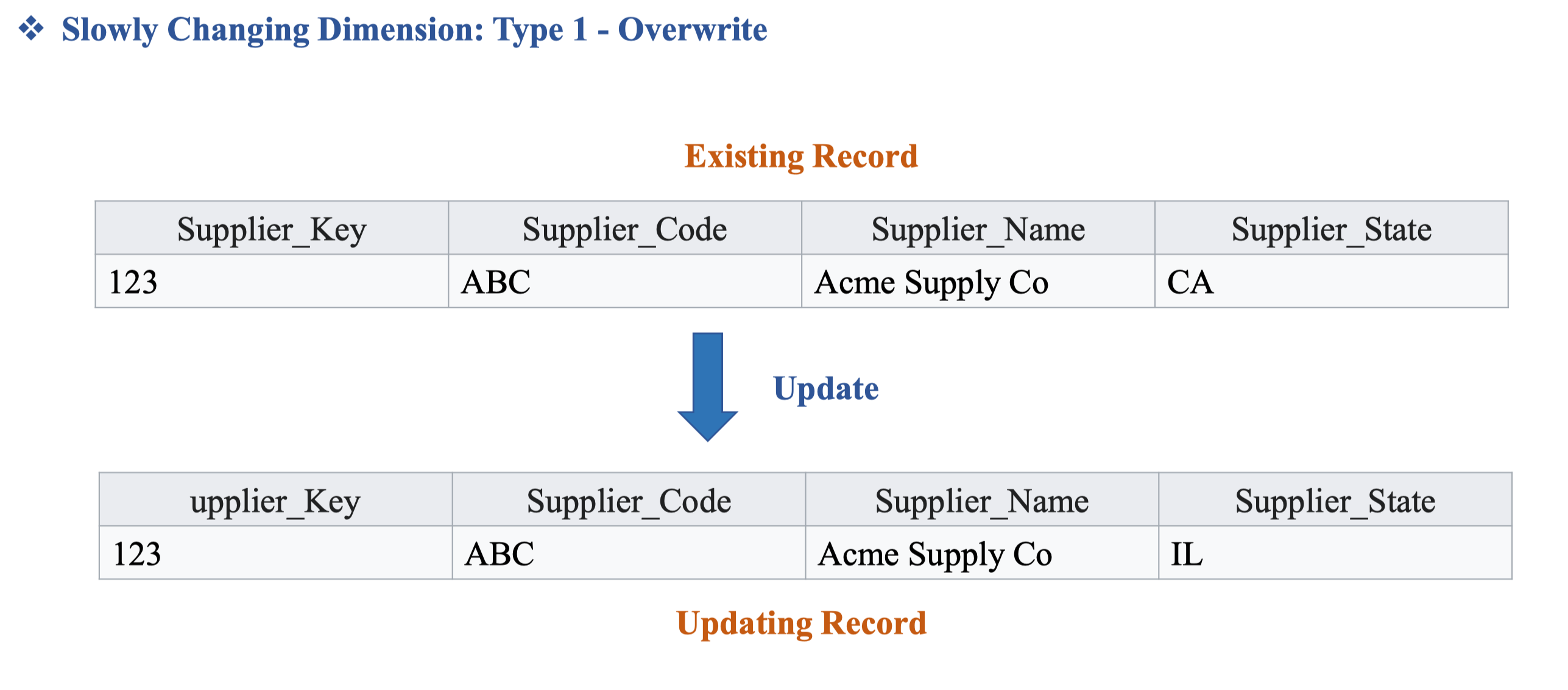
SCD type 1: Ghì đè lên lịch sử cũ. Cách này thật sự không nên làm vì sẽ mất đi lịch sử quá khứ.
