1. What is an Interpretability
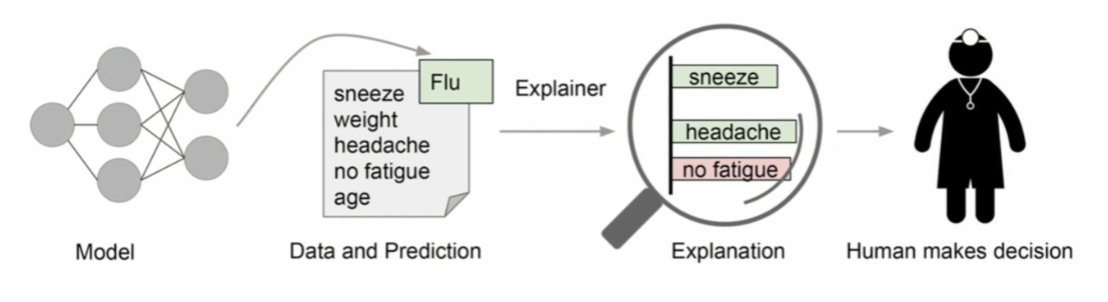
1.1. Overview of Explainable AI
Mô hình AI cần phải giải thích được rõ ràng để cho người dùng tin tưởng vào nó.
Quote
Chip Huyen
Tất cả các lĩnh vực đều cần XAI để cải thiện hiệu suất.
Transparency:
- Model transparency: Có thể giải thích rõ ràng các thành phần bên trong của model không (weight, features and decision rules)
- Process transparency: Liệu chúng ta có nắm rõ được quy trình cách mà data được thu thập, xử lý và dùng để đưa ra quyết định?
- Decision transparency: Liệu người dùng có thể hiểu được cách mà AI đưa ra quyết định?
Interpretability:
- Nếu tính transparency là việc chúng ta nhìn thấy được cách mô hình đưa ra output thì Interpretability là khả năng giải thích được tại sao là quy trình đó, tại sao lại dùng thành phần này.
- Lúc này khi ta hiểu được quy trình thì ta mới cải tiến được model.
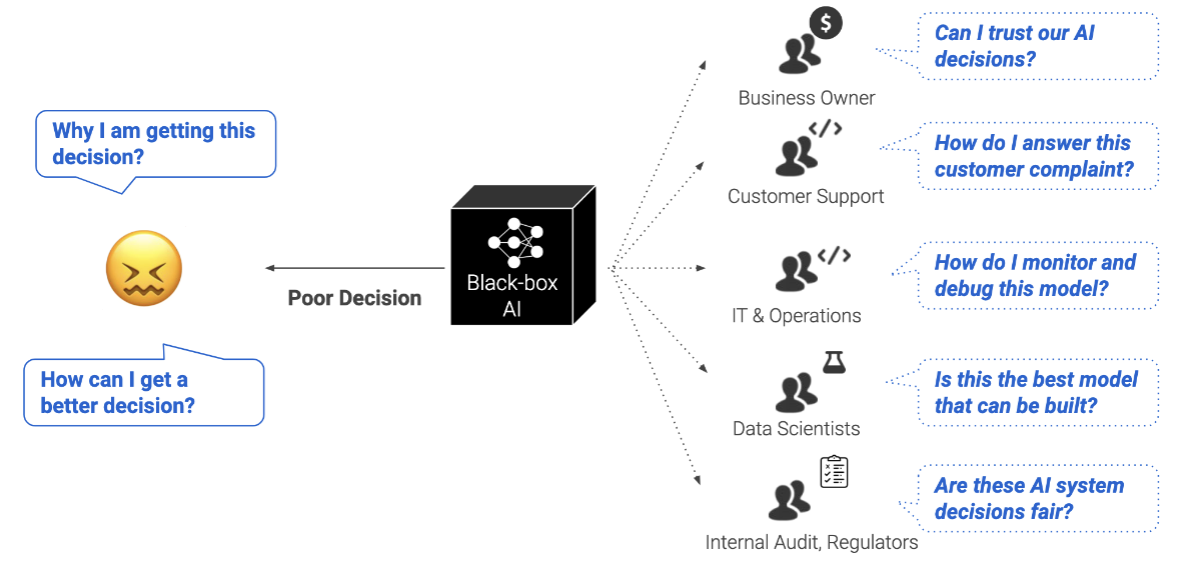
1.2. Why is Interpretability Needed?
The AI Black Box Problem
Đây là sơ đồ cho thấy độ phức tạp của mô hình so với tính có thể giải thích thì mô hình càng phức tạp thì interpretability càng thấp
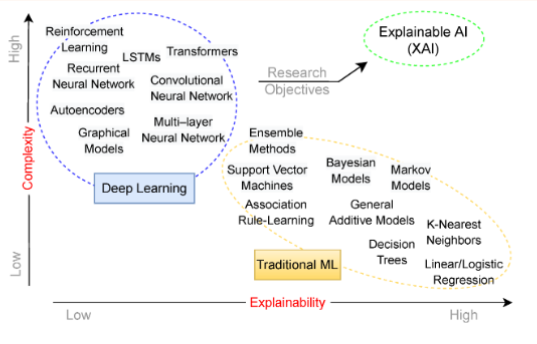
Tuy là khó khăn nhưng chúng ta cần phải giải thích được mô hình để thuận lợi trong việc phát triển và feedback đầu ra của mô hình:
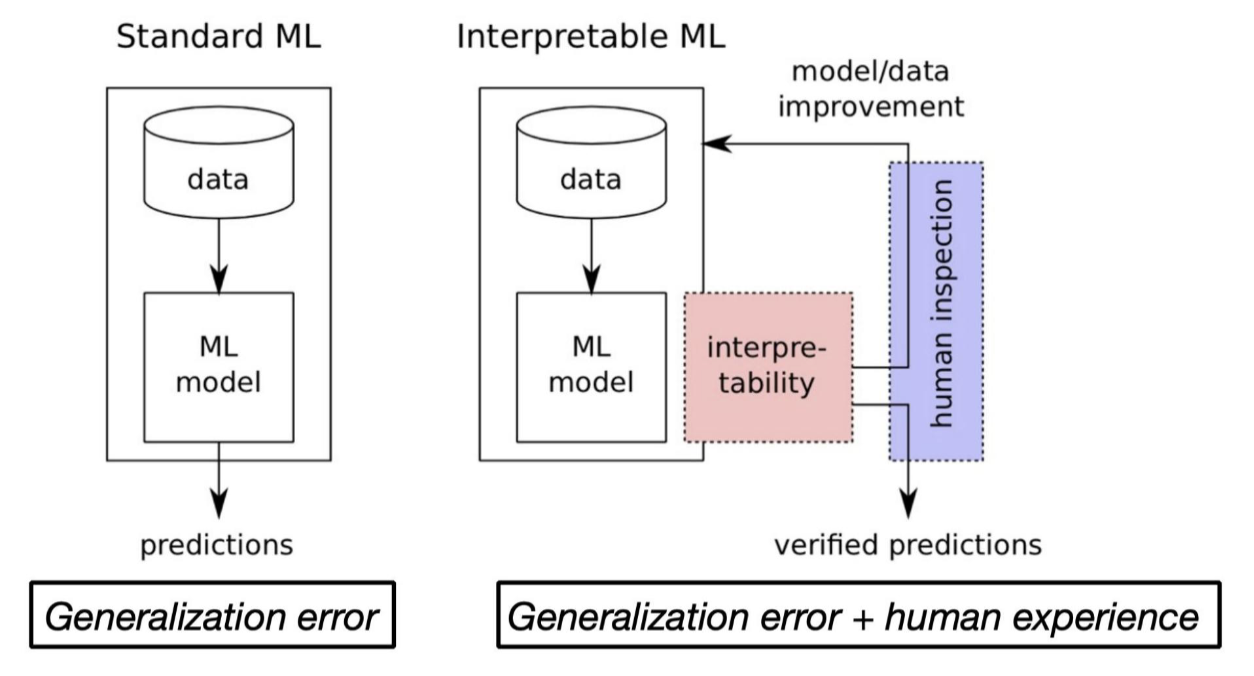
1.3. Intrinsic vs Post-hoc
| Tiêu chí | Intrinsic | Post-hoc (hậu nghiệm) |
|---|---|---|
| Định nghĩa | Là cách thiết kế mô hình tự thân đã dễ hiểu, tức là bản chất mô hình có thể giải thích được mà không cần thêm bước giải thích bên ngoài. | Áp dụng các phương pháp giải thích bên ngoài cho mô hình hộp đen (black-box), sau khi mô hình đã được huấn luyện. |
| Cách tiếp cận | Giải thích ngay từ thiết kế mô hình | Giải thích sau khi huấn luyện |
| Mức độ phức tạp mô hình | Đơn giản, dễ hiểu | Phức tạp, khó hiểu (hộp đen) |
| Ví dụ mô hình | Linear regression, Decision Tree | CNN, XGBoost, Transformer |
| Độ chính xác | Thường thấp hơn | Thường cao hơn |
| Giải thích | Trực tiếp, chính xác | Gián tiếp, có thể xấp xỉ |
| Ứng dụng điển hình | Tài chính, y tế, chính phủ | Deep learning, recommendation, NLP |
Ví dụ: Tính khó giải thích của SVM với kernel phi tuyến
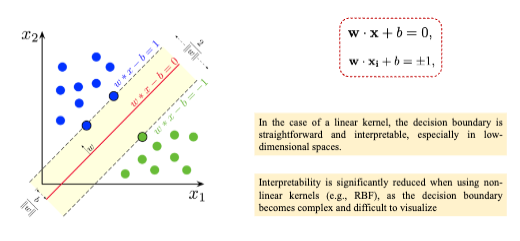 Với Linear SVM, biên quyết định là đường thẳng (hoặc mặt phẳng trong không gian cao hơn):
Với Linear SVM, biên quyết định là đường thẳng (hoặc mặt phẳng trong không gian cao hơn):
- Mỗi hệ số thể hiện mức độ ảnh hưởng của đặc trưng .
