Table of Content
Important
Tham khảo
1. Review Decision Tree
Ta biết công thức Gini Impurity (đo mức độ tạp chất) - càng nhỏ thì dữ liệu càng tinh khiết (chỉ có 1 class): Trong đó là tỉ lệ mẫu lớp$$$cSFS_ff$. Trong ví dụ Iris, ta đánh giá mức “tạp” của nút bằng Gini Impurity và chọn phép tách tối ưu theo Gini Gain.
 Ref: https://www.fs.usda.gov/wildflowers/beauty/iris/flower.shtml
Ref: https://www.fs.usda.gov/wildflowers/beauty/iris/flower.shtml
| Sample | Petal_Length | Petal_Width | Sepal_length | Sepal_Width | Label |
|---|---|---|---|---|---|
| 1 | 1.0 | 0.2 | 5.1 | 3.5 | 0 |
| 2 | 1.3 | 0.6 | 4.9 | 3.0 | 0 |
| 3 | 0.9 | 0.7 | 4.7 | 3.2 | 0 |
| 4 | 1.7 | 0.5 | 4.8 | 2.8 | 1 |
| 5 | 1.8 | 0.9 | 6.6 | 3.3 | 1 |
| 6 | 1.2 | 1.3 | 5.2 | 2.4 | 1 |
| ![[image 1 37.png | image 1 37.png]] | ||||
| ![[image 2 35.png | image 2 35.png]] | ||||
| Bước 0 — Nút gốc | |||||
| Đầu tiên chúng ta có 6 sample và value theo từng Label là ⇒ | |||||
| Tính Gini Impurity ở đây: | |||||
| Bước 1 — Chọn ngưỡng đầu x[0] ≤ 1.1 |
- Nhánh True (≤ 1.1):
samples = 2,value = [2, 0]⇒ (lá thuần Class 0). - Nhánh False (> 1.1):
samples = 4,value = [1, 3]⇒ - Gini sau tách (trọng số):
- Gini Gain tại gốc: (giá trị 1.1 là tốt nhất để phân chia)
→ Tách này là “đáng giá”: một nhánh đã sạch hoàn toàn.
Bước 2 — Tách tiếp nhánh phải theo x[0] ≤ 1.5
(đang ở nút
samples = 4,value = [1,3],gini = 0.375) - Nhánh True (≤ 1.5):
samples = 2,value = [1,1]⇒ - Nhánh False (> 1.5):
samples = 2,value = [0,2]⇒ (lá thuần Class 1). - Gini sau tách (trọng số):
- Gini Gain tại nút con:
Code IRIS-2D:
Load dữ liệu:
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
import pandas as pd
# load data
data = pd.read_csv('iris_2D.csv')
# get x
x_data = data[['Petal_Length', 'Petal_Width']]
print(x_data)
y_data = data['Label'].astype(int)
print(y_data)Cài đặt decision tree:
Petal_Length Petal_Width
0 1.0 0.2
1 1.3 0.6
2 0.9 0.7
3 1.7 0.5
4 1.8 0.9
5 1.2 1.3
0 0
1 0
2 0
3 1
4 1
5 1
Name: Label, dtype: int64# DecisionTreeClassifier
dt_classifier = DecisionTreeClassifier(max_depth=2, criterion='gini')
dt_classifier.fit(x_data.values, y_data.values)max_depth=2: Độ sâu tối đa của cây là 2criterion='gini': Phân loại dựa trên đánh giágini(hoặc có thể dùngentropy)fit(x_data.values, y_data.values): train dữ liệu, đưa dữ liệu vào. Minh họa sau khi train**dt_classifier**:
from sklearn import tree
plt.figure(figsize=(10, 3))
tree.plot_tree(dt_classifier)
plt.show()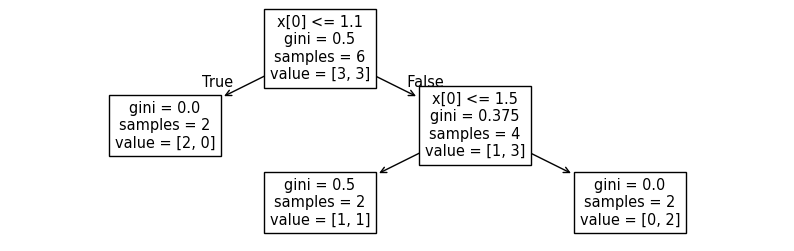 Minh họa bằng dtreeviz:
Minh họa bằng dtreeviz:
import dtreeviz
viz_model = dtreeviz.model(
dt_classifier,
X_train=x_data,
y_train=y_data,