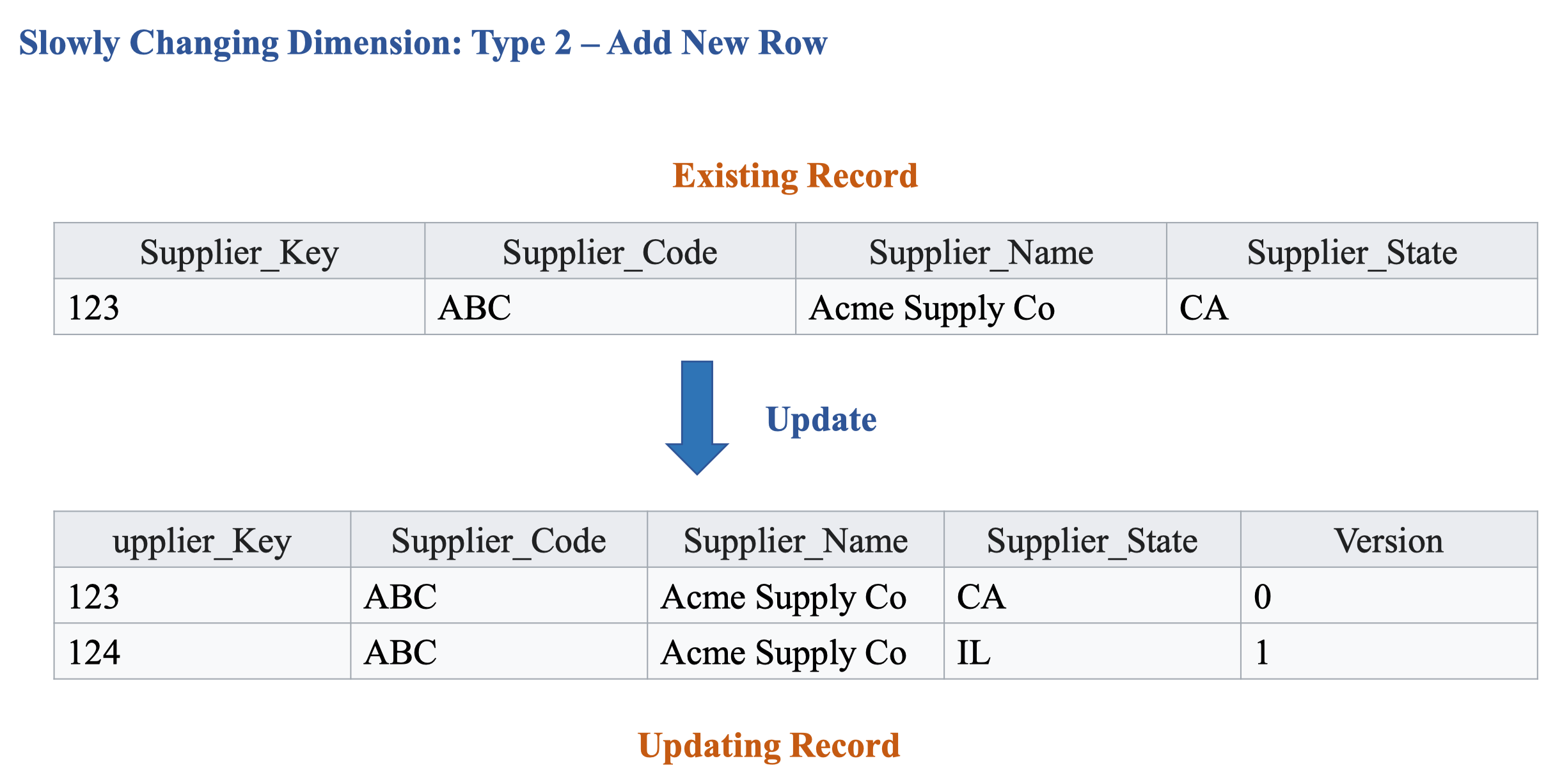
SCD type 2: Lưu lại hai bản dữ liệu cũ và mới. Ưu điểm của cách 2 là sẽ truy vấn lại được dữ liệu lịch sử, ví dụ có thể so sánh được doanh thu tháng này và doanh thu tháng trước. Đây là tính chất quan trọng của Data Warehouse → Có versoning
Vậy cách thực hiện SCD type 2
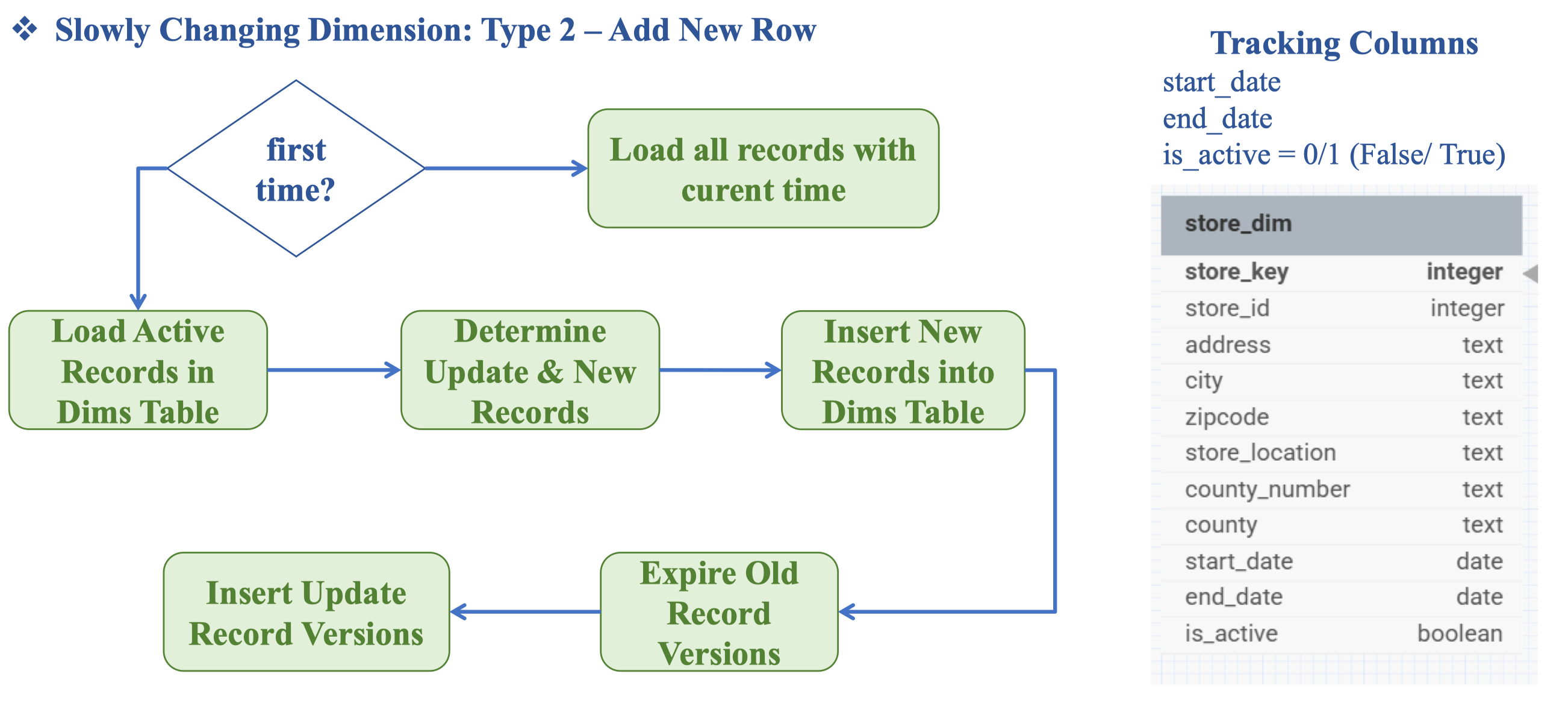
Ta sẽ dùng start_date end_date và is_active để lưu trữ lại version của bảng data đó.
Ở bước Determine Update & New Records ta cần phải xem là dữ liệu đó là New Records (hoàn toàn mới, chưa có) hay là Update (Chỉnh sửa lại dữ liệu cũ).
Sau khi Insert news Records thì ta sẽ Expire Old record bằng cách thêm end_date và tắt is_active.
Vậy sau khi đã lưu trữ data vào Data Warehouse thì tiếp theo là gì?