- Ta có thể vẽ trực tiếp ranh giới quyết định (decision boundary) như trong hình → dễ hiểu, minh bạch.
Khi dùng Radial Basis Function (RBF), dữ liệu được ánh xạ sang không gian đặc trưng có chiều rất cao (thậm chí vô hạn), ví dụ:
- Không còn vector trọng số dễ hiểu như trong SVM tuyến tính.
- Ranh giới phân tách không còn là đường thẳng mà có thể cong, uốn lượn, nhiều vùng nhỏ phức tạp.
- Khó xác định tại sao một điểm bị phân loại là “dương” hay “âm”, vì quyết định phụ thuộc vào khoảng cách phi tuyến giữa hàng trăm điểm support vectors.
1.4. The curse of dimensionality (lời nguyền của dữ liệu đa chiều)
Khái niệm này đã được nhắc đến ở bài KNN
Lời nguyền của tính đa chiều là tập hợp các vấn đề nảy sinh khi làm việc với dữ liệu có số lượng đặc trưng (features) rất lớn.
Khi số chiều tăng lên, không gian dữ liệu phình to một cách khủng khiếp, khiến dữ liệu trở nên thưa thớt (sparse), làm cho việc học, trực quan hóa và giải thích mô hình trở nên cực kỳ khó khăn.
| Số chiều | Hình dạng | Số điểm cần để phủ đều |
|---|---|---|
| 1 chiều | Đoạn thẳng | 10 điểm |
| 2 chiều | Hình vuông | (10^2 = 100) điểm |
| 3 chiều | Hình lập phương | (10^3 = 1{,}000) điểm |
Hệ quả: Dữ liệu thưa thớt (Data sparsity)
- Các điểm dữ liệu nằm xa nhau hơn, rất ít điểm “gần nhau”.
- Các thuật toán dựa trên khoảng cách như kNN, SVM (kernel RBF) hoạt động kém ổn định.
*Khoảng cách mất ý nghĩa Trong không gian nhiều chiều, khoảng cách giữa các điểm gần như tương đương nhau: → Rất khó định nghĩa “gần” hay “xa”.
Overfitting
- Mô hình dễ ghi nhớ dữ liệu huấn luyện vì mỗi điểm gần như “cô lập”.
- Hiệu năng tổng quát hóa (generalization) giảm mạnh.
Chi phí tính toán tăng vọt
- Càng nhiều đặc trưng → thời gian và bộ nhớ tăng theo cấp số mũ.
- Phải dùng các kỹ thuật giảm chiều (PCA, t-SNE, Autoencoder, v.v.).
Khó giải thích mô hình (Interpretability loss)
- Con người chỉ hình dung tốt trong 2D hoặc 3D.
- Khi lên đến hàng trăm chiều, không thể trực quan hóa ranh giới quyết định.
- Các phương pháp XAI như SHAP, PDP cũng kém đáng tin hơn vì các đặc trưng tương tác phức tạp.
Một ví dụ về Interpretability trong CNNs

2. Types of XAI
2. 1. Các giai đoạn của XAI
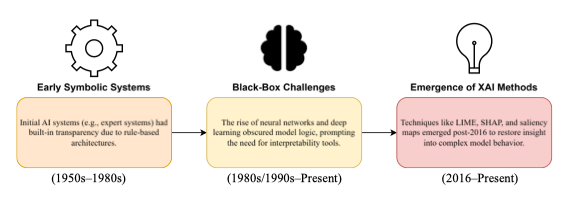
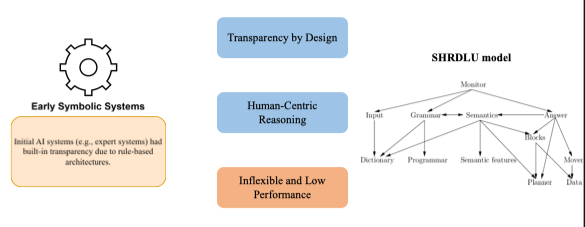
Early Symbolic Systems (1950s–1980s)
- Đây là thời kỳ đầu của trí tuệ nhân tạo, khi AI chủ yếu dựa trên logic, luật, và tri thức biểu tượng (symbolic AI).
- Các mô hình được viết dưới dạng tập luật Rule base “IF–THEN” hoặc cây quyết định, vì vậy:
- Con người dễ hiểu,
- Có thể truy xuất và kiểm chứng từng bước suy luận.
Black-Box Challenges (1980s/1990s–Present)
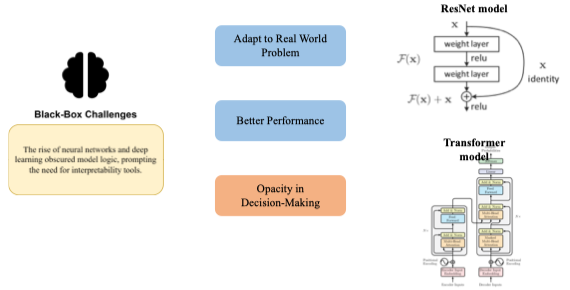
- Khi machine learning và đặc biệt là deep learning phát triển (như MLP, CNN, RNN), mô hình trở nên phi tuyến, nhiều tham số, nhiều tầng, nên:
- Không thể hiểu trực tiếp “mô hình học gì”.
- Ranh giới quyết định và trọng số mất ý nghĩa trực quan.
- Tính chính xác tăng mạnh, nhưng:
- Tính minh bạch giảm mạnh,
- Xuất hiện mối lo ngại về trust, bias, fairness, ethics. Ví dụ:
- Một mô hình CNN dự đoán “ảnh này là chó” → con người không biết vì sao mô hình nghĩ vậy (do tai, mắt, hay background?).
- Mô hình tín dụng từ chối khoản vay → không rõ lý do cụ thể.