feature_names=['Petal_Length', 'Petal_Width'],
target_name='Label',
)
viz_model.view()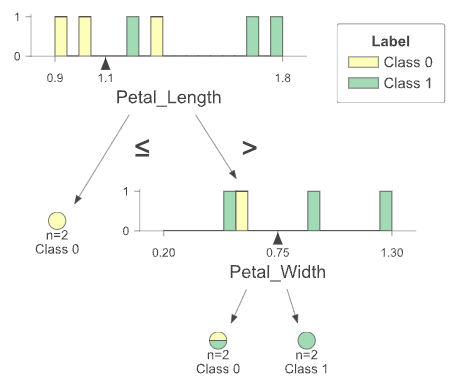
Code: IRIS-3D
Load dữ liệu
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
import pandas as pd
# load data
data = pd.read_csv('iris_3D.csv')
# get x
x_data = data[['Petal_Length', 'Petal_Width', 'Sepal_Length']]
print(x_data)
y_data = data['Label'].astype(int)
print(y_data)Petal_Length Petal_Width Sepal_Length
0 1.0 0.2 5.1
1 1.3 0.6 4.9
2 0.9 0.7 4.7
3 1.7 0.5 4.8
4 1.8 0.9 6.6
5 1.2 1.3 5.2
0 0
1 0
2 0
3 1
4 1
5 1
Name: Label, dtype: int64- Ở đây có thêm cột là
Sepal_LengthCài đặt Decision Tree:
dt_classifier = DecisionTreeClassifier(max_depth=2, criterion='gini')
dt_classifier.fit(x_data.values, y_data.values)- Vẫn như cũ Minh họa cây
from sklearn import tree
plt.figure(figsize=(10, 3))
tree.plot_tree(dt_classifier)
plt.show()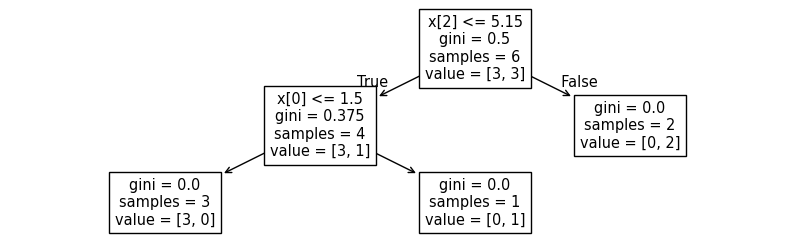
import dtreeviz
viz_model = dtreeviz.model(
dt_classifier,
X_train=x_data,
y_train=y_data,
feature_names=['Petal_Length', 'Petal_Width', 'Sepal_Length'],
target_name='Label',
)
viz_model.view()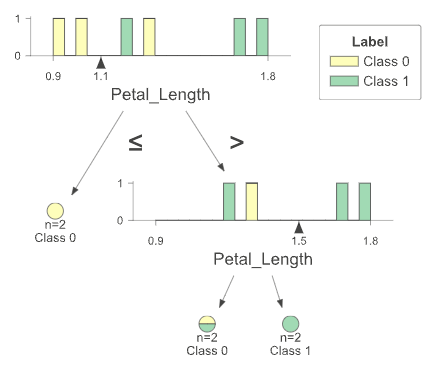
Vấn đề đặt ra
- Ở đây chúng ta từ 2 cột data (feature) tăng lên thành 3 cột nhưng thuật toán vẫn dùng feature Petal Length để phân loại dữ liệu → Từ đó dẫn đến là không sử dụng triệt để các data khác để xử lý bài toán.
- Mở rộng ra khi dữ liệu bảng có nhiều feature hơn thì việc khai thác hết tất cả các dữ liệu là điều hợp lý và tránh được lỗi tiềm tàn và có thể là overfitting như decision tree.
2. Random Forest
Trong thực tế, một cây quyết định đơn lẻ thường quá khớp và nhạy cảm với dữ liệu huấn luyện. Ý tưởng cốt lõi của Ensemble là “nếu 1 cây chưa tốt, hãy dùng nhiều cây và tổng hợp kết quả”. Việc bình quân hóa (averaging)/ bỏ phiếu đa số (majority vote) giúp giảm phương sai của mô hình mà không làm tăng quá nhiều độ chệch.
Ensemble Learning
Ensemble Learning là kỹ thuật kết hợp dự đoán từ nhiều mô hình thành phần (base learners) để tạo ra dự đoán chính xác và vững hơn so với từng mô hình riêng lẻ. Trong ngữ cảnh ở đây, các mô hình thành phần là Decision Trees (như hình minh họa).
Random Forest
Random Forest là thuật toán supervised learning sử dụng nhiều Decision Trees huấn luyện theo cơ chế bagging + lấy mẫu đặc trưng ngẫu nhiên (feature subsampling), sau đó gộp dự đoán để cho ra một kết quả cuối cùng. Mô hình áp dụng được cho cả phân lớp lẫn hồi quy.
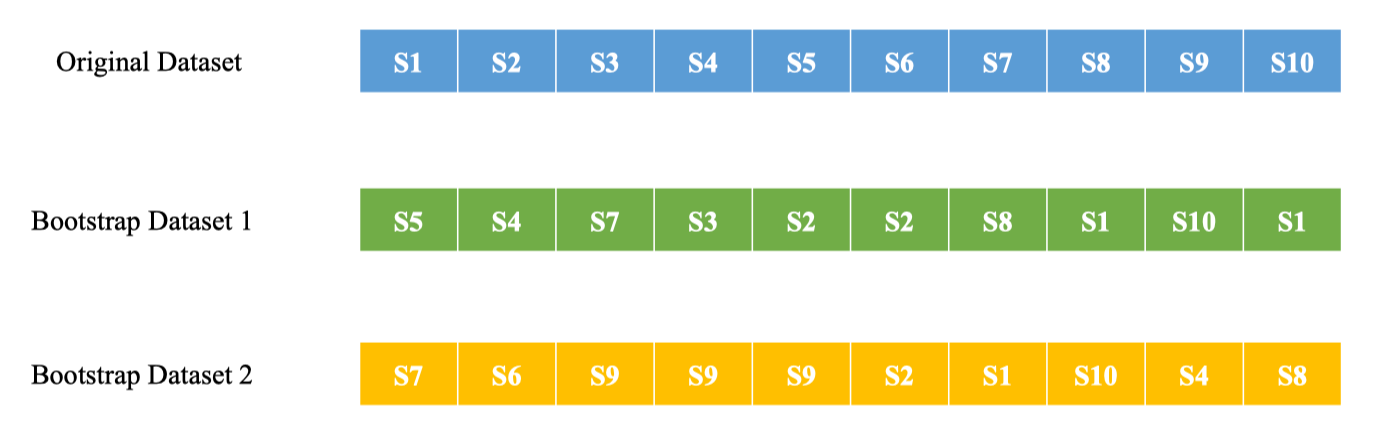
Bootstrapping
Chọn ngẫu nhiên sample
Bootstrapping là lấy mẫu ngẫu nhiên có hoàn lại (random sampling with replacement) từ tập gốc để tạo ra tập con có cùng kích thước N cho mỗi cây.