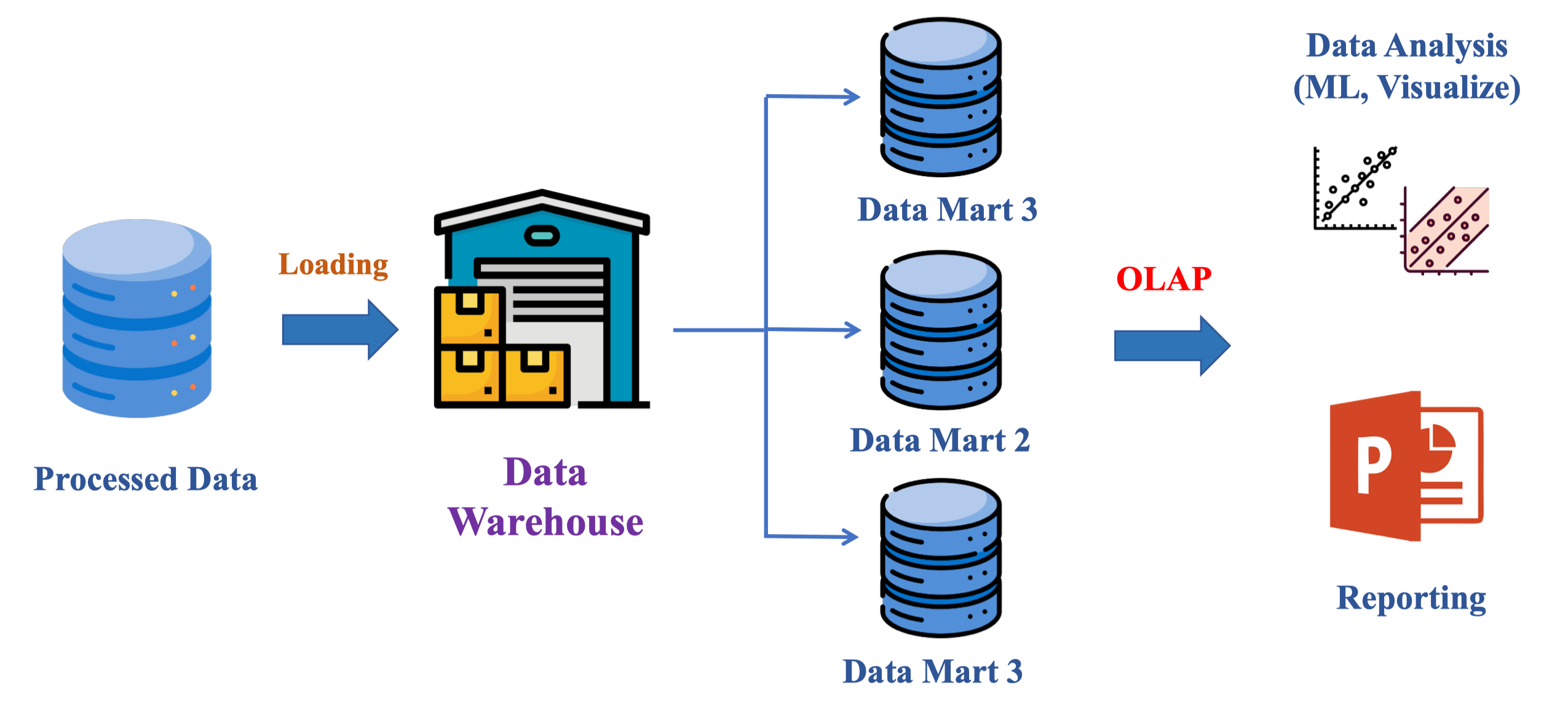
Tiếp theo là Visualize, Dashboard, làm báo cáo. Giới thiệu về Business Intelligence
Quiz
- Một đặc điểm quan trọng của Data Warehouse là gì? → Được tối ưu cho đọc dữ liệu hơn là ghi. Bởi vì …
- Dữ liệu được lưu trong Data Warehouse thường có đặc điểm? → Dữ liệu lịch sử đã được xử lý và chuẩn hóa. Phải là dữ liệu lịch sử vì đã được xử lý, còn dữ liệu realtime sẽ được lưu ở data store.
- Trong bước Transform của ETL, Aggregate thường được sử dụng khi nào? → Khi muốn tóm tắt dữ liệu chi tiết thành dạng tổng hợp theo nhóm. (Sum, Count, Mean theo Group)