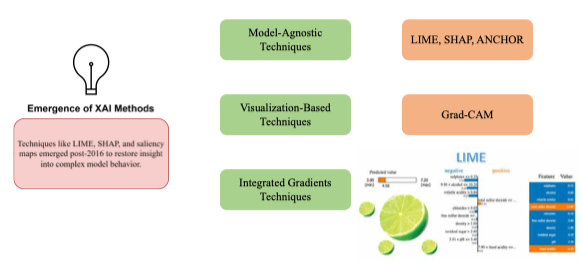
Emergence of XAI Methods (2016–Present)
- Bắt đầu từ khoảng năm 2016, các nhà nghiên cứu tập trung phát triển các công cụ hậu kỳ (post-hoc) để giải thích mô hình hộp đen
| Loại | Ví dụ | Giải thích |
|---|---|---|
| Local Explanation | LIME, SHAP | Giải thích từng dự đoán cụ thể |
| Visual Explanation | Grad-CAM, Saliency Map | Tô sáng vùng ảnh mà mô hình chú ý |
| Global Explanation | Feature importance, Partial Dependence Plot (PDP) | Giải thích toàn cục hành vi mô hình |
2.2. XAI Taxonomy
XAI (Explainable Artificial Intelligence) được chia thành hai nhánh lớn:
- Ante-hoc (Intrinsic / Interpretable-by-design)
- Post-hoc (After-training explanation)
.png)
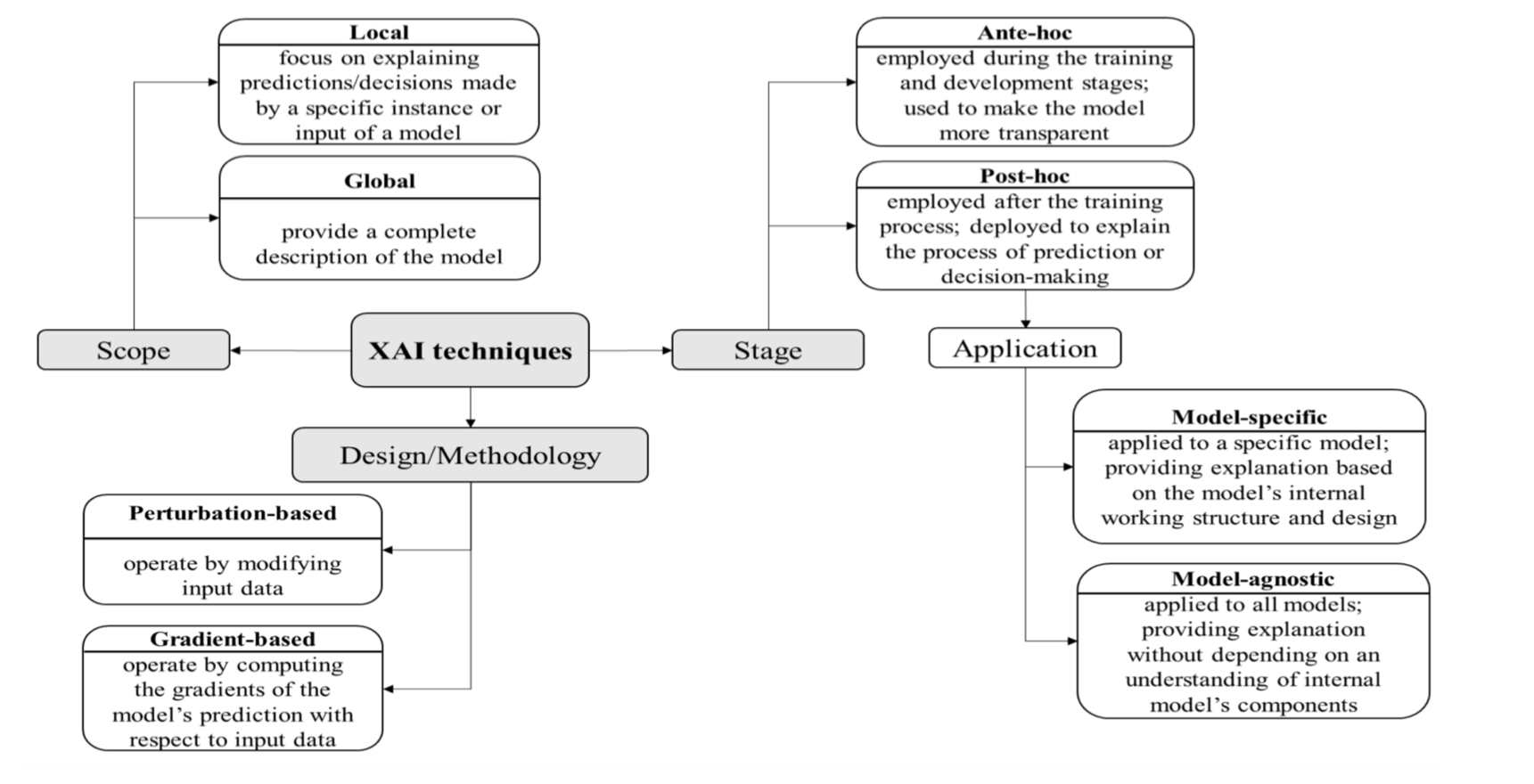
Scope (Phạm vi giải thích)
| Loại | Diễn giải |
|---|---|
| Local (Cục bộ) | Tập trung vào việc giải thích các dự đoán hoặc quyết định của mô hình đối với một mẫu cụ thể hoặc một đầu vào cụ thể. → Ví dụ: “Tại sao mô hình dự đoán rằng khách hàng này sẽ rời bỏ dịch vụ?” |
| Global (Toàn cục) | Cung cấp một mô tả tổng thể về toàn bộ mô hình, giúp hiểu cách mô hình ra quyết định trong toàn bộ tập dữ liệu. → Ví dụ: “Đặc trưng nào quan trọng nhất trong mọi dự đoán của mô hình?” |
| Stage (Giai đoạn áp dụng) |
| Loại | Diễn giải |
|---|---|
| Ante-hoc (Giải thích nội tại) | Được áp dụng ngay trong giai đoạn huấn luyện và phát triển mô hình, với mục tiêu làm cho mô hình trở nên minh bạch hơn từ đầu. → Ví dụ: Decision Tree, Linear Regression. |
| Post-hoc (Giải thích hậu kỳ) | Được áp dụng sau khi mô hình đã được huấn luyện, nhằm giải thích quá trình dự đoán hoặc ra quyết định của mô hình. → Ví dụ: LIME, SHAP, Grad-CAM. |
Application (Cách áp dụng vào mô hình)
| Loại | Diễn giải |
|---|---|
| Model-specific (Cụ thể theo mô hình) | Chỉ áp dụng cho một loại mô hình cụ thể, dựa trên cấu trúc nội bộ và cách hoạt động của mô hình đó. → Ví dụ: Grad-CAM cho CNN, Layer-wise Relevance Propagation cho mạng nơ-ron. |
| Model-agnostic (Độc lập mô hình) | Có thể áp dụng cho mọi loại mô hình, cung cấp giải thích mà không cần biết chi tiết cấu trúc nội bộ. → Ví dụ: LIME, SHAP, ANCHOR. |
Design / Methodology (Cách tiếp cận / Phương pháp thiết kế)
| Loại | Diễn giải |
|---|---|
| Perturbation-based (Dựa trên nhiễu/biến đổi) | Hoạt động bằng cách thay đổi đầu vào (thêm, xóa, hoặc làm nhiễu dữ liệu) để quan sát cách mô hình thay đổi kết quả. → Ví dụ: LIME, Occlusion Sensitivity. |
| Gradient-based (Dựa trên đạo hàm) | Hoạt động bằng cách tính gradient của đầu ra mô hình đối với đầu vào, để xác định yếu tố nào của đầu vào ảnh hưởng mạnh nhất đến dự đoán. → Ví dụ: Saliency Map, Grad-CAM. |
| Đây là so sánh giữa hai nhánh Ante-hoc và Post-hoc | |
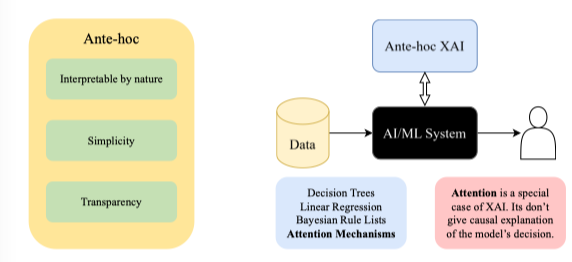 | |
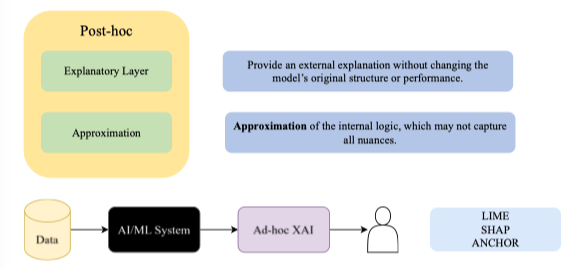 |
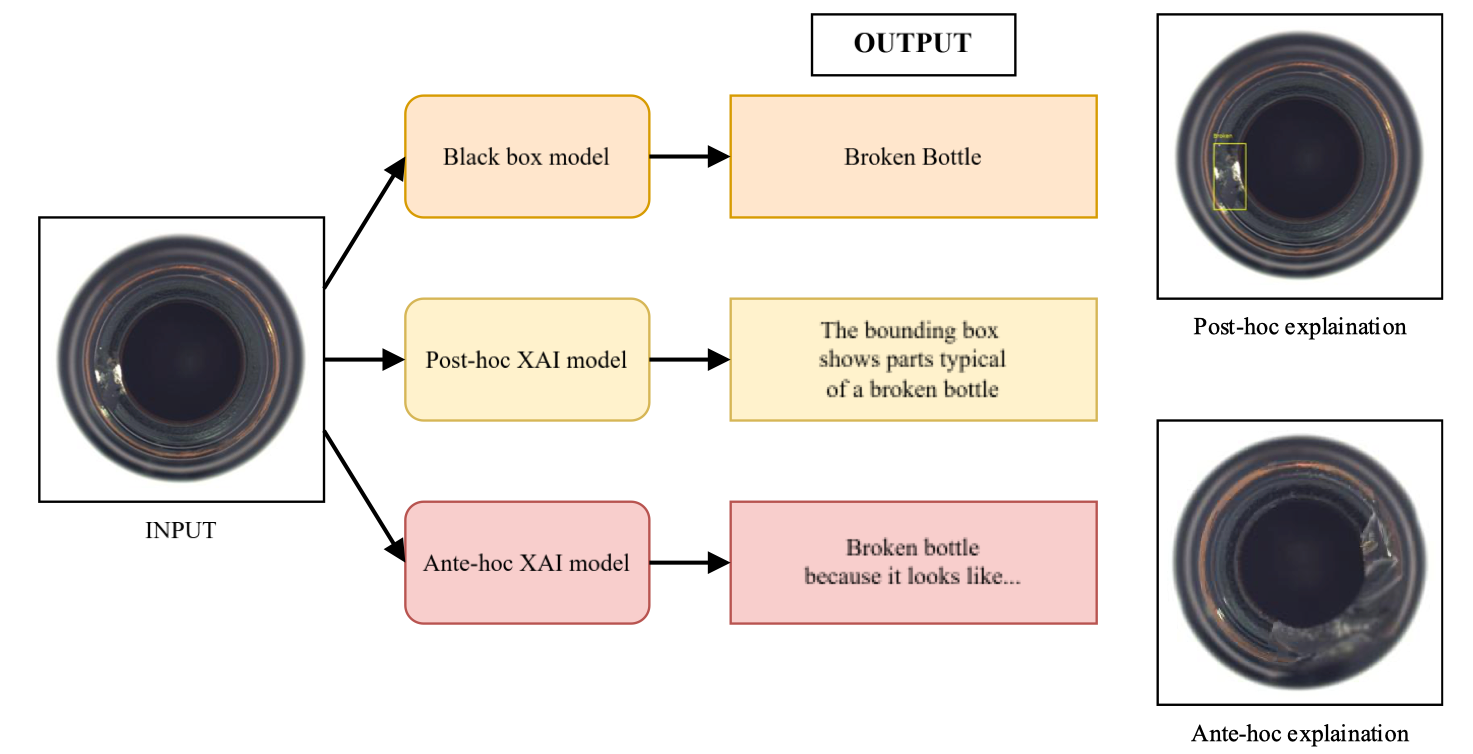
2.3. Attention as Explanation
Dùng cơ chế Attention để giải thích mô hình (thường trong NLP hoặc mô hình transformer).