Do có hoàn lại, mẫu có thể lặp lại và một số phần tử không xuất hiện trong tập con này (gọi là Out-of-Bag – OOB đối với cây đó).
 Chọn ngẫu nhiên Feature
Ngoài việc lấy ngẫu nhiên dữ liệu mẫu, RF còn lấy ngẫu nhiên các Feature.
Chọn ngẫu nhiên Feature
Ngoài việc lấy ngẫu nhiên dữ liệu mẫu, RF còn lấy ngẫu nhiên các Feature.
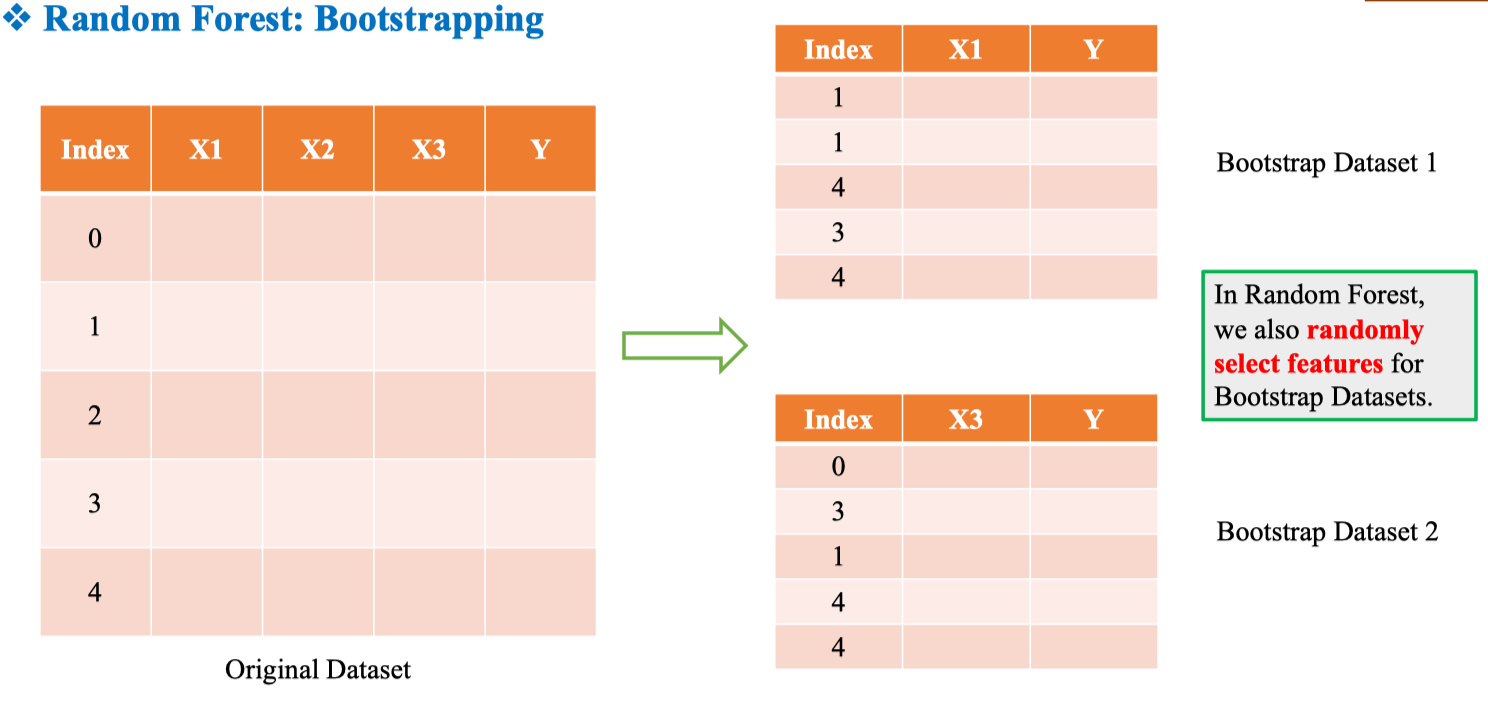
⇒ Điều này làm các cây ít tương quan hơn, nhờ đó mô hình tổng hợp ổn định và giảm phương sai.
Aggregating
Sau khi huấn luyện n cây trên các bootstrap dataset, Random Forest sẽ gộp dự đoán của từng cây để ra kết quả cuối cùng cho một điểm dữ liệu .