Ví dụ:
Mô hình ở đây là một text classification model (mô hình phân loại cảm xúc của đánh giá phim).
Cụ thể:
- Đầu vào là một đoạn review tiêu cực.
- Đầu ra là xác suất thuộc lớp negative (tiêu cực).
- Cơ chế Attention được dùng để tô sáng (highlight) các từ mà mô hình “chú ý nhiều nhất”.
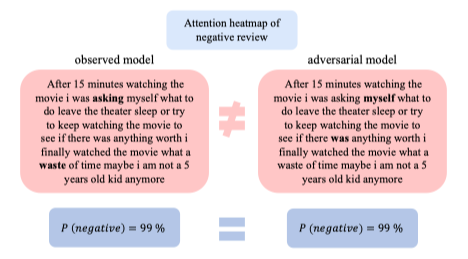
- Observed model (mô hình ban đầu)
- Adversarial model (mô hình bị tấn công) – cùng một đầu ra, nhưng được tinh chỉnh để “lừa” attention map.
P(negative) = 99% → Cả hai mô hình đều dự đoán chính xác là “tiêu cực”.
Nhưng khác nhau ở attention heatmap (vùng mô hình tập trung):
- Mô hình gốc tập trung vào các từ như:
“waste”, “time”, “asking” → hợp lý, vì đây là các từ mang cảm xúc tiêu cực. - Mô hình “adversarial” có attention khác hẳn, tập trung sai vị trí (nhưng vẫn ra cùng kết quả).
2.4. Model-Specific vs Model-Agnostic
Model-Specific XAI
Là các kỹ thuật chỉ áp dụng cho một loại mô hình cụ thể, dựa vào cấu trúc nội bộ của mô hình (kiến trúc, trọng số, gradient…).
- Tiếp cận trực tiếp vào bên trong mô hình: kiến trúc, trọng số, tín hiệu gradient.
- Giải thích được dựa trên cách mô hình thực sự học và xử lý dữ liệu
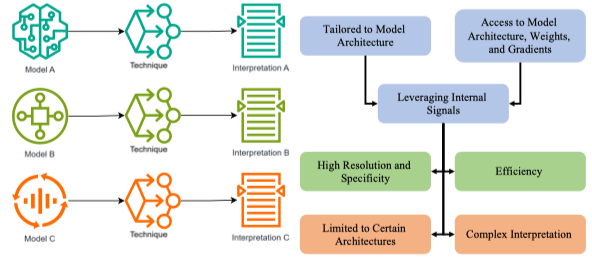
| Mô hình | Kỹ thuật giải thích | Mô tả |
|---|---|---|
| CNN | Grad-CAM, Layer-wise Relevance Propagation (LRP) | Tạo bản đồ nhiệt (heatmap) cho vùng ảnh mà mô hình “chú ý”. |
| Transformer / Attention model | Attention visualization | Hiển thị trọng số attention giữa các từ. |
| RNN / LSTM | Saliency Map theo thời gian | Phân tích đóng góp của từng bước thời gian. |
| Ưu điểm: |
- Độ chính xác cao, phản ánh đúng cách mô hình hoạt động thật.
- Chi tiết, có độ phân giải cao (high resolution & specificity).
- Hiệu quả hơn do tận dụng trực tiếp tín hiệu nội bộ. Nhược điểm:
- Giới hạn phạm vi – chỉ dùng cho mô hình phù hợp.
- Phức tạp khi diễn giải – yêu cầu hiểu sâu về cấu trúc mô hình.
Model-Agnostic
Là các kỹ thuật không phụ thuộc vào loại mô hình – có thể dùng cho bất kỳ mô hình nào (từ logistic regression đến deep learning).
Giải thích dựa trên mối quan hệ giữa đầu vào (input) và đầu ra (output), chứ không cần truy cập vào nội bộ mô hình.
- Thường dựa vào perturbation-based analysis – thay đổi đầu vào để quan sát đầu ra.
- Xấp xỉ hành vi của mô hình bằng một mô hình dễ hiểu hơn (ví dụ: tuyến tính hoặc cây quyết định).
| Kỹ thuật | Mô tả | Ứng dụng |
|---|---|---|
| LIME | Xấp xỉ mô hình phức tạp quanh 1 điểm bằng mô hình tuyến tính đơn giản. | Giải thích dự đoán cục bộ. |
| SHAP | Đánh giá đóng góp của từng đặc trưng vào kết quả dự đoán. | Phân tích toàn cục & cục bộ. |
| ANCHOR | Tạo quy tắc “if–then” để mô tả vùng quyết định của mô hình. | NLP, tabular, hình ảnh. |
Ưu điểm:
- Đa năng (versatile) – áp dụng được cho mọi mô hình.
- Thân thiện với người dùng (user-friendly) – dễ trình bày, dễ hiểu Nhược điểm:
- Tốn tài nguyên tính toán (computational cost) – do phải thử nhiều lần để tạo perturbation.
- Chỉ là xấp xỉ (approximation quality) – không phản ánh chính xác cơ chế nội bộ thật.
2.5. Global Explanations vs Local Explanations
Global Explanations
Global explanation là cách giải thích mô hình ở cấp độ tổng thể,
tức là mô tả cách toàn bộ mô hình hoạt động trên toàn bộ tập dữ liệu.
→ Giúp trả lời câu hỏi:
“Mô hình nhìn chung học được điều gì?” hoặc
“Những yếu tố nào ảnh hưởng nhiều nhất đến quyết định tổng thể?”
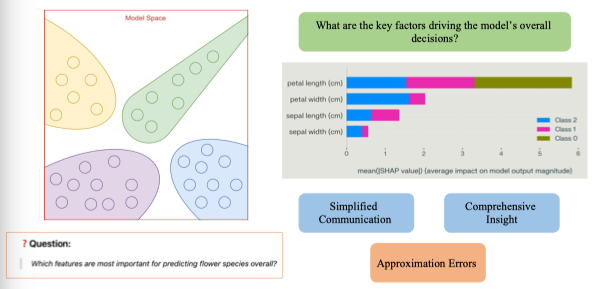 Đặc điểm chính
Đặc điểm chính
- Xem xét toàn bộ không gian dữ liệu.
- Cung cấp cái nhìn tổng quan, khái quát về hành vi mô hình.
- Thường sử dụng các kỹ thuật tổng hợp thống kê hoặc biểu đồ phụ thuộc toàn cục.
Ví dụ
| Kỹ thuật | Mô tả |
|---|---|
| Feature Importance (tầm quan trọng đặc trưng) | Cho biết đặc trưng nào ảnh hưởng mạnh nhất đến đầu ra. |
| Partial Dependence Plot (PDP) | Hiển thị cách giá trị của một đặc trưng thay đổi ảnh hưởng đến dự đoán trung bình. |
| Global Surrogate Model | Xây một mô hình đơn giản (ví dụ: cây quyết định) để xấp xỉ mô hình gốc. |
Ứng dụng
- Đánh giá mức độ công bằng của mô hình.
- Hiểu hành vi tổng thể khi triển khai (ví dụ: mô hình có thiên vị giới tính không?).
- Hữu ích cho quản lý rủi ro và tuân thủ pháp lý.
Local Explanations (Giải thích cục bộ)
Local explanation tập trung giải thích quyết định của mô hình cho một trường hợp cụ thể (một mẫu, một dự đoán duy nhất).
→ Giúp trả lời câu hỏi:
“Tại sao mô hình lại đưa ra kết quả này cho dữ liệu này?”
Đặc điểm chính
- Chỉ xem xét một điểm dữ liệu cụ thể.
- Giải thích cách các đặc trưng của điểm đó ảnh hưởng đến kết quả dự đoán.
- Cho biết đóng góp dương/âm của từng đặc trưng trong quyết định cụ thể.
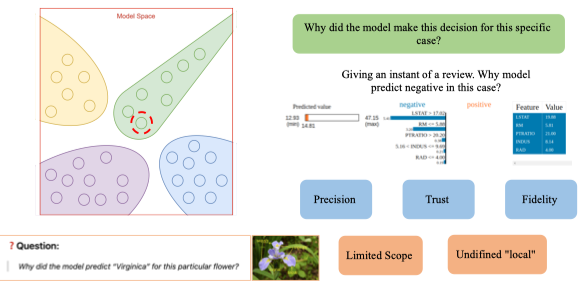
Ví dụ
| Kỹ thuật | Mô tả |
|---|---|
| LIME (Local Interpretable Model-agnostic Explanations) | Xấp xỉ mô hình gốc quanh điểm cần giải thích bằng một mô hình tuyến tính đơn giản. |
| SHAP (SHapley Additive exPlanations) | Đo lường đóng góp của từng đặc trưng cho một dự đoán cụ thể, dựa trên lý thuyết trò chơi Shapley. |
| Counterfactual Explanation | Tìm “điều gì cần thay đổi” trong đầu vào để kết quả dự đoán thay đổi (ví dụ: tăng lương bao nhiêu để được duyệt khoản vay). |
Ứng dụng
- Giải thích quyết định cho một cá nhân cụ thể (ví dụ: khách hàng bị từ chối vay).
- Hỗ trợ tương tác người dùng – AI (ví dụ: chatbot y tế, gợi ý sản phẩm).
- Giúp debug mô hình khi kết quả bất thường.
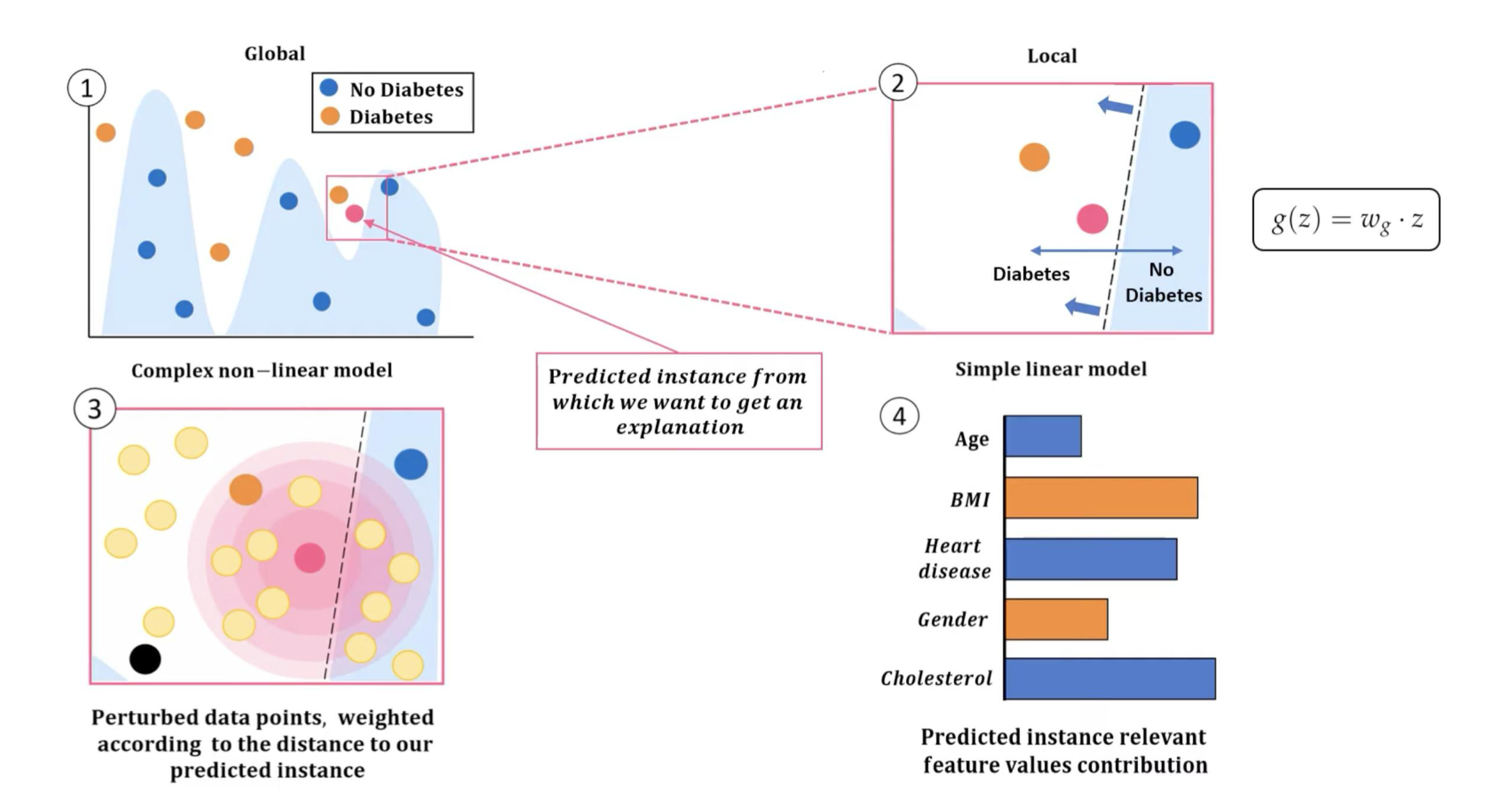
3. LIME for AI Explainable
LIME local explaination
Mỗi “Case” (1, 2, 3, 4, 5) là một khách hàng riêng biệt trong tập dữ liệu.
Mô hình dự đoán liệu người đó sẽ nghỉ việc hay không (Attrition = Yes/No).
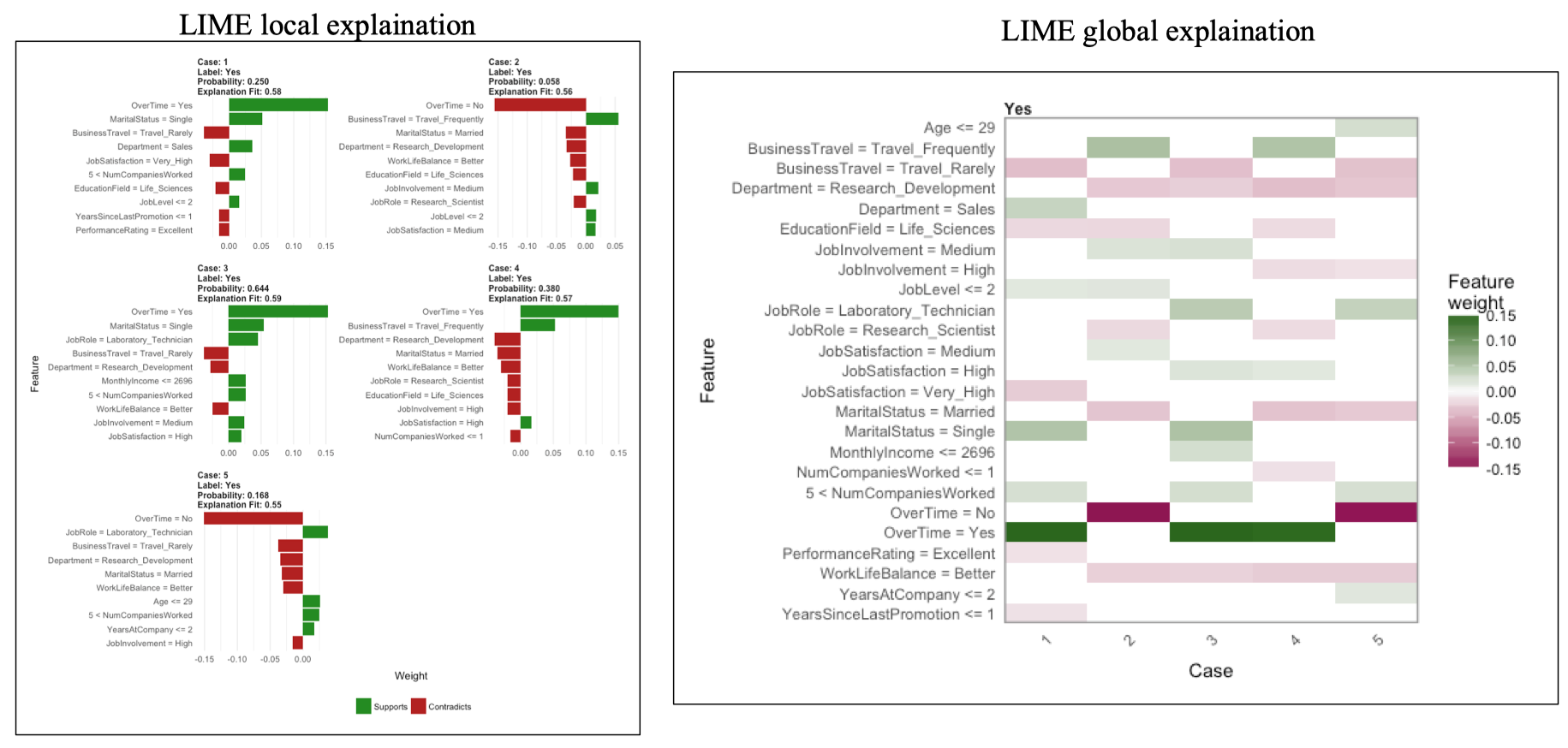
| Case | Dự đoán | Xác suất | Giải thích |
|---|---|---|---|
| Case 1 | Yes (nghỉ việc) | 25.0% | Các yếu tố OverTime = Yes, MaritalStatus = Single góp phần tăng xác suất nghỉ việc. |
| Case 2 | Yes | 5.8% | Các yếu tố OverTime = No, Married góp phần giảm xác suất nghỉ việc. |
| Case 3–5 | Yes | 16–64% | Các yếu tố như JobRole, Department, BusinessTravel, WorkLifeBalance, … ảnh hưởng riêng biệt cho từng người. |
| LIME global explanation | |||
| Tổng hợp tất cả Local Explanations để xem toàn bộ mô hình hoạt động thế nào. |
Khi ta gom nhiều Local Explanations → sẽ tạo ra Global View của mô hình:
“Mô hình nhìn chung đang tập trung vào những yếu tố nào nhiều nhất?”