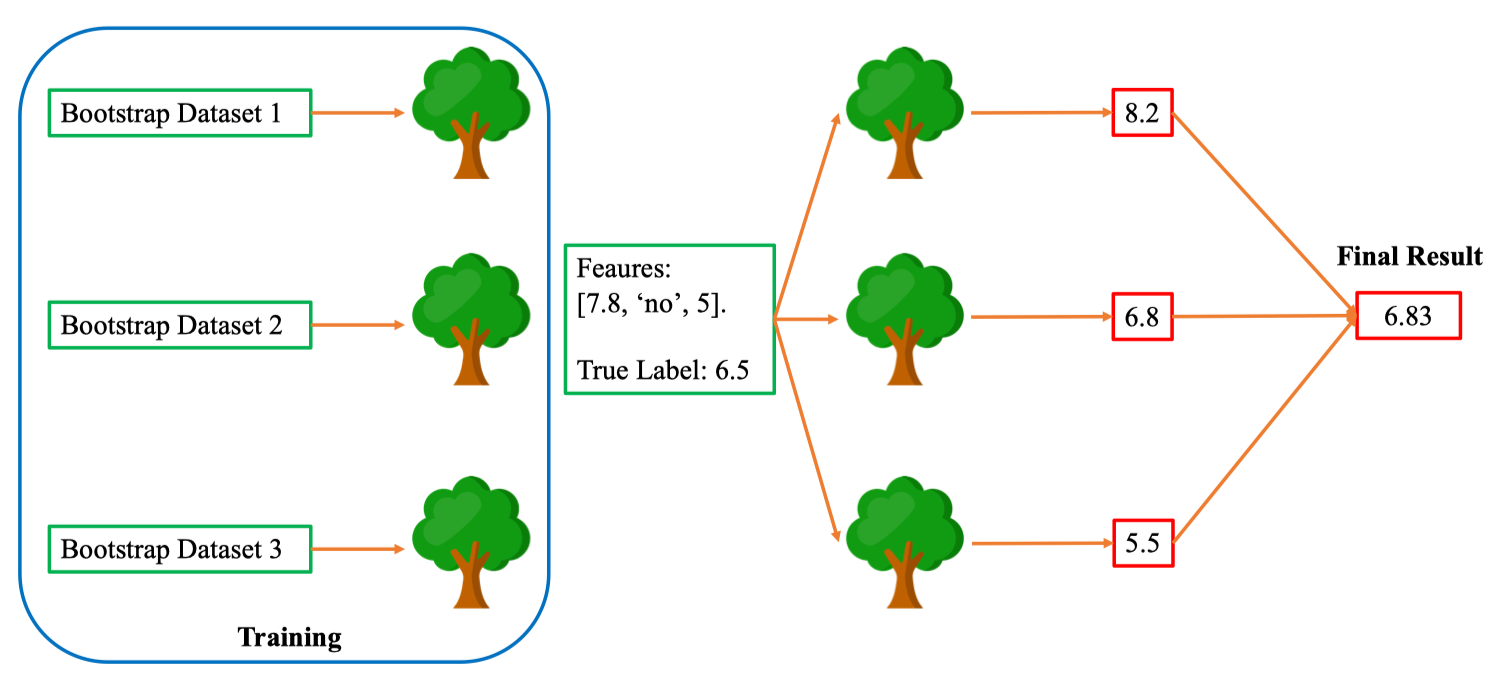 Ví dụ: với điểm có features [7.8, “no”, 5] và nhãn thật , ba cây lần lượt dự đoán 8.2; 6.8; 5.5.
Kết quả gộp:
Ví dụ: với điểm có features [7.8, “no”, 5] và nhãn thật , ba cây lần lượt dự đoán 8.2; 6.8; 5.5.
Kết quả gộp:
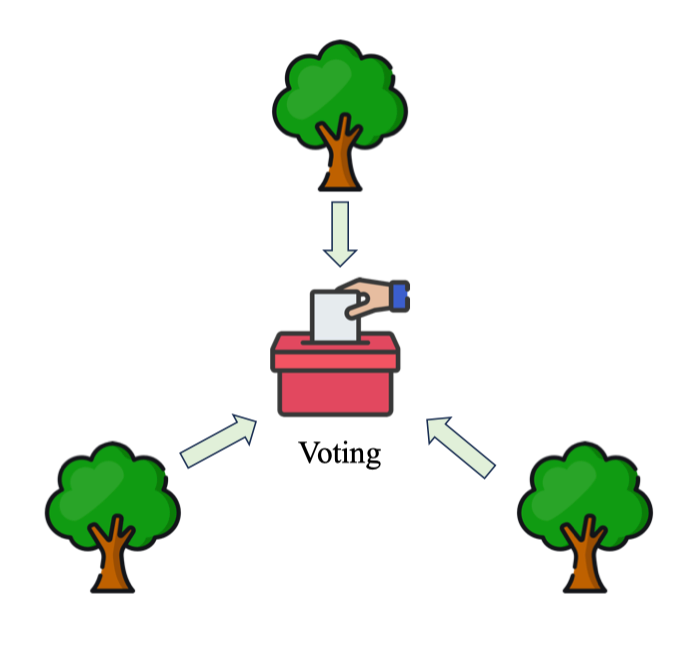
Aggregating: Classification vs Regression
Trong Random Forest, cách gộp dự đoán khác nhau tùy bài toán: Phân lớp (Classification) – Voting
- Hard vote (phổ biến): mô hình chọn nhãn xuất hiện nhiều nhất trong các cây.
- Soft vote: trung bình xác suất các lớp rồi chọn lớp có xác suất lớn nhất. Thường ổn định hơn khi lớp mất cân bằng.
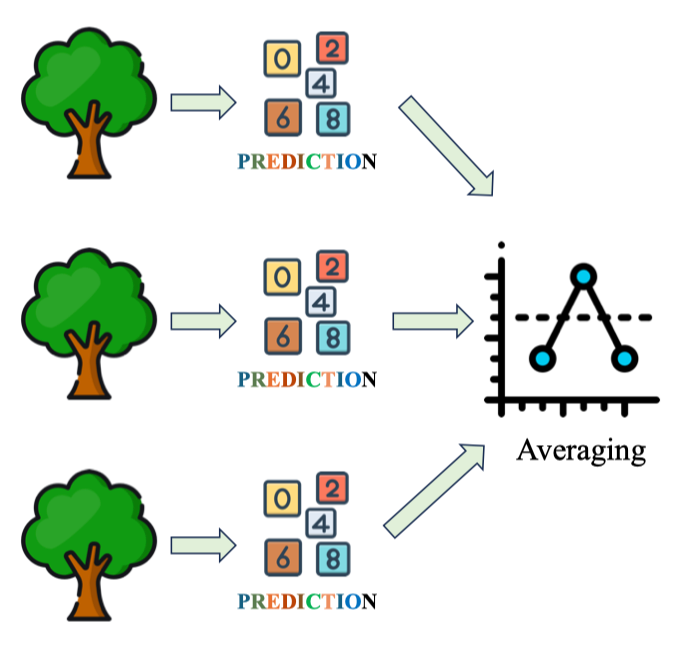
 Hồi quy (Regression) – Averaging
Hồi quy (Regression) – Averaging - Trung bình dự đoán số thực từ các cây.