-
Trục dọc (Feature): các đặc trưng (Age, OverTime, Department, JobRole, …).
-
Trục ngang (Case): từng cá nhân được giải thích (Case 1 → Case 5).
-
Màu:
- Xanh lá: đặc trưng làm tăng xác suất nghỉ việc.
- Đỏ hồng: đặc trưng làm giảm xác suất nghỉ việc.
- Trắng: không ảnh hưởng đáng kể.
-
Đặc trưng OverTime = Yes → thường có màu xanh đậm → tăng khả năng nghỉ việc (một yếu tố tiêu cực).
-
WorkLifeBalance = Better hoặc JobSatisfaction = High → màu đỏ → giảm khả năng nghỉ việc.
-
BusinessTravel = Frequent cũng có xu hướng màu xanh → có thể làm tăng stress, dẫn đến nghỉ việc.
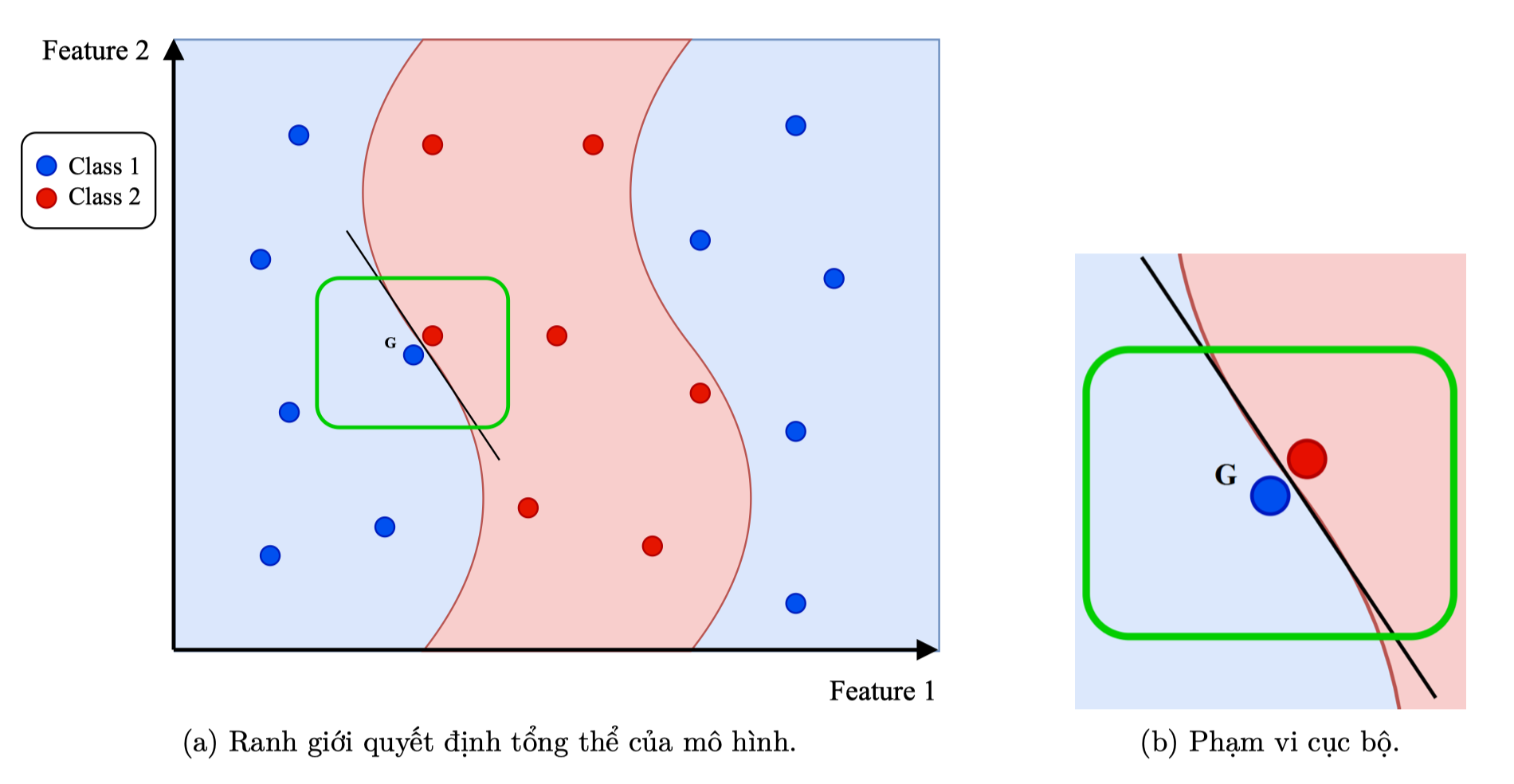
3.1. Ý tưởng
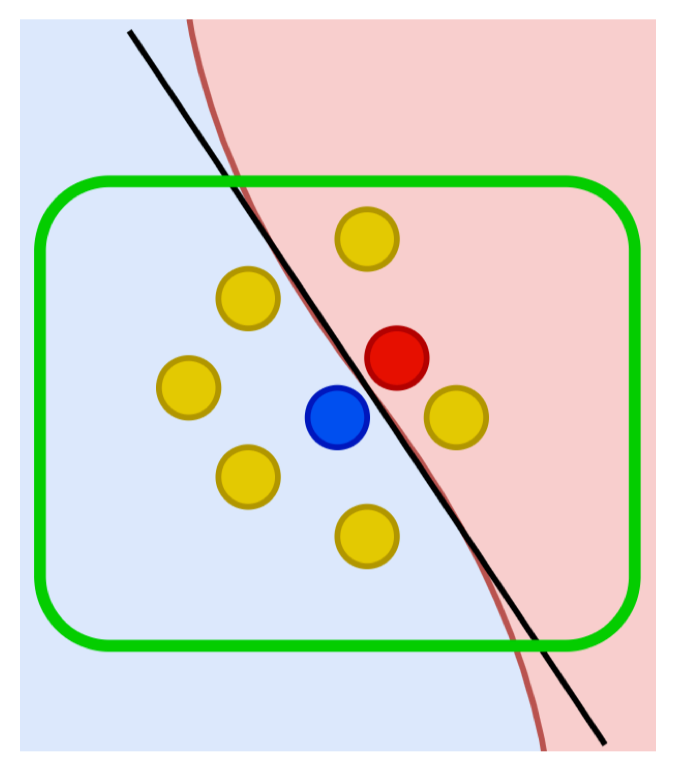
- Mô hình gốc (black-box) có ranh giới quyết định rất phức tạp, khó giải thích trên toàn bộ dữ liệu.
- Tuy nhiên, nếu chỉ xét một vùng nhỏ quanh một điểm dữ liệu cụ thể (G), thì ranh giới ở khu vực đó có thể được xấp xỉ bằng một mô hình đơn giản – ví dụ như một đường thẳng.
- LIME tận dụng ý tưởng này:
Giải thích mô hình phức tạp bằng cách huấn luyện một mô hình tuyến tính đơn giản quanh điểm cần giải thích để mô phỏng hành vi cục bộ của mô hình gốc.