- Có thể gán trọng số theo chất lượng từng cây (ví dụ OOB):
2.1. Classification
Simple IRIS
Ta dùng 2 thuộc tính Petal_Length và Petal_Width để dự đoán Label ∈ {0,1}.
| Petal_Length | Petal_Width | Label |
|---|---|---|
| 1.0 | 0.2 | 0 |
| 1.3 | 0.6 | 0 |
| 0.9 | 0.7 | 0 |
| 1.7 | 0.5 | 1 |
| 1.8 | 0.9 | 1 |
| 1.2 | 1.3 | 1 |
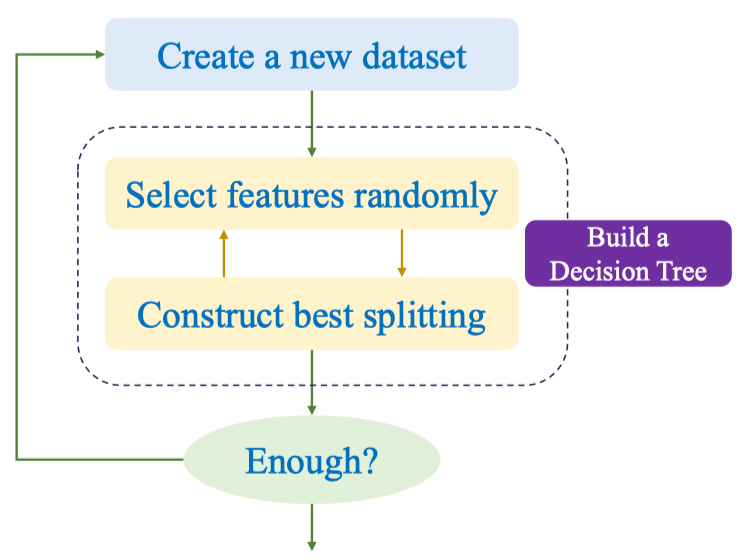
| Quy trình huấn luyện một cây trong Random Forest (classification): |
-
Create a new dataset: lấy bootstrap từ tập gốc (lấy mẫu có hoàn lại).
-
Select features randomly: tại mỗi nút, chọn ngẫu nhiên m đặc trưng (ở đây từ {Petal_Length, Petal_Width}).
-
Construct best splitting: tìm ngưỡng tách tối ưu theo tiêu chí impurity (ví dụ Gini hoặc Entropy).
Gini tại nút:
Thông tin (Entropy):
Chọn split làm giảm impurity nhiều nhất (Information Gain / Gini decrease).
-
Build a Decision Tree: lặp đến khi thỏa tiêu chí dừng (độ sâu, số mẫu tối thiểu…).
-
Enough? Không — lặp lại cho nhiều bootstrap ⇒ n cây; dự đoán dùng voting (hard/soft).
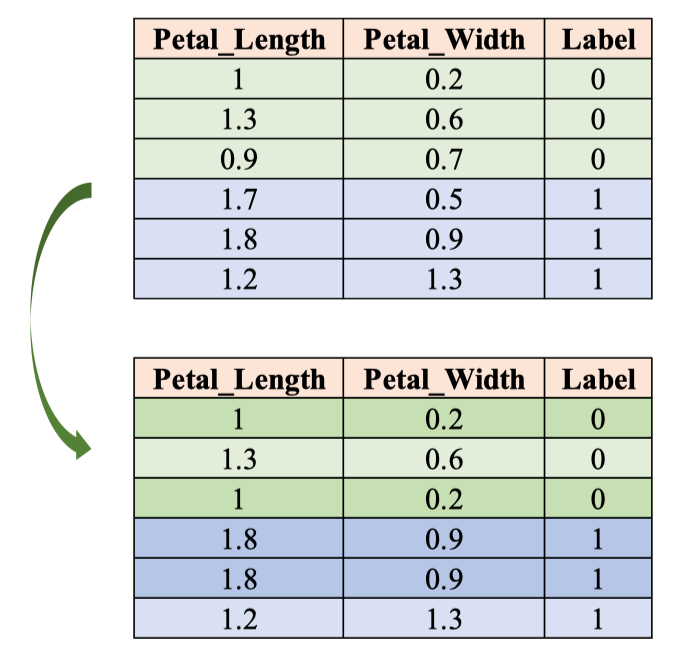
Bước 1 + 2 – Tạo bootstrap dataset & chọn đặc trưng ngẫu nhiên (IRIS)
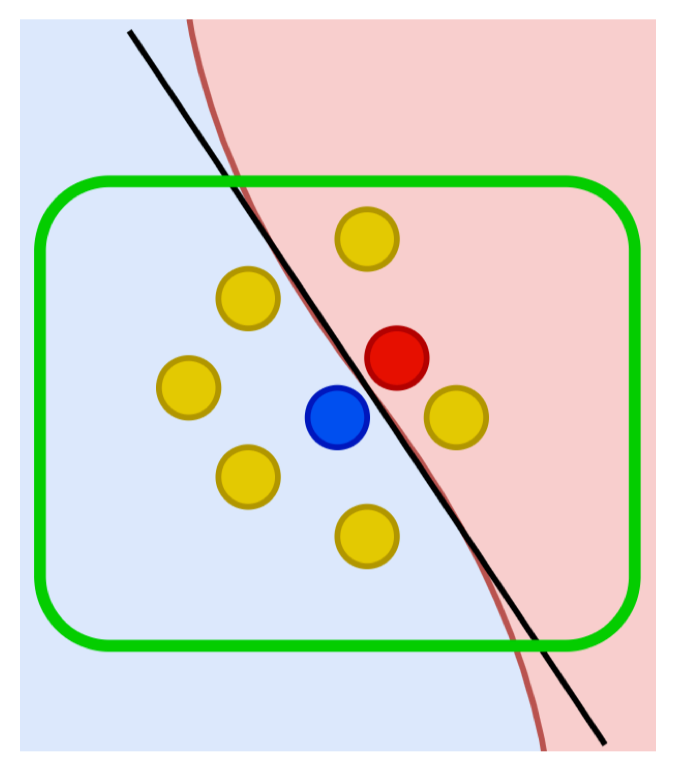
Ta rút mẫu có hoàn lại từ tập gốc để tạo một bootstrap dataset rồi chọn ngẫu nhiên một tập con đặc trưng cho cây hiện tại.