3.1. Cơ chế hoạt động
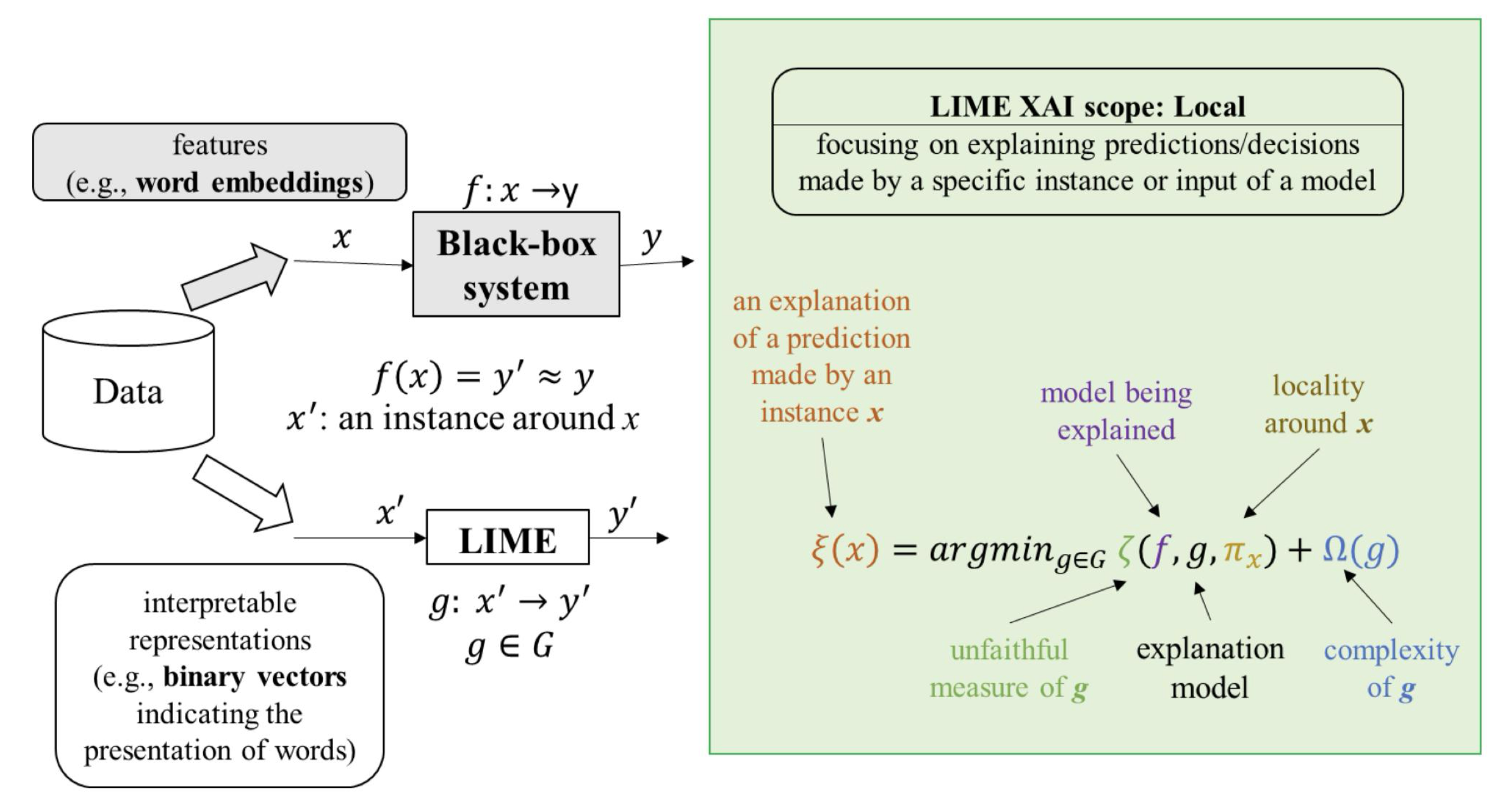
Để giải thích dự đoán của mô hình tại một điểm Local, ta xây dựng LIME như sau:
-
Tạo dữ liệu lân cận (Perturbation): Sinh ra các điểm dữ liệu mới xung quanh điểm dữ liệu cần giải thích bằng cách thay đổi (ví dụ như thêm nhiễu, hoán vị, …) các giá trị đặc trưng của điểm dữ liệu gốc.
-
Dự đoán bằng mô hình gốc (Make Prediction): Sử dụng mô hình phức tạp ban đầu để dự đoán nhãn cho các điểm dữ liệu giả đã tạo.
-
Tính khoảng cách và trọng số (Calculate Distance and Weights): Đo khoảng cách giữa mỗi điểm dữ liệu giả và điểm gốc để sử dụng làm trọng số trong bước tiếp theo. Điểm càng gần điểm gốc sẽ có trọng số càng cao.
-
Chọn các đặc trưng quan trọng (Select Features): Lựa chọn một tập hợp nhỏ các đặc trưng (thường ký hiệu là m) có ảnh hưởng lớn nhất đến kết quả dự đoán của mô hình phức tạp. Việc giảm số lượng đặc trưng giúp đơn giản hóa mô hình giải thích và tập trung vào những yếu tố quan trọng nhất.
-
Huấn luyện mô hình đơn giản (Fit Simple Model): Sử dụng các mẫu dữ liệu giả đã tạo ra với các đặc trưng đã chọn và nhãn từ mô hình gốc dự đoán để huấn luyện một mô hình đơn giản. Mô hình này sẽ xấp xỉ hành vi của mô hình phức tạp trong vùng lân cận của điểm dữ liệu gốc.
-
Giải thích kết quả (Interpretation): Phân tích các hệ số của mô hình đơn giản để hiểu ảnh hưởng của từng đặc trưng đến dự đoán của mô hình phức tạp tại điểm dữ liệu đang xét.
4. LIME: Example
4.1. LIME cho dữ liệu ảnh
Để hiểu rõ hơn về thuật toán LIME, hãy cùng xem xét một ví dụ minh họa từng bước, trong đó LIME được sử dụng để giải thích cách mô hình ResNet 50 đã được huấn luyện trước (pre-trained) dự đoán nhãn của một bức ảnh con ếch.
Bước 1: Tạo mẫu dữ liệu lân cận
Đầu tiên ta sẽ chia bức ảnh gốc thành các thành phần nhỏ đồng nhất về màu sắc, texture, … Gọi là superpixel hay segmentation. Mỗi superpixel có thể xem là một đơn vị đặc trưng trong mô hình giải thích.

Ở đây sẽ giới thiệu sơ qua về kĩ thuật segmentation trong xử lý ảnh:
Segmentation
Segmentation (phân đoạn ảnh) là quá trình chia nhỏ một bức ảnh thành các vùng (segments).
Semantic Segmentation (Phân đoạn ngữ nghĩa)
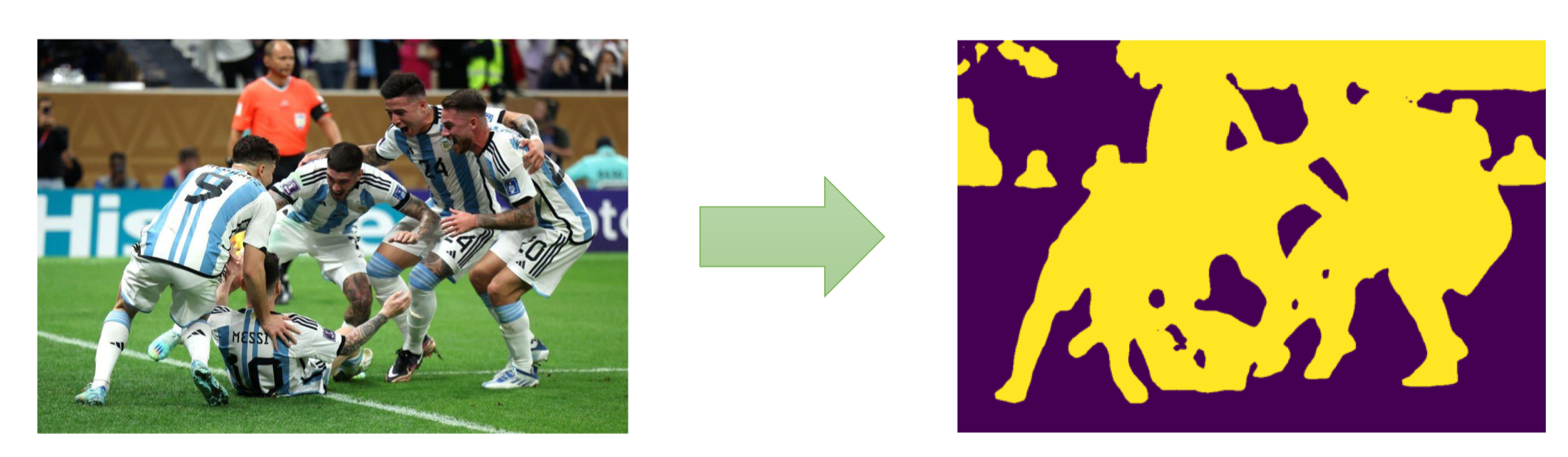
- Mỗi pixel được gán nhãn lớp (class label) tương ứng.
- Không phân biệt các đối tượng cùng loại — ví dụ: tất cả các chiếc xe đều cùng một nhãn “car”.
Instance Segmentation (Phân đoạn thực thể)

- Giống semantic segmentation, nhưng phân biệt từng cá thể riêng biệt.
→ Mỗi chiếc xe, mỗi người có vùng mask riêng, dù cùng loại “car” hoặc “person”.

Mỗi bức ảnh được biểu diễn bằng một vector nhị phân có số chiều tương ứng với số lượng superpixel trong ảnh. Trong vector này, mỗi phần tử nhận giá trị 1 hoặc 0, lần lượt biểu thị việc giữ lại hoặc loại bỏ superpixel tương ứng.
Theo đó, vector của ảnh gốc được biểu diễn là , vì ảnh bao gồm đầy đủ 4 superpixel.