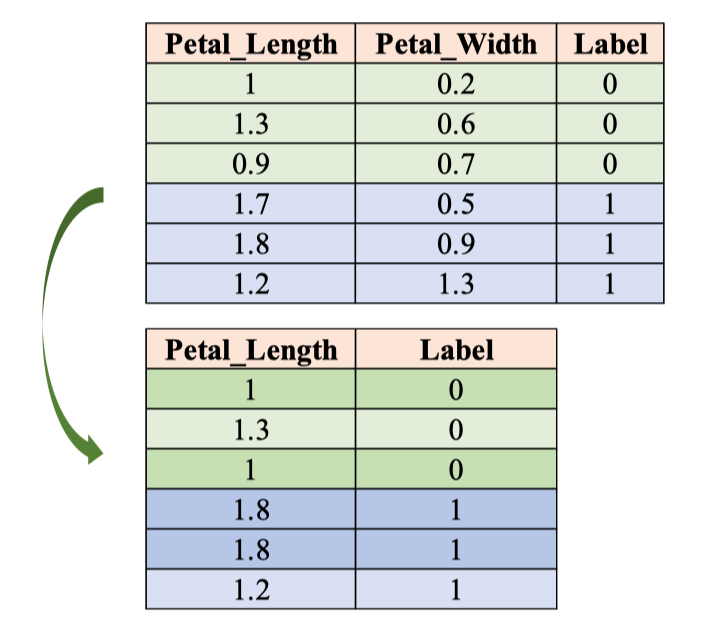
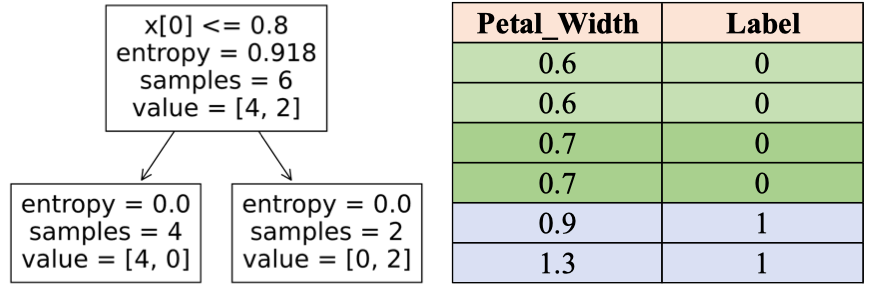
 Ví dụ trên IRIS rút gọn với hai thuộc tính Petal_Length và Petal_Width, cây này ngẫu nhiên chỉ dùng Petal_Length để học ranh giới.
Ví dụ trên IRIS rút gọn với hai thuộc tính Petal_Length và Petal_Width, cây này ngẫu nhiên chỉ dùng Petal_Length để học ranh giới.
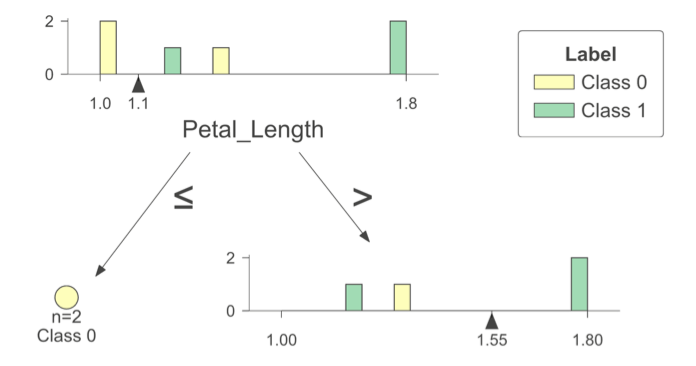
Bước 3 - Construct best splitting
Histogram cho thấy các điểm tách thử nghiệm tại 1.10 và 1.55; cây được xây bằng cách chọn ngưỡng làm giảm độ hỗn loạn (impurity) lớn nhất theo Entropy.
- Nút gốc: 6 mẫu, ⇒
- Tách 1: ngưỡng
- trái : (H = 0.0)
- phải : (H ≈ 0.811).
- Entropy sau tách
- Tách 2 (nhánh phải): ngưỡng
- trái : (H = 1.0),
- phải : (H = 0.0).
- Entropy sau tách =
 Kết quả: cây có ba lá, trong đó hai lá thuần (pure), một lá còn hỗn hợp do dữ liệu ít.
Kết quả: cây có ba lá, trong đó hai lá thuần (pure), một lá còn hỗn hợp do dữ liệu ít.