Từ cách biểu diễn này, ta có thể tạo ra các mẫu dữ liệu mới bằng cách lần lượt giữ lại hoặc loại bỏ từng superpixel, qua đó thu được tổng cộng ảnh.
Bước 2: Dự đoán nhãn bằng mô hình gốc
Sử dụng mô hình ResNet 50, ta thực hiện dự đoán lớp cho 16 ảnh và thu được xác suất thuộc lớp “tailed frog” (lớp cần giải thích quyết định của mô hình) đối với mỗi ảnh.

Bước 3: Tính khoảng cách và trọng số
Khoảng cách giữa mỗi mẫu và mẫu gốc được tính dựa trên cosine similarity theo công thức:
Ví dụ, với , ta có:
Để chuyển khoảng cách này thành trọng số, ta sử dụng hàm kernel mũ:
Trong đó, là tham số kernel width (mặc định ).
Ví dụ, với và :
Giá trị được lựa chọn để đảm bảo rằng những ảnh khác biệt nhiều so với ảnh gốc sẽ có trọng số nhỏ hơn (tiệm cận về 0).
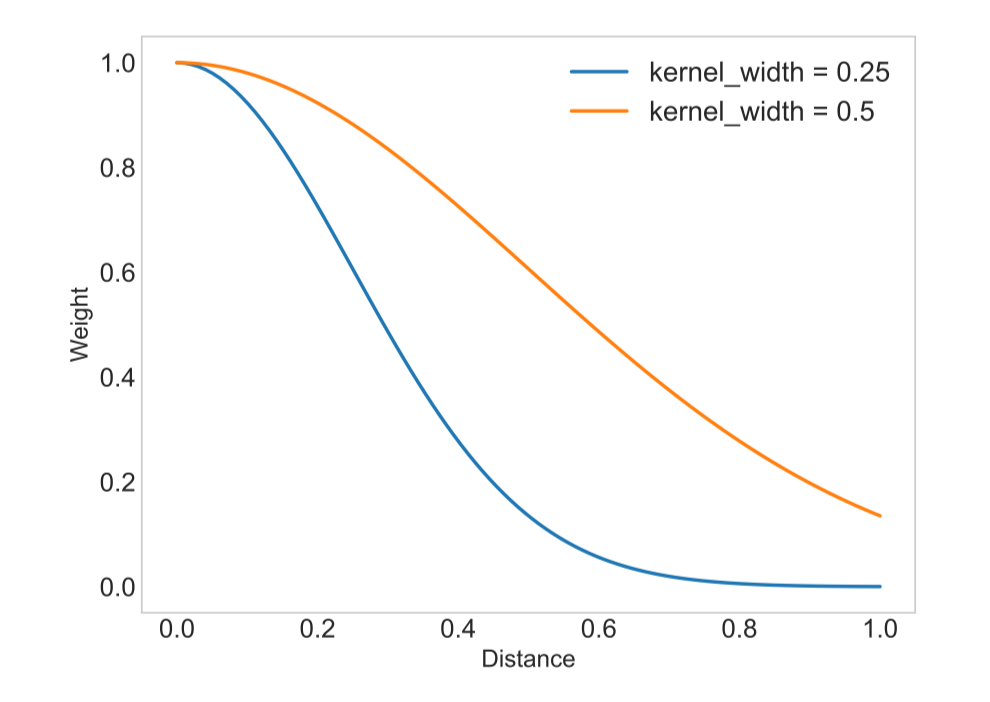
Note
Như hình ta thấy khi setting kernel_width là 0.5 thì tương quan giữa khoảng cách và trọng số gần như là tuyến tính (Khoảng cách là 0.8 thì weight gần 0.2) trong khi đó khi setting kernel_width là 0.25 thì sẽ trừng phạt cách sample có distance xa (0.8 sẽ có weight gần bằng 0)
Tương tự ta tính cho các ảnh còn lại:
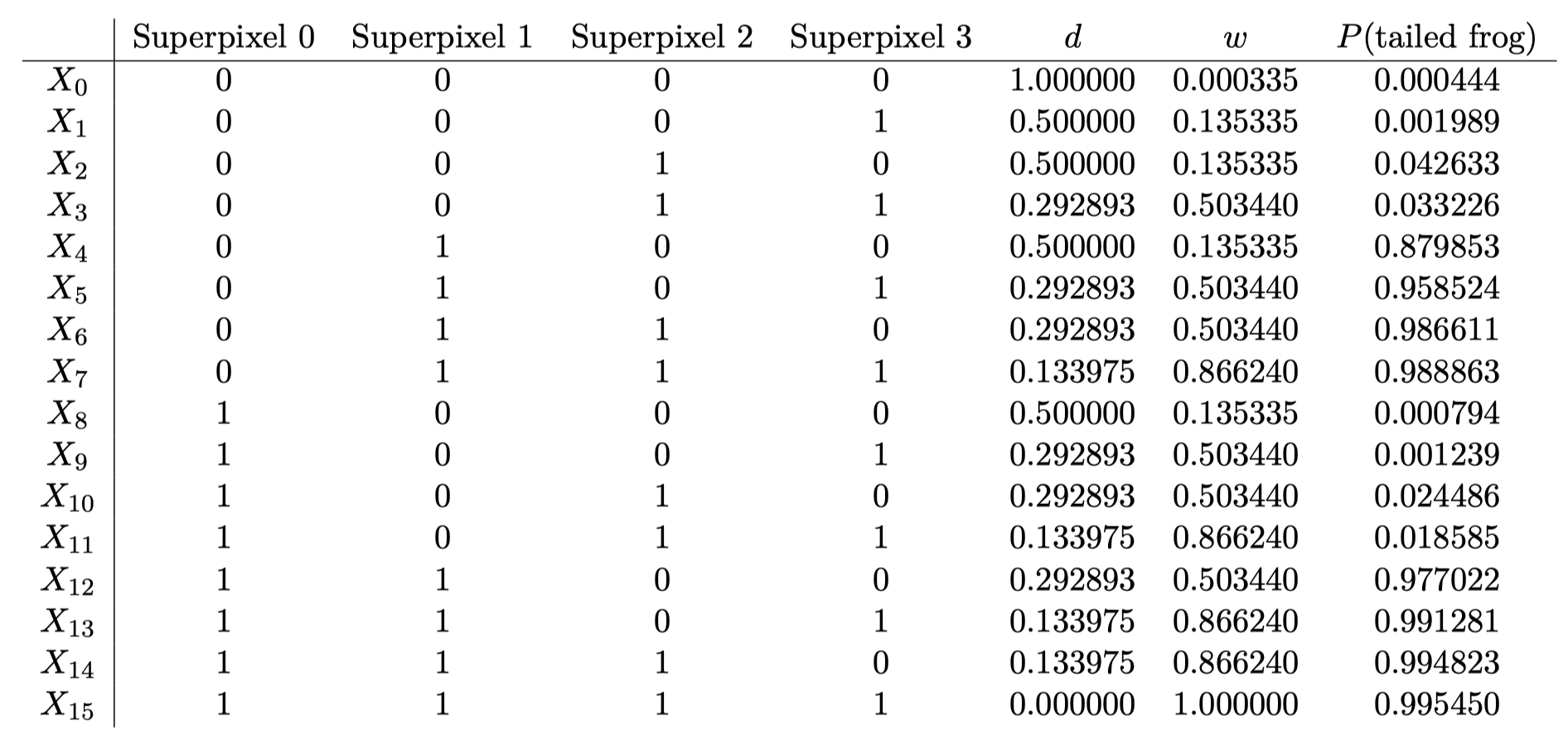
Bước 4: Chọn các đặc trưng quan trọng
Trong bước ban đầu, ảnh được biểu diễn dưới dạng 4 đặc trưng đại diện cho 4 superpixel. Ở ví dụ này, chúng ta sẽ chọn ra 1 đặc trưng quan trọng nhất, ứng với 1 superpixel có ảnh hưởng lớn nhất đến quyết định của mô hình cho bước giải thích phía sau. →
Bước 5: Huấn luyện mô hình đơn giản
Ta tiến hành huấn luyện một mô hình hồi quy tuyến tính với đầu vào là các vector nhị phân biểu diễn các mẫu ảnh, đầu ra là xác suất dự đoán thuộc lớp “tailed frog” và sử dụng trọng số đã tính ở bước trước.

Bước 6: Giải thích kết quả
Sau quá trình huấn luyện, các hệ số hồi quy thu được của mô hình sẽ thể hiện với mức độ quan trọng của superpixel tương ứng. Lưu ý rằng hệ số âm không nhất thiết biểu thị superpixel đó ảnh hưởng tiêu cực đến dự đoán của mô hình; trong bối cảnh giải thích, các superpixel có hệ số âm được xem là ít quan trọng hơn.
Như ta thấy hình dưới có hệ số hồi quy cao nhất đồng nghĩa với việc nó tác động nhiều nhất đến quyết định của mô hình. Điều này chứng tỏ LIME đã xác định hiệu quả vùng ảnh có ảnh hưởng lớn nhất đến kết quả phân loại.
.png)