Bước 4: Lặp lại tiếp tục
Create a new dataset
 Select features randomly
Select features randomly
 Construct best splitting
Construct best splitting
Inference
Petal_Length = 1.7
Petal_Width = 0.8
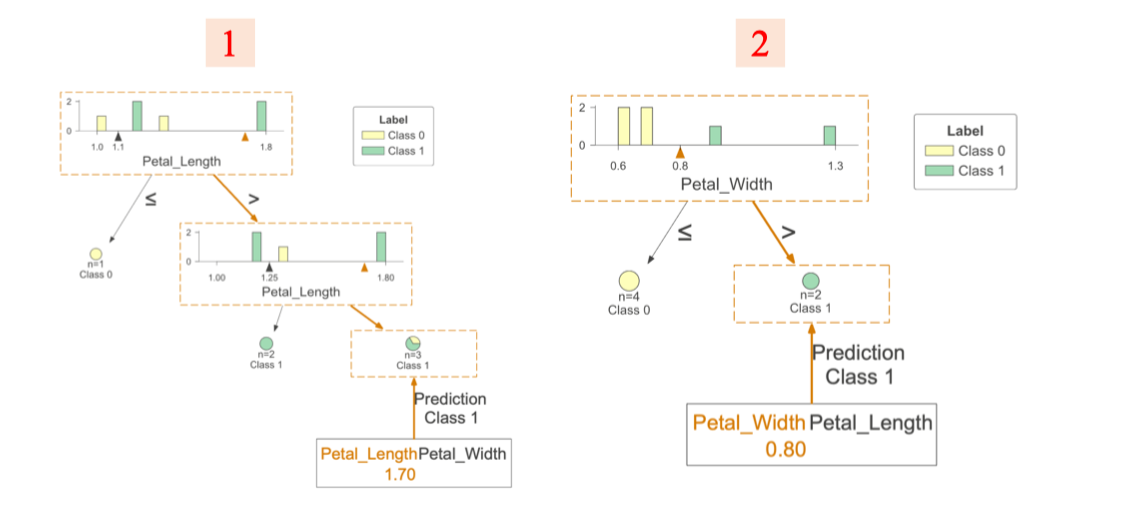 ⇒ Class 1
⇒ Class 1
3. Step-by-step Example
Dataset
Sử dụng Random Forest cho phân lớp với dữ liệu sunburn gồm các thuộc tính nhân khẩu học và việc dùng kem chống nắng để dự đoán Kết quả (bị cháy nắng hay không). Tất cả đặc trưng đều là categorical. Bảng dữ liệu:
| ID | Màu tóc | Chiều cao | Cân nặng | Dùng kem | Kết quả |
|---|---|---|---|---|---|
| 1 | Đen | Trung bình | Nhẹ | Không | Cháy nắng |
| 2 | Đen | Cao | Trung bình | Có | Không |
| 3 | Rám | Thấp | Trung bình | Có | Không |
| 4 | Nâu | Thấp | Trung bình | Không | Cháy nắng |
| 5 | Nâu | Trung bình | Nặng | Không | Cháy nắng |
| 6 | Rám | Trung bình | Nặng | Có | Không |
| 7 | Nâu | Trung bình | Nhẹ | Có | ? |
| Kiểu dữ liệu & miền giá trị: |
- Màu tóc (Categorical): Đen, Nâu, Rám
- Chiều cao (Categorical): Thấp, Trung bình, Cao
- Cân nặng (Categorical): Nhẹ, Trung bình, Nặng
- Dùng kem (Categorical): Có, Không
- Kết quả (Categorical – Target): Cháy nắng, Không
Problem
Bài toán: Binary Classification — dự đoán nhãn “Cháy nắng” hoặc “Không cháy nắng” từ các đặc trưng categorical (màu tóc, chiều cao, cân nặng, dùng kem). Mục tiêu: xây một “rừng” nhỏ để minh hoạ cơ chế bagging + random feature. Siêu tham số:
- Kích thước rừng: Decision Trees (mỗi cây học trên bootstrap dataset khác nhau).
- Số đặc trưng xét tại mỗi nút: (mỗi lần tách, chỉ chọn ngẫu nhiên 2 feature để tìm split tốt nhất). Cách hoạt động tóm tắt: Với mỗi cây :
- (1) tạo bootstrap từ tập gốc,
- (2) ở mỗi nút chỉ xét đặc trưng ngẫu nhiên
- (3) chọn ngưỡng tách làm giảm impurity (Gini/Entropy) lớn nhất,
- (4) lặp đến khi đạt tiêu chí dừng. Khi dự đoán, gộp kết quả:
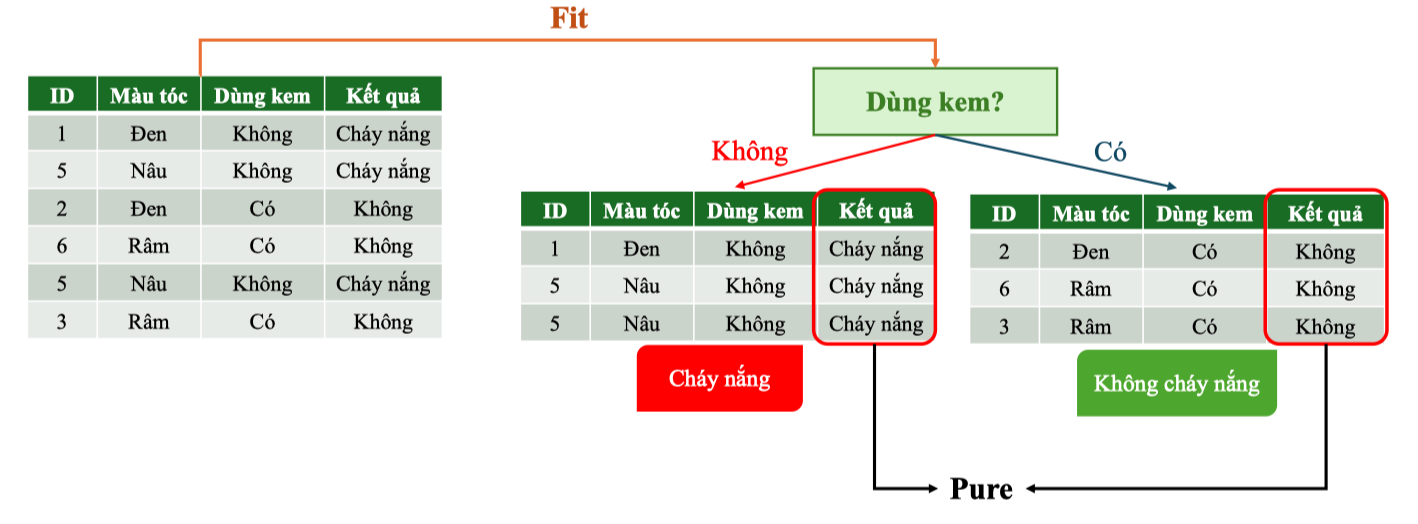
Bootstrap Sampling (Bagging)
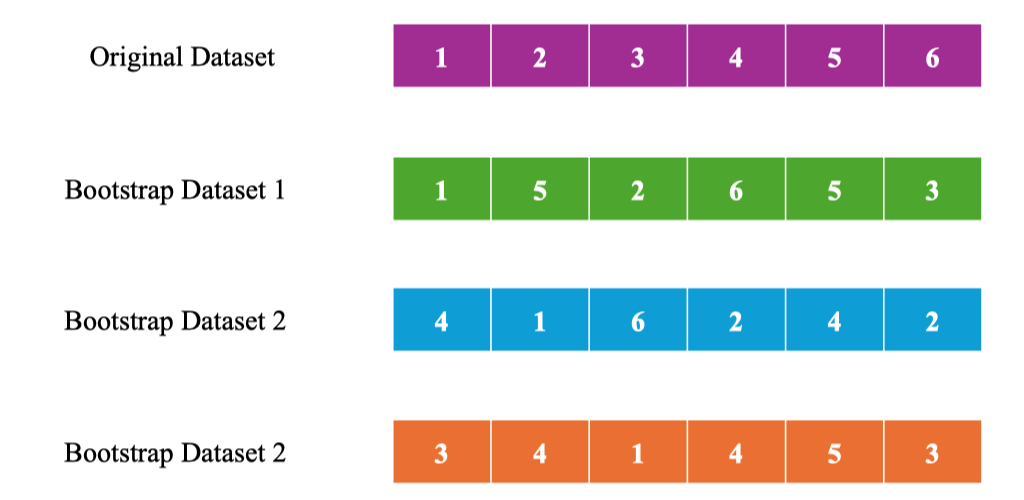
Build Decision Trees: Tree 1 on Bootstrap Dataset 1
Split 1. Randomly select two features: Màu tóc, Dùng kem
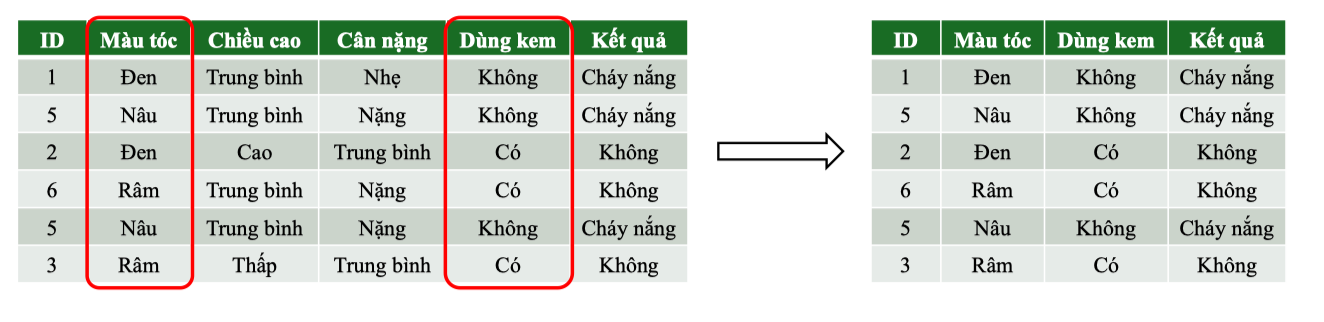 Tính tại nút gốc : ,
Tiếp theo, thử Tính cho Màu tóc:
Tính tại nút gốc : ,
Tiếp theo, thử Tính cho Màu tóc:
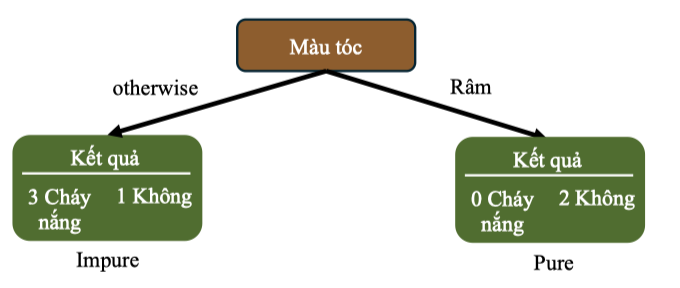
-
Nhánh Rám: 2 mẫu đều Không ⇒ G(Rám) = 0
-
Nhánh khác (Đen/Nâu): 4 mẫu với tỉ lệ Không, Cháy nắng ⇒
-
Gộp trọng số:
-
Gini Gain:
Tính Gini Gain cho Dùng kem:
-
Vì cả hai nhánh đều thuần:
-
Gini Gain:
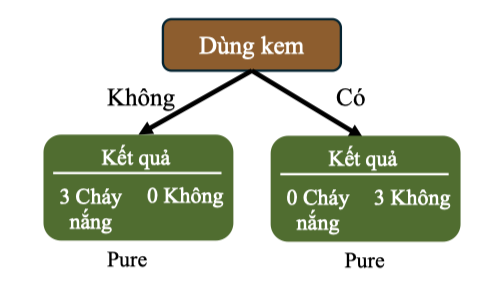 ⇒ Dùng kem cho gain lớn nhất (so với “Màu tóc” chỉ 0.25), nên được chọn làm Split 1.
⇒ Dùng kem cho gain lớn nhất (so với “Màu tóc” chỉ 0.25), nên được chọn làm Split 